OctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding
作者: Deming Ding, Shichun Liu, Enhui Yang, Jiahang Lin, Ziying Chen, Shihan Dou, Honglin Guo, Weiyu Cheng, Pengyu Zhao, Chengjun Xiao, Qunhong Zeng, Qi Zhang, Xuanjing Huang, Qidi Xu, Tao Gui
分类: cs.CL, cs.AI
发布日期: 2026-01-15
💡 一句话要点
OctoBench:评估代码仓库环境下的具身智能体对脚手架指令的遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 具身智能体 脚手架指令 基准测试 代码仓库 自动化评估
📋 核心要点
- 现有方法难以保证LLM在代码仓库环境中,严格遵循异构且持续存在的脚手架指令。
- OctoBench通过构建包含多种脚手架类型的任务环境,并提供自动化的评估工具,来衡量智能体对指令的遵循程度。
- 实验表明,现有模型在任务解决和脚手架感知合规性之间存在差距,需要专门的训练和评估。
📝 摘要(中文)
现代代码脚手架将大型语言模型转变为强大的软件智能体,但它们遵循脚手架指定指令的能力仍未得到充分检验,尤其是在约束异构且跨交互持续存在时。为了填补这一空白,我们推出了 OctoBench,它用于评估代码仓库环境下的具身智能体对脚手架指令的遵循能力。OctoBench 包括 34 个环境和 217 个在三种脚手架类型下实例化的任务,并配有 7,098 个客观检查清单项。为了将解决任务与遵守规则分开,我们提供了一个自动化的观察和评分工具包,该工具包捕获完整的轨迹并执行细粒度的检查。对八个代表性模型的实验揭示了任务解决和脚手架感知合规性之间存在系统性差距,突显了明确针对异构指令遵循进行训练和评估的必要性。我们发布该基准测试以支持可重复的基准测试,并加速开发更具脚手架感知能力的编码智能体。
🔬 方法详解
问题定义:论文旨在解决现有大型语言模型(LLM)在代码仓库环境中,难以有效遵循脚手架(Scaffold)指令的问题。现有方法通常只关注任务的完成度,而忽略了LLM是否严格按照脚手架预设的规则和约束进行操作。这种忽略可能导致生成的代码虽然功能正确,但不符合项目规范或安全要求,从而带来潜在风险。
核心思路:论文的核心思路是构建一个专门用于评估LLM对脚手架指令遵循能力的基准测试平台OctoBench。该平台通过提供多样化的任务环境和细粒度的评估指标,来量化LLM在代码生成过程中对脚手架指令的遵守程度。通过这种方式,可以更全面地了解LLM的优势和不足,并为未来的模型改进提供指导。
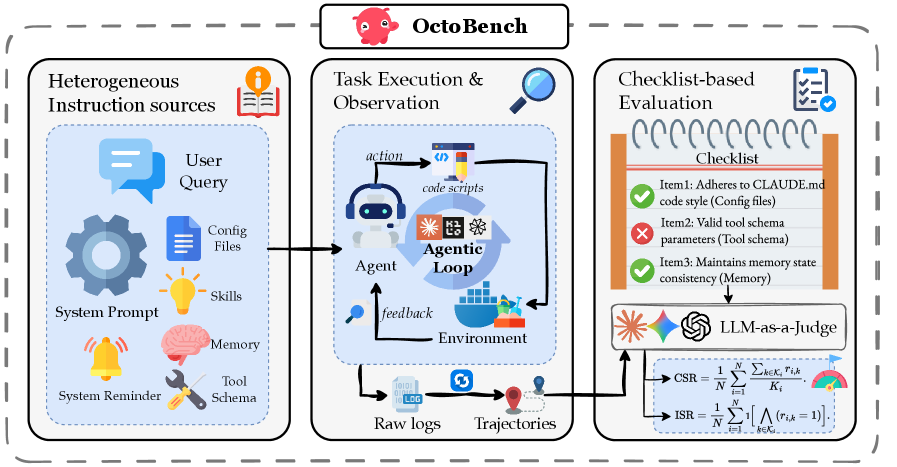
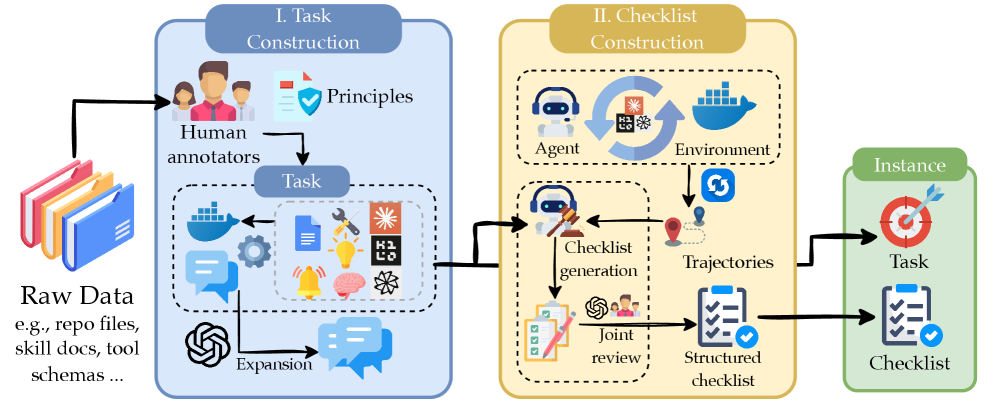
技术框架:OctoBench的技术框架主要包含以下几个部分:1) 任务环境构建:设计了34个不同的代码仓库环境,涵盖多种编程语言和应用场景。2) 脚手架指令定义:为每个任务环境定义了三种不同类型的脚手架指令,包括代码风格、安全约束和API使用规范等。3) 自动化评估工具:开发了一个自动化的观察和评分工具包,可以捕获LLM的完整执行轨迹,并根据预定义的检查清单进行细粒度的评估。4) 基准测试协议:制定了一套标准的基准测试协议,用于评估不同LLM在OctoBench上的性能。
关键创新:OctoBench最重要的技术创新点在于其对脚手架指令遵循能力的显式建模和评估。与以往只关注任务完成度的基准测试不同,OctoBench更加关注LLM在代码生成过程中对预设规则和约束的遵守程度。这种细粒度的评估方式可以更准确地反映LLM的实际能力,并为未来的模型改进提供更有效的指导。
关键设计:OctoBench的关键设计包括:1) 多样化的任务环境:涵盖多种编程语言和应用场景,以评估LLM在不同环境下的泛化能力。2) 细粒度的评估指标:采用客观检查清单项来量化LLM对脚手架指令的遵守程度,避免主观偏差。3) 自动化的评估流程:通过自动化的观察和评分工具包,实现对LLM执行轨迹的全面监控和评估,提高评估效率和准确性。
🖼️ 关键图片
📊 实验亮点
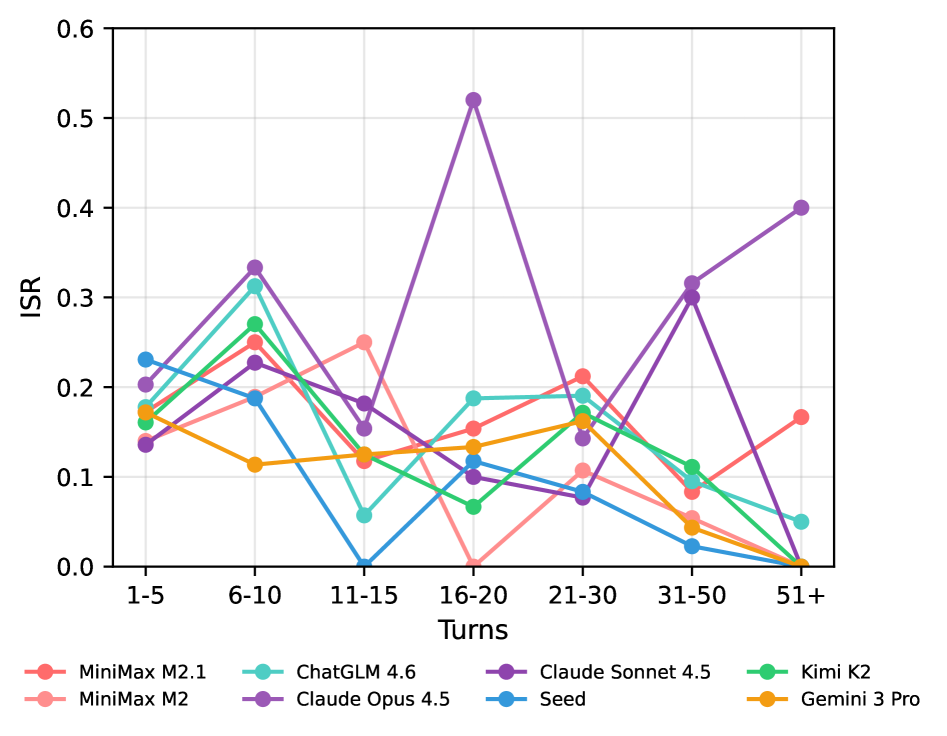
在OctoBench上对八个代表性模型的实验表明,现有模型在任务解决和脚手架感知合规性之间存在显著差距。具体而言,某些模型虽然能够完成任务,但在遵守代码风格、安全约束等方面表现不佳。这些实验结果突显了开发更具脚手架感知能力的编码智能体的必要性。
🎯 应用场景
该研究成果可应用于软件开发自动化、代码质量控制、安全漏洞检测等领域。通过提高LLM对脚手架指令的遵循能力,可以显著提升代码生成的质量和安全性,降低人工审核成本,并加速软件开发流程。未来,该研究有望推动LLM在更广泛的软件工程领域的应用。
📄 摘要(原文)
Modern coding scaffolds turn LLMs into capable software agents, but their ability to follow scaffold-specified instructions remains under-examined, especially when constraints are heterogeneous and persist across interactions. To fill this gap, we introduce OctoBench, which benchmarks scaffold-aware instruction following in repository-grounded agentic coding. OctoBench includes 34 environments and 217 tasks instantiated under three scaffold types, and is paired with 7,098 objective checklist items. To disentangle solving the task from following the rules, we provide an automated observation-and-scoring toolkit that captures full trajectories and performs fine-grained checks. Experiments on eight representative models reveal a systematic gap between task-solving and scaffold-aware compliance, underscoring the need for training and evaluation that explicitly targets heterogeneous instruction following. We release the benchmark to support reproducible benchmarking and to accelerate the development of more scaffold-aware coding agents.