Detecting Winning Arguments with Large Language Models and Persuasion Strategies
作者: Tiziano Labruna, Arkadiusz Modzelewski, Giorgio Satta, Giovanni Da San Martino
分类: cs.CL
发布日期: 2026-01-15
💡 一句话要点
利用大型语言模型和说服策略检测论辩文本中的胜方
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 说服力检测 论辩分析 策略推理 自然语言处理
📋 核心要点
- 现有方法在检测论辩文本的说服力方面存在挑战,难以有效利用说服策略。
- 论文提出一种多策略说服力评分方法,利用大型语言模型指导对多种说服策略的推理。
- 实验结果表明,该方法在多个数据集上提高了说服力预测的准确性,并增强了模型的可解释性。
📝 摘要(中文)
检测论辩文本中的说服力是一项具有挑战性的任务,对于理解人类交流具有重要意义。本文研究了说服策略(如人身攻击、转移注意力和操纵性措辞)在决定文本说服力方面的作用。我们在三个带注释的论辩数据集上进行了实验:Winning Arguments(来自Change My View subreddit)、Anthropic/Persuasion和Persuasion for Good。我们的方法利用大型语言模型(LLM)和多策略说服力评分方法,指导对六种说服策略的推理。结果表明,策略引导的推理提高了说服力的预测。为了更好地理解内容的影响,我们将Winning Argument数据集组织成广泛的讨论主题,并分析了它们之间的性能。我们公开发布这个带有主题注释的数据集,以促进未来的研究。总的来说,我们的方法论证明了结构化的、策略感知的提示对于提高论证质量评估的可解释性和鲁棒性的价值。
🔬 方法详解
问题定义:论文旨在解决如何更准确地检测论辩文本中的说服力,并理解不同说服策略在其中的作用。现有方法难以有效利用文本中蕴含的说服策略信息,导致说服力判断的准确性和可解释性不足。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大推理能力,结合预定义的说服策略,引导模型进行策略感知的推理。通过显式地考虑不同的说服策略,模型可以更好地理解论辩文本的内在逻辑和说服机制,从而提高说服力判断的准确性。
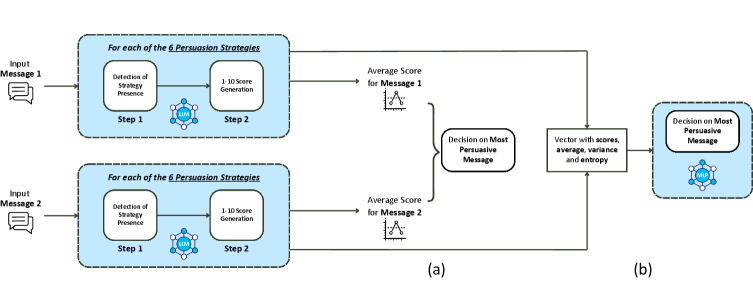
技术框架:整体框架包含以下几个主要步骤:1) 数据集构建与标注:使用三个公开数据集,并对Winning Arguments数据集进行主题标注。2) 说服策略定义:定义六种说服策略,例如人身攻击、转移注意力等。3) 多策略说服力评分:利用LLM,通过策略感知的提示,对每个论辩文本进行说服力评分。4) 模型训练与评估:使用评分结果训练模型,并在测试集上评估模型的性能。
关键创新:论文的关键创新在于提出了策略感知的提示方法,将预定义的说服策略融入到LLM的推理过程中。这种方法使得模型能够更加关注文本中与说服策略相关的信息,从而提高说服力判断的准确性和可解释性。与现有方法相比,该方法能够更好地利用文本中蕴含的结构化信息。
关键设计:论文的关键设计包括:1) 六种说服策略的定义,这些策略涵盖了常见的论辩技巧。2) 策略感知的提示模板,用于引导LLM进行策略推理。3) 使用评分结果训练模型的具体方法,例如损失函数的选择等。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
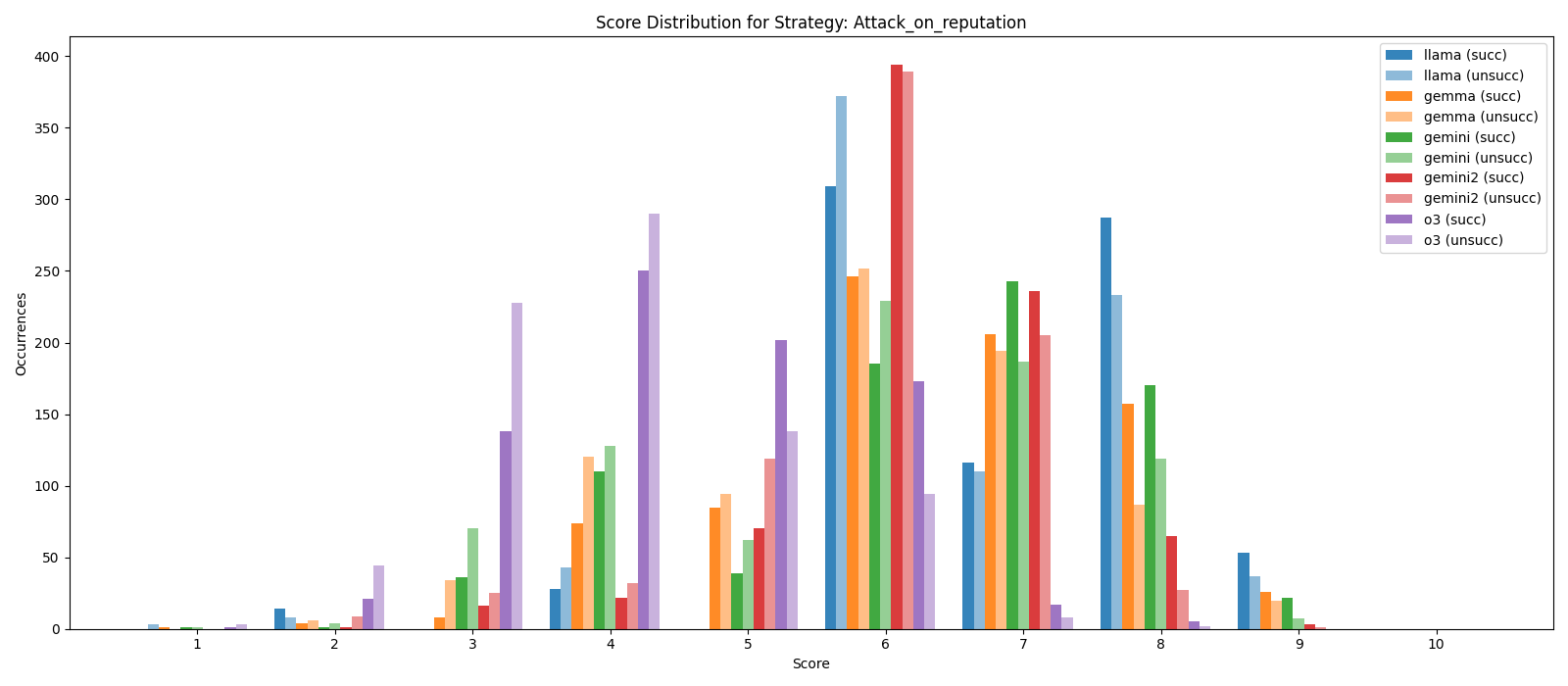
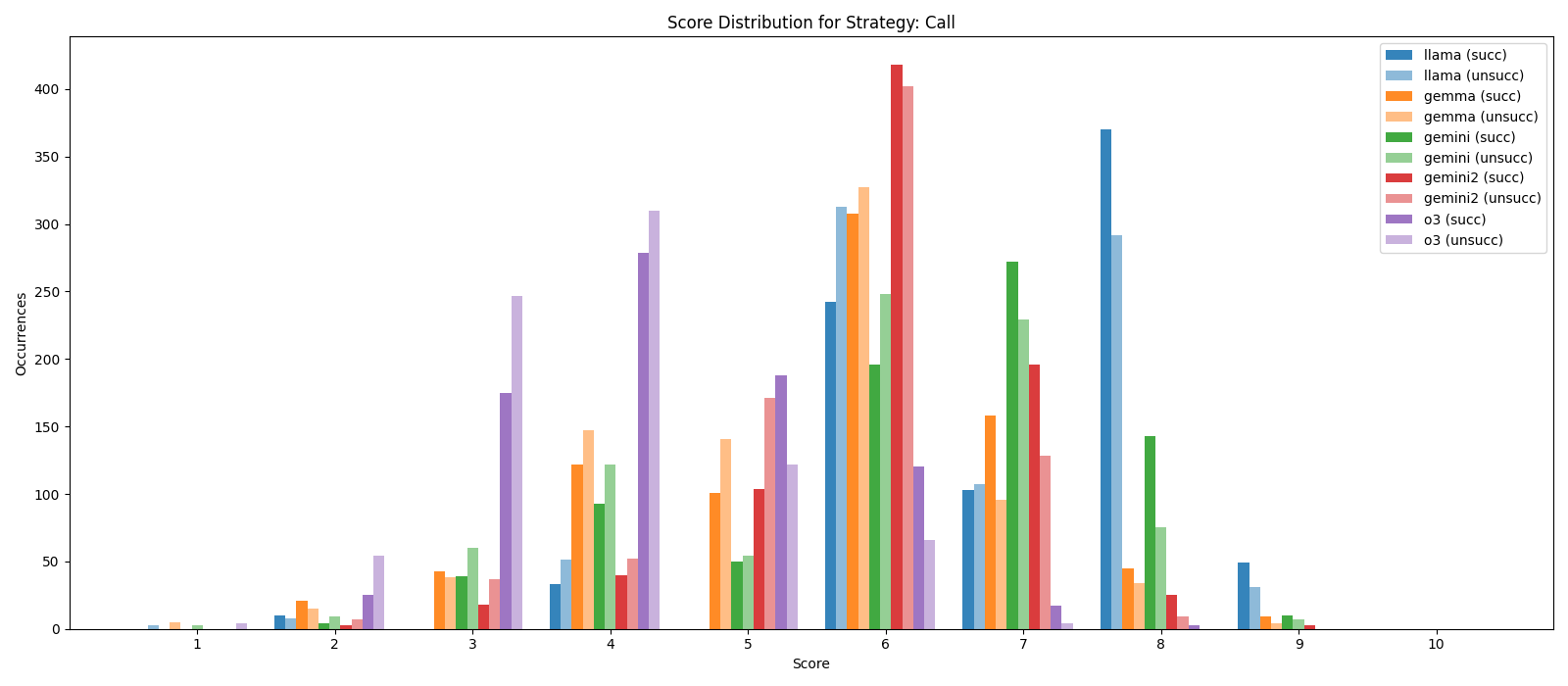
📊 实验亮点
实验结果表明,该方法在三个数据集上均取得了较好的性能。特别是在Winning Arguments数据集上,通过策略引导的推理,说服力预测的准确性得到了显著提高。此外,论文还对不同主题下的性能进行了分析,发现模型在某些主题下表现更好,这为未来的研究提供了方向。
🎯 应用场景
该研究成果可应用于舆情分析、智能辩论系统、在线评论分析等领域。通过识别论辩文本中的说服策略和胜方,可以更好地理解公众观点,辅助决策制定,并提高人机交互的质量。未来,该技术有望应用于自动化内容审核和虚假信息检测。
📄 摘要(原文)
Detecting persuasion in argumentative text is a challenging task with important implications for understanding human communication. This work investigates the role of persuasion strategies - such as Attack on reputation, Distraction, and Manipulative wording - in determining the persuasiveness of a text. We conduct experiments on three annotated argument datasets: Winning Arguments (built from the Change My View subreddit), Anthropic/Persuasion, and Persuasion for Good. Our approach leverages large language models (LLMs) with a Multi-Strategy Persuasion Scoring approach that guides reasoning over six persuasion strategies. Results show that strategy-guided reasoning improves the prediction of persuasiveness. To better understand the influence of content, we organize the Winning Argument dataset into broad discussion topics and analyze performance across them. We publicly release this topic-annotated version of the dataset to facilitate future research. Overall, our methodology demonstrates the value of structured, strategy-aware prompting for enhancing interpretability and robustness in argument quality assessment.