DR-Arena: an Automated Evaluation Framework for Deep Research Agents
作者: Yiwen Gao, Ruochen Zhao, Yang Deng, Wenxuan Zhang
分类: cs.CL
发布日期: 2026-01-15
备注: 22 pages, 8 figures
💡 一句话要点
DR-Arena:提出一个全自动的深度研究Agent评估框架,解决现有基准测试的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度研究Agent 自动评估框架 动态任务生成 信息树 自适应演化 大型语言模型 能力评估
📋 核心要点
- 现有深度研究Agent的评估基准依赖静态数据集,存在任务泛化性差、时效性不足和数据污染等问题。
- DR-Arena通过构建实时信息树和自适应演化循环,动态生成评估任务,更贴近真实世界,并能探索Agent的能力边界。
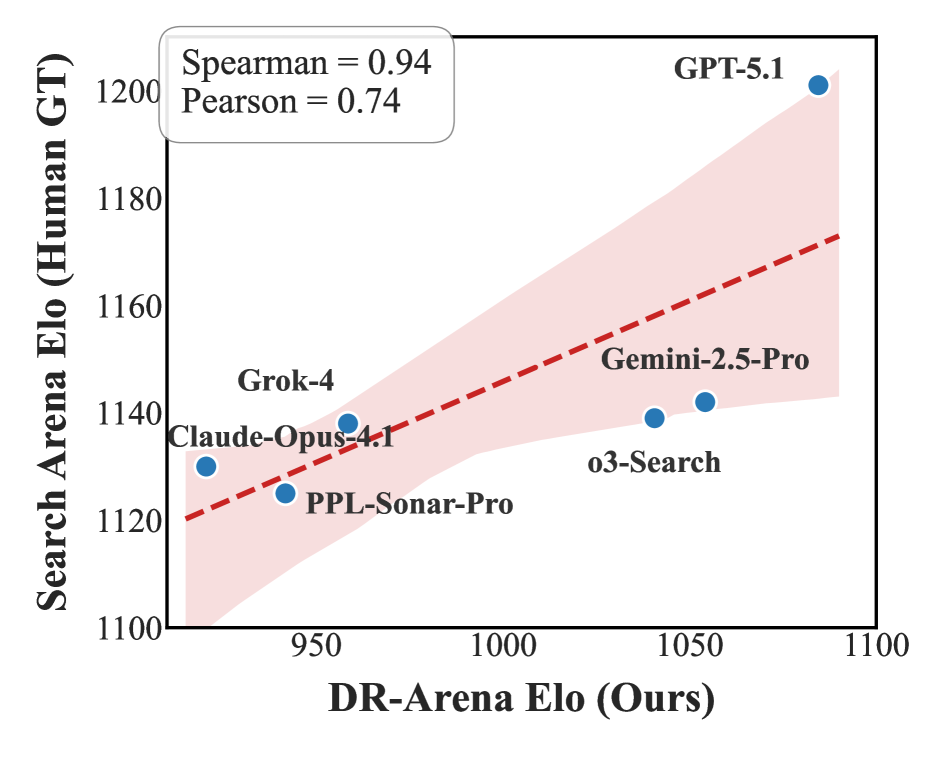
- 实验表明,DR-Arena与人类偏好高度一致(Spearman相关性0.94),可作为人工评估的可靠替代方案。
📝 摘要(中文)
随着大型语言模型(LLMs)越来越多地作为深度研究(DR)Agent自主进行调查和信息整合,对其任务性能的可靠评估已成为一个关键瓶颈。当前的基准测试主要依赖于静态数据集,这些数据集存在诸多局限性:任务泛化能力有限、时间错位和数据污染。为了解决这些问题,我们引入了DR-Arena,这是一个全自动的评估框架,通过动态调查将DR Agent的能力推向极限。DR-Arena从最新的网络趋势构建实时信息树,以确保评估标准与实时世界状态同步,并采用自动审查器生成结构化任务,测试两个正交能力:深度推理和广泛覆盖。DR-Arena进一步采用自适应演化循环,这是一种状态机控制器,可根据实时性能动态升级任务复杂性,要求更深入的推导或更广泛的聚合,直到出现决定性的能力边界。对六个高级DR Agent的实验表明,DR-Arena与LMSYS Search Arena排行榜实现了0.94的Spearman相关性。这代表了与人类偏好对齐的最新水平,无需任何人工干预,从而验证了DR-Arena作为昂贵的人工判定的可靠替代方案。
🔬 方法详解
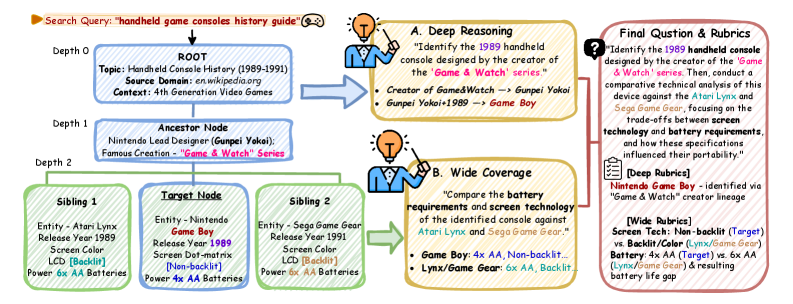
问题定义:现有深度研究Agent的评估方法主要依赖静态数据集,这些数据集无法反映真实世界信息的动态变化,导致评估结果与Agent在实际应用中的表现存在偏差。此外,静态数据集容易受到数据污染的影响,使得评估结果的可靠性降低。因此,需要一种能够动态生成评估任务,并与实时世界状态同步的评估框架。
核心思路:DR-Arena的核心思路是构建一个全自动的评估环境,该环境能够根据最新的网络趋势动态生成评估任务,并根据Agent的实时表现自适应地调整任务难度。通过这种方式,DR-Arena能够更全面、更准确地评估Agent的深度推理和广泛覆盖能力。
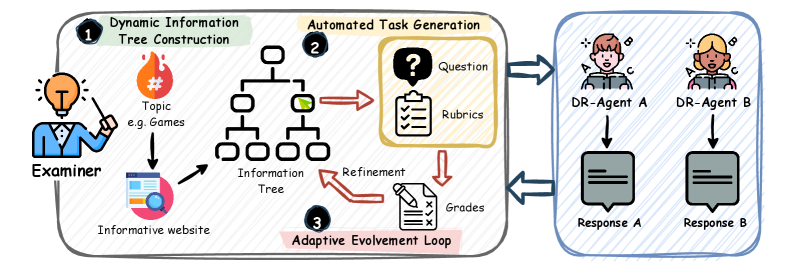
技术框架:DR-Arena主要包含三个模块:信息树构建模块、自动审查器模块和自适应演化循环模块。信息树构建模块负责从最新的网络趋势中提取信息,并构建成实时信息树。自动审查器模块负责根据信息树生成结构化任务,测试Agent的深度推理和广泛覆盖能力。自适应演化循环模块则根据Agent的实时表现动态升级任务复杂性,直到Agent的能力边界出现。
关键创新:DR-Arena的关键创新在于其全自动化的评估流程和动态任务生成机制。与传统的静态数据集评估方法相比,DR-Arena能够更好地反映真实世界信息的动态变化,并能够更全面地评估Agent的能力。此外,DR-Arena的自适应演化循环能够有效地探索Agent的能力边界,从而提供更深入的评估结果。
关键设计:DR-Arena的关键设计包括:信息树的构建方式(如何从网络趋势中提取信息并构建成树状结构)、自动审查器的任务生成策略(如何根据信息树生成结构化任务,并保证任务的难度和多样性)以及自适应演化循环的控制策略(如何根据Agent的实时表现动态调整任务难度)。这些设计细节直接影响着DR-Arena的评估效果和效率,但论文中未提供具体参数设置、损失函数、网络结构等技术细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DR-Arena与LMSYS Search Arena排行榜实现了0.94的Spearman相关性,这表明DR-Arena能够有效地反映人类对Agent性能的偏好。此外,实验还表明,DR-Arena能够区分不同Agent的深度推理和广泛覆盖能力,并能够有效地探索Agent的能力边界。
🎯 应用场景
DR-Arena可用于评估各种深度研究Agent,例如信息检索、知识图谱构建、问答系统等。该框架能够帮助研究人员更好地了解Agent的能力,并指导Agent的改进和优化。此外,DR-Arena还可以用于比较不同Agent的性能,为用户选择合适的Agent提供参考。
📄 摘要(原文)
As Large Language Models (LLMs) increasingly operate as Deep Research (DR) Agents capable of autonomous investigation and information synthesis, reliable evaluation of their task performance has become a critical bottleneck. Current benchmarks predominantly rely on static datasets, which suffer from several limitations: limited task generality, temporal misalignment, and data contamination. To address these, we introduce DR-Arena, a fully automated evaluation framework that pushes DR agents to their capability limits through dynamic investigation. DR-Arena constructs real-time Information Trees from fresh web trends to ensure the evaluation rubric is synchronized with the live world state, and employs an automated Examiner to generate structured tasks testing two orthogonal capabilities: Deep reasoning and Wide coverage. DR-Arena further adopts Adaptive Evolvement Loop, a state-machine controller that dynamically escalates task complexity based on real-time performance, demanding deeper deduction or wider aggregation until a decisive capability boundary emerges. Experiments with six advanced DR agents demonstrate that DR-Arena achieves a Spearman correlation of 0.94 with the LMSYS Search Arena leaderboard. This represents the state-of-the-art alignment with human preferences without any manual efforts, validating DR-Arena as a reliable alternative for costly human adjudication.