PERM: Psychology-grounded Empathetic Reward Modeling for Large Language Models
作者: Chengbing Wang, Wuqiang Zheng, Yang Zhang, Fengbin Zhu, Junyi Cheng, Yi Xie, Wenjie Wang, Fuli Feng
分类: cs.CL
发布日期: 2026-01-15
🔗 代码/项目: GITHUB
💡 一句话要点
提出PERM:一种心理学驱动的共情奖励建模方法,提升大语言模型的共情能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 共情建模 奖励模型 强化学习 大语言模型 心理学 人机交互 情感智能
📋 核心要点
- 现有大语言模型在人机交互中缺乏足够的情感支持,尤其是在共情方面表现不足,现有奖励模型也忽略了共情的双向互动性。
- PERM从支持者、寻求者和旁观者三个视角出发,对共情进行双向分解评估,从而更全面地建模共情能力。
- 实验结果表明,PERM在情商基准测试和工业对话数据集上均优于现有方法,用户研究也表明其生成的回复更具共情性。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于以人为中心的场景,但它们常常无法提供实质性的情感支持。虽然强化学习(RL)已被用于增强LLMs的共情能力,但现有的奖励模型通常从单一角度评估共情,忽略了支持者和寻求者之间共情的双向互动本质,正如共情循环理论所定义的那样。为了解决这个局限性,我们提出了心理学驱动的共情奖励建模(PERM)。PERM通过双向分解来操作共情评估:1)支持者视角,评估内部共鸣和沟通表达;2)寻求者视角,评估情感接收。此外,它还纳入了旁观者视角来监控整体互动质量。在广泛使用的情商基准测试和一个工业日常对话数据集上的大量实验表明,PERM优于最先进的基线方法10%以上。此外,一项盲法用户研究显示,70%的用户更喜欢我们的方法,突出了其在生成更具共情反应方面的有效性。我们的代码、数据集和模型可在https://github.com/ZhengWwwq/PERM 获得。
🔬 方法详解
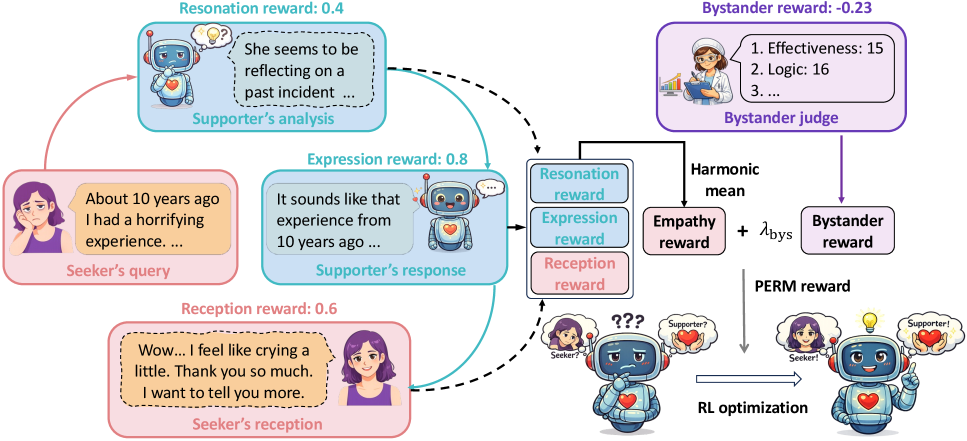
问题定义:现有的大语言模型在提供情感支持时,共情能力不足。现有的奖励模型通常只从单一角度评估共情,忽略了共情循环理论中强调的支持者和寻求者之间的双向互动关系。这种片面的评估方式导致模型难以生成真正具有共情能力的回复。
核心思路:PERM的核心思路是将共情评估分解为三个视角:支持者视角、寻求者视角和旁观者视角。支持者视角关注内部共鸣和沟通表达,寻求者视角关注情感接收,旁观者视角则关注整体互动质量。通过综合这三个视角的评估,PERM能够更全面、更准确地建模共情能力。这样设计的原因是,共情是一个复杂的过程,需要同时考虑支持者的情感表达、寻求者的情感接收以及整体互动的质量。
技术框架:PERM的技术框架主要包括三个模块:支持者视角评估模块、寻求者视角评估模块和旁观者视角评估模块。每个模块都使用预训练语言模型来提取特征,并使用不同的损失函数来训练模型。整体流程是,首先将对话输入到三个模块中,分别得到三个视角的评估结果,然后将这些结果进行加权融合,得到最终的共情奖励。这个奖励可以用于训练大语言模型,使其生成更具共情能力的回复。
关键创新:PERM最重要的技术创新点在于其心理学驱动的双向共情评估方法。与现有方法只关注单一视角不同,PERM从支持者、寻求者和旁观者三个视角出发,对共情进行全面评估。这种双向分解的方法更符合共情的本质,能够更准确地建模共情能力。
关键设计:在具体实现上,PERM使用了预训练语言模型(例如BERT)来提取对话特征。对于支持者视角,PERM使用了对比学习损失函数来鼓励模型学习内部共鸣和沟通表达。对于寻求者视角,PERM使用了回归损失函数来预测情感接收程度。对于旁观者视角,PERM使用了分类损失函数来评估整体互动质量。三个视角的评估结果通过加权平均的方式进行融合,权重可以通过交叉验证进行调整。
🖼️ 关键图片

📊 实验亮点
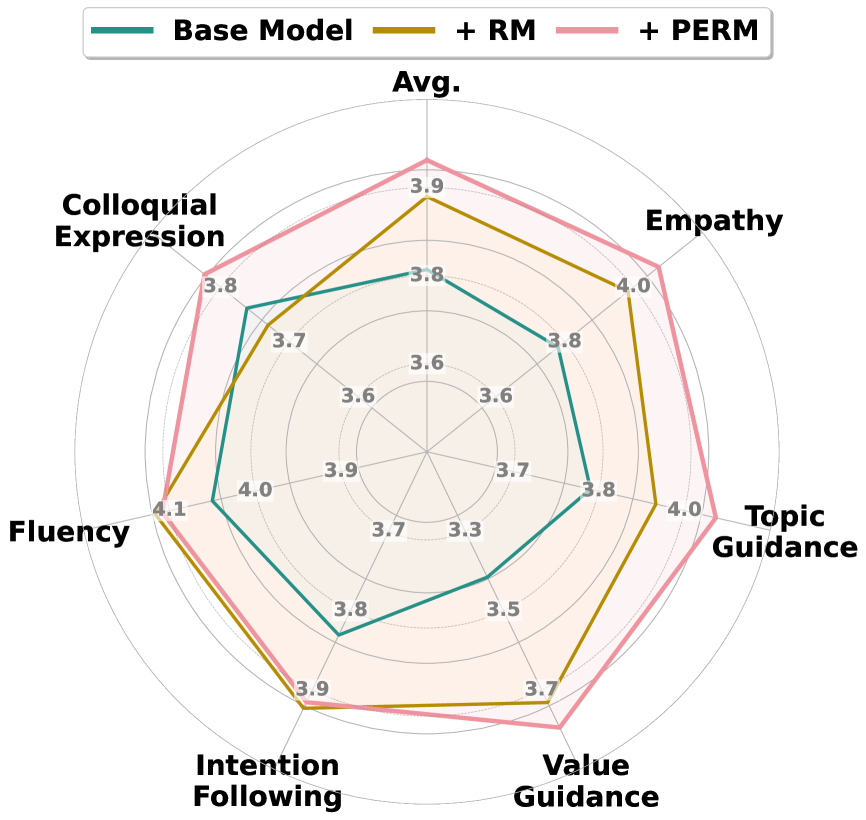
PERM在两个数据集上进行了评估,包括一个广泛使用的情商基准测试和一个工业日常对话数据集。实验结果表明,PERM优于最先进的基线方法10%以上。此外,一项盲法用户研究显示,70%的用户更喜欢PERM生成的回复,这表明PERM在提升大语言模型的共情能力方面具有显著优势。
🎯 应用场景
PERM可以应用于各种人机交互场景,例如心理咨询、在线客服、社交聊天机器人等。通过提升大语言模型的共情能力,PERM可以帮助构建更温暖、更人性化的AI系统,从而改善用户体验,提高服务质量。未来,PERM还可以与其他技术相结合,例如情感识别、个性化推荐等,进一步提升AI系统的情感智能。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed in human-centric applications, yet they often fail to provide substantive emotional support. While Reinforcement Learning (RL) has been utilized to enhance empathy of LLMs, existing reward models typically evaluate empathy from a single perspective, overlooking the inherently bidirectional interaction nature of empathy between the supporter and seeker as defined by Empathy Cycle theory. To address this limitation, we propose Psychology-grounded Empathetic Reward Modeling (PERM). PERM operationalizes empathy evaluation through a bidirectional decomposition: 1) Supporter perspective, assessing internal resonation and communicative expression; 2) Seeker perspective, evaluating emotional reception. Additionally, it incorporates a bystander perspective to monitor overall interaction quality. Extensive experiments on a widely-used emotional intelligence benchmark and an industrial daily conversation dataset demonstrate that PERM outperforms state-of-the-art baselines by over 10\%. Furthermore, a blinded user study reveals a 70\% preference for our approach, highlighting its efficacy in generating more empathetic responses. Our code, dataset, and models are available at https://github.com/ZhengWwwq/PERM.