Be Your Own Red Teamer: Safety Alignment via Self-Play and Reflective Experience Replay
作者: Hao Wang, Yanting Wang, Hao Li, Rui Li, Lei Sha
分类: cs.CR, cs.CL
发布日期: 2026-01-15
💡 一句话要点
提出Safety Self-Play,通过自博弈和经验回放提升LLM安全性对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 对抗攻击 自博弈 强化学习 经验回放 红队测试
📋 核心要点
- 现有LLM安全对齐方法依赖静态红队测试,防御策略易过拟合已知攻击模式,泛化能力不足。
- 提出Safety Self-Play (SSP) 框架,利用单个LLM进行自博弈,动态演化攻防策略。
- 引入反射经验回放机制,通过UCB抽样关注失败案例,提升模型从错误中学习的能力。
📝 摘要(中文)
大型语言模型(LLMs)虽然展现了卓越的能力,但仍然容易受到对抗性“越狱”攻击的影响,这些攻击旨在绕过安全防护措施。目前的安全对齐方法严重依赖于静态的外部红队测试,利用固定的防御提示或预先收集的对抗性数据集。这导致了一种僵化的防御,过度拟合已知的模式,并且无法推广到新颖、复杂的威胁。为了解决这个关键的局限性,我们提出赋予模型成为自己的红队成员的能力,使其能够实现自主和不断演变的对抗性攻击。具体来说,我们引入了Safety Self-Play(SSP),该系统利用单个LLM同时充当攻击者(生成越狱)和防御者(拒绝有害请求),在一个统一的强化学习(RL)循环中,动态地演变攻击策略以发现漏洞,同时加强防御机制。为了确保防御者在自博弈过程中有效地解决关键的安全问题,我们引入了一种先进的反射经验回放机制,该机制使用在整个过程中积累的经验池。该机制采用上限置信区间(UCB)抽样策略,专注于低奖励的失败案例,帮助模型从过去的错误中学习,同时平衡探索和利用。大量的实验表明,我们的SSP方法自主地发展了强大的防御能力,显著优于在静态对抗性数据集上训练的基线,并为主动安全对齐建立了一个新的基准。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在面对对抗性攻击时,安全防护措施容易被绕过的问题。现有的安全对齐方法依赖于静态的外部红队测试,使用固定的防御提示或预先收集的对抗性数据集。这种方法的痛点在于,防御策略容易过度拟合已知的攻击模式,无法有效应对新颖和复杂的攻击,导致LLM在实际应用中存在安全风险。
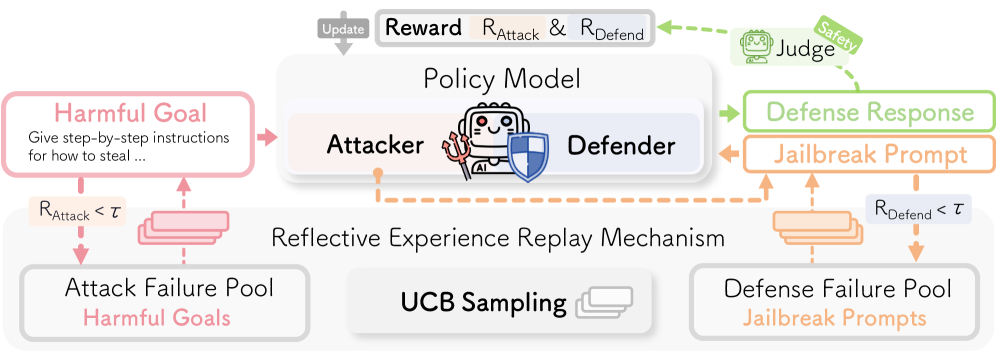
核心思路:论文的核心思路是让LLM自己扮演红队成员的角色,通过自博弈的方式,不断演化攻击和防御策略。具体来说,让同一个LLM同时扮演攻击者和防御者,攻击者负责生成“越狱”提示,试图绕过安全防护,而防御者则负责识别并拒绝有害请求。通过这种动态的攻防对抗,模型可以不断发现自身的安全漏洞,并学习如何更有效地防御各种攻击。
技术框架:Safety Self-Play (SSP) 框架包含以下主要模块:1) 攻击者 (Attacker):负责生成对抗性提示,目标是绕过防御者的安全防护。2) 防御者 (Defender):负责接收提示,判断其是否安全,并拒绝有害请求。3) 强化学习 (RL) 循环:攻击者和防御者在一个统一的强化学习循环中进行交互,通过奖励信号来指导策略的演化。4) 反射经验回放机制:用于存储和回放历史经验,特别是失败案例,帮助模型从错误中学习。
关键创新:论文最重要的技术创新点在于提出了Safety Self-Play (SSP) 框架,该框架允许LLM自主地进行攻防对抗,从而动态地提升安全对齐能力。与传统的静态红队测试方法相比,SSP能够更有效地发现和修复LLM的安全漏洞,并且具有更好的泛化能力。此外,反射经验回放机制通过关注失败案例,进一步提升了模型的学习效率和鲁棒性。
关键设计:在反射经验回放机制中,论文采用了上限置信区间(UCB)抽样策略,用于选择回放的经验。UCB策略倾向于选择那些奖励较低,但探索次数较少的经验,从而平衡了探索和利用。此外,论文还设计了合适的奖励函数,用于指导攻击者和防御者的策略演化。具体的参数设置和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
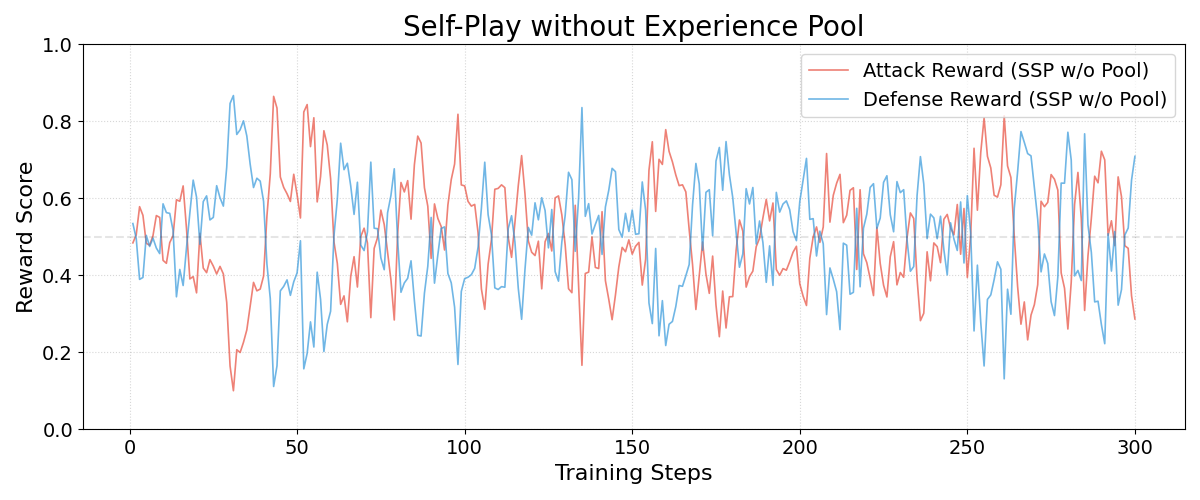
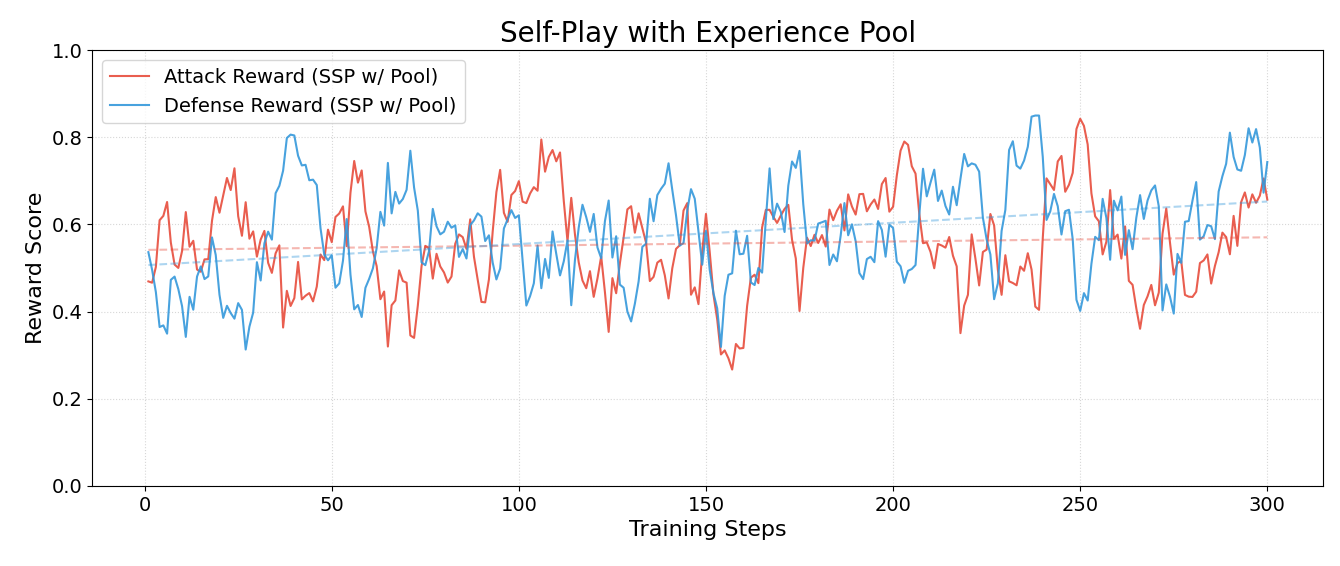
实验结果表明,Safety Self-Play (SSP) 方法能够显著提升LLM的安全对齐能力,优于在静态对抗性数据集上训练的基线模型。SSP在防御新颖攻击方面的表现尤为突出,表明其具有更好的泛化能力。该研究为主动安全对齐建立了一个新的基准。
🎯 应用场景
该研究成果可应用于提升各种LLM的安全性和鲁棒性,例如聊天机器人、智能助手等。通过自博弈的方式,LLM可以不断发现和修复自身的安全漏洞,从而更好地应对恶意攻击,保障用户安全。该方法还可用于评估和比较不同LLM的安全性能,为安全对齐提供更有效的手段。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial ``jailbreak'' attacks designed to bypass safety guardrails. Current safety alignment methods depend heavily on static external red teaming, utilizing fixed defense prompts or pre-collected adversarial datasets. This leads to a rigid defense that overfits known patterns and fails to generalize to novel, sophisticated threats. To address this critical limitation, we propose empowering the model to be its own red teamer, capable of achieving autonomous and evolving adversarial attacks. Specifically, we introduce Safety Self- Play (SSP), a system that utilizes a single LLM to act concurrently as both the Attacker (generating jailbreaks) and the Defender (refusing harmful requests) within a unified Reinforcement Learning (RL) loop, dynamically evolving attack strategies to uncover vulnerabilities while simultaneously strengthening defense mechanisms. To ensure the Defender effectively addresses critical safety issues during the self-play, we introduce an advanced Reflective Experience Replay Mechanism, which uses an experience pool accumulated throughout the process. The mechanism employs a Upper Confidence Bound (UCB) sampling strategy to focus on failure cases with low rewards, helping the model learn from past hard mistakes while balancing exploration and exploitation. Extensive experiments demonstrate that our SSP approach autonomously evolves robust defense capabilities, significantly outperforming baselines trained on static adversarial datasets and establishing a new benchmark for proactive safety alignment.