MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
作者: Changle Qu, Sunhao Dai, Hengyi Cai, Jun Xu, Shuaiqiang Wang, Dawei Yin
分类: cs.CL, cs.AI
发布日期: 2026-01-15
🔗 代码/项目: GITHUB
💡 一句话要点
MatchTIR:通过二分图匹配实现工具集成推理的细粒度监督
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具集成推理 强化学习 二分图匹配 信用分配 细粒度监督
📋 核心要点
- 现有工具集成推理方法在长程多轮任务中,无法有效区分有效和无效的工具调用,导致信用分配不准确。
- MatchTIR 提出基于二分图匹配的回合级别奖励分配,并结合双级别优势估计,实现细粒度的监督学习。
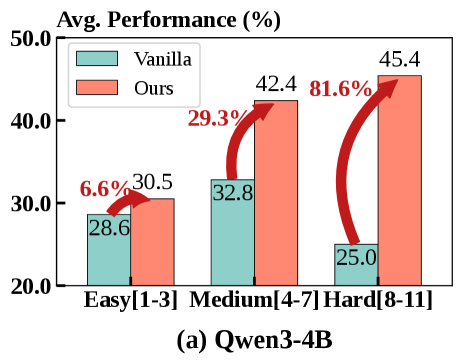
- 实验表明,MatchTIR 在多个基准测试中表现优异,甚至超越了更大规模的模型,尤其是在长程多轮任务上。
📝 摘要(中文)
工具集成推理(TIR)通过将推理步骤与外部工具交互相结合,使大型语言模型(LLM)能够处理复杂的任务。然而,现有的强化学习方法通常依赖于结果或轨迹级别的奖励,对轨迹内的所有步骤分配统一的优势。这种粗粒度的信用分配无法区分有效的工具调用和冗余或错误的工具调用,尤其是在长程多轮场景中。为了解决这个问题,我们提出了MatchTIR,一个通过基于二分图匹配的回合级别奖励分配和双级别优势估计来引入细粒度监督的框架。具体来说,我们将信用分配建模为预测轨迹和真实轨迹之间的二分图匹配问题,利用两种分配策略来获得密集的 turn-level 奖励。此外,为了平衡局部步骤精度与全局任务成功,我们引入了一种双级别优势估计方案,该方案集成了 turn-level 和 trajectory-level 信号,为单个交互回合分配不同的优势值。在三个基准上的大量实验证明了MatchTIR的优越性。值得注意的是,我们的4B模型超过了大多数8B竞争对手,尤其是在长程和多轮任务中。
🔬 方法详解
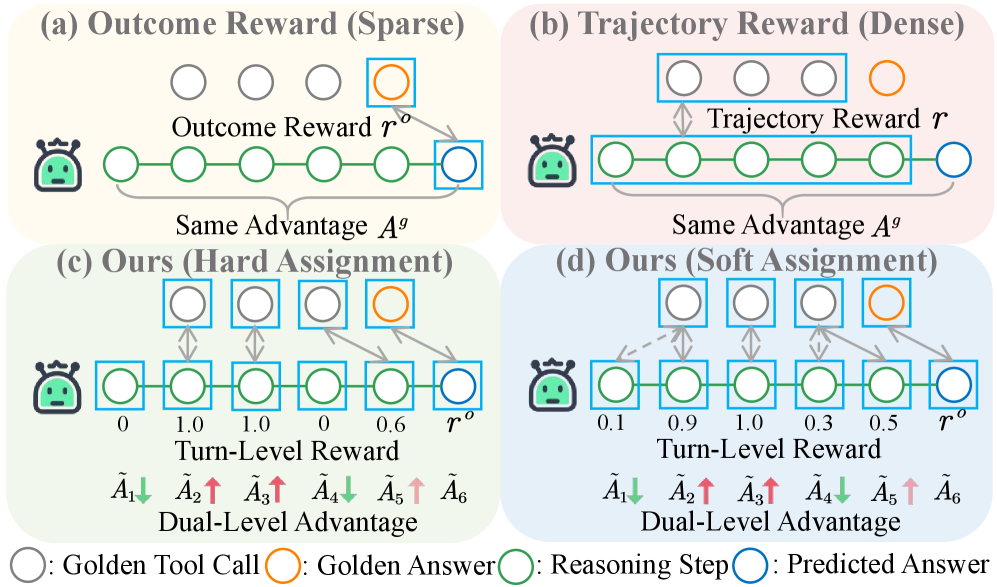
问题定义:现有工具集成推理方法在训练大型语言模型时,通常采用强化学习,但其奖励信号是稀疏的,通常只在轨迹结束时给出。这导致难以区分轨迹中哪些工具调用是有效的,哪些是冗余甚至错误的,尤其是在长程、多轮交互的复杂任务中。这种粗粒度的信用分配阻碍了模型学习最佳策略。
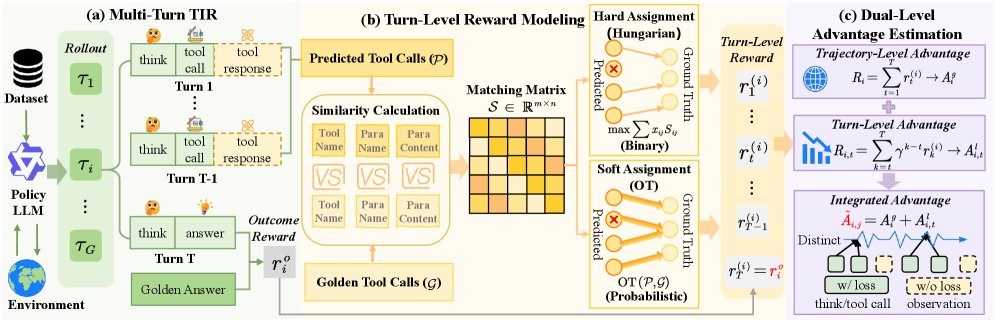
核心思路:MatchTIR的核心思路是将信用分配问题转化为一个二分图匹配问题。具体来说,将模型预测的工具调用序列和真实的工具调用序列进行匹配,通过匹配程度来确定每个工具调用的价值,从而实现细粒度的奖励分配。同时,结合回合级别和轨迹级别的奖励信号,平衡局部步骤的准确性和全局任务的成功。
技术框架:MatchTIR框架主要包含以下几个模块:1) 轨迹生成模块:使用LLM生成工具调用序列。2) 二分图匹配模块:将生成的轨迹与真实轨迹进行匹配,计算回合级别的奖励。3) 双级别优势估计模块:结合回合级别和轨迹级别的奖励,计算每个工具调用的优势值。4) 策略优化模块:使用强化学习算法,根据优势值更新LLM的策略。
关键创新:MatchTIR的关键创新在于:1) 提出了基于二分图匹配的细粒度奖励分配方法,能够更准确地评估每个工具调用的价值。2) 提出了双级别优势估计方案,平衡了局部步骤的准确性和全局任务的成功。3) 将信用分配问题建模为二分图匹配问题,为解决类似问题提供了一种新的思路。
关键设计:在二分图匹配模块中,论文提出了两种匹配策略,用于计算预测轨迹和真实轨迹之间的相似度。在双级别优势估计模块中,论文设计了一个加权平均的方案,将回合级别的奖励和轨迹级别的奖励进行融合。具体权重的选择需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MatchTIR 在三个基准测试中均取得了显著的性能提升。例如,在某些长程多轮任务中,使用 MatchTIR 训练的 4B 模型甚至超越了未采用 MatchTIR 训练的 8B 模型。这表明 MatchTIR 能够更有效地利用数据,提升模型的学习效率和泛化能力。
🎯 应用场景
MatchTIR 有潜力应用于各种需要工具集成推理的场景,例如智能客服、自动化报告生成、科学研究辅助等。通过更有效地利用外部工具,可以显著提升LLM在复杂任务中的表现,并降低对模型规模的依赖。该研究为开发更智能、更可靠的AI系统奠定了基础。
📄 摘要(原文)
Tool-Integrated Reasoning (TIR) empowers large language models (LLMs) to tackle complex tasks by interleaving reasoning steps with external tool interactions. However, existing reinforcement learning methods typically rely on outcome- or trajectory-level rewards, assigning uniform advantages to all steps within a trajectory. This coarse-grained credit assignment fails to distinguish effective tool calls from redundant or erroneous ones, particularly in long-horizon multi-turn scenarios. To address this, we propose MatchTIR, a framework that introduces fine-grained supervision via bipartite matching-based turn-level reward assignment and dual-level advantage estimation. Specifically, we formulate credit assignment as a bipartite matching problem between predicted and ground-truth traces, utilizing two assignment strategies to derive dense turn-level rewards. Furthermore, to balance local step precision with global task success, we introduce a dual-level advantage estimation scheme that integrates turn-level and trajectory-level signals, assigning distinct advantage values to individual interaction turns. Extensive experiments on three benchmarks demonstrate the superiority of MatchTIR. Notably, our 4B model surpasses the majority of 8B competitors, particularly in long-horizon and multi-turn tasks. Our codes are available at https://github.com/quchangle1/MatchTIR.