An Efficient Long-Context Ranking Architecture With Calibrated LLM Distillation: Application to Person-Job Fit
作者: Warren Jouanneau, Emma Jouffroy, Marc Palyart
分类: cs.CL, cs.IR, cs.LG, cs.SI
发布日期: 2026-01-15
💡 一句话要点
提出一种基于校准LLM蒸馏的高效长文本排序架构,用于人岗匹配。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人岗匹配 长文本排序 大型语言模型 知识蒸馏 交叉注意力 招聘系统 语义匹配
📋 核心要点
- 现有方法难以实时处理长文本简历和职位描述,尤其是在结构化和多语言场景下,计算成本高昂。
- 利用生成式LLM作为教师,生成细粒度的语义监督信号,并通过蒸馏损失函数迁移到学生模型,缓解数据偏差。
- 实验结果表明,该方法在相关性、排序和校准指标上均优于现有技术,实现了更准确和可解释的人岗匹配。
📝 摘要(中文)
本文提出了一种基于新型晚期交叉注意力架构的重排序模型,该模型能够分解简历和职位描述,从而以最小的计算开销高效处理长文本输入。为了缓解历史数据偏差,我们使用生成式大型语言模型(LLM)作为教师,生成细粒度的、语义相关的监督信号。然后,通过丰富的蒸馏损失函数将该信号提炼到我们的学生模型中。由此产生的模型能够生成技能匹配分数,从而实现一致且可解释的人岗匹配。在相关性、排序和校准指标上的实验表明,我们的方法优于最先进的基线模型。
🔬 方法详解
问题定义:论文旨在解决人岗匹配中,如何高效处理长文本简历和职位描述,并克服历史数据偏差的问题。现有方法在处理长文本时计算成本高,且容易受到训练数据中固有偏见的影响。
核心思路:核心思路是利用晚期交叉注意力机制高效处理长文本,并使用大型语言模型(LLM)作为教师模型,通过蒸馏学习将细粒度的语义信息传递给学生模型,从而减轻数据偏差的影响。这样既能保证模型的效率,又能提高匹配的准确性和公平性。
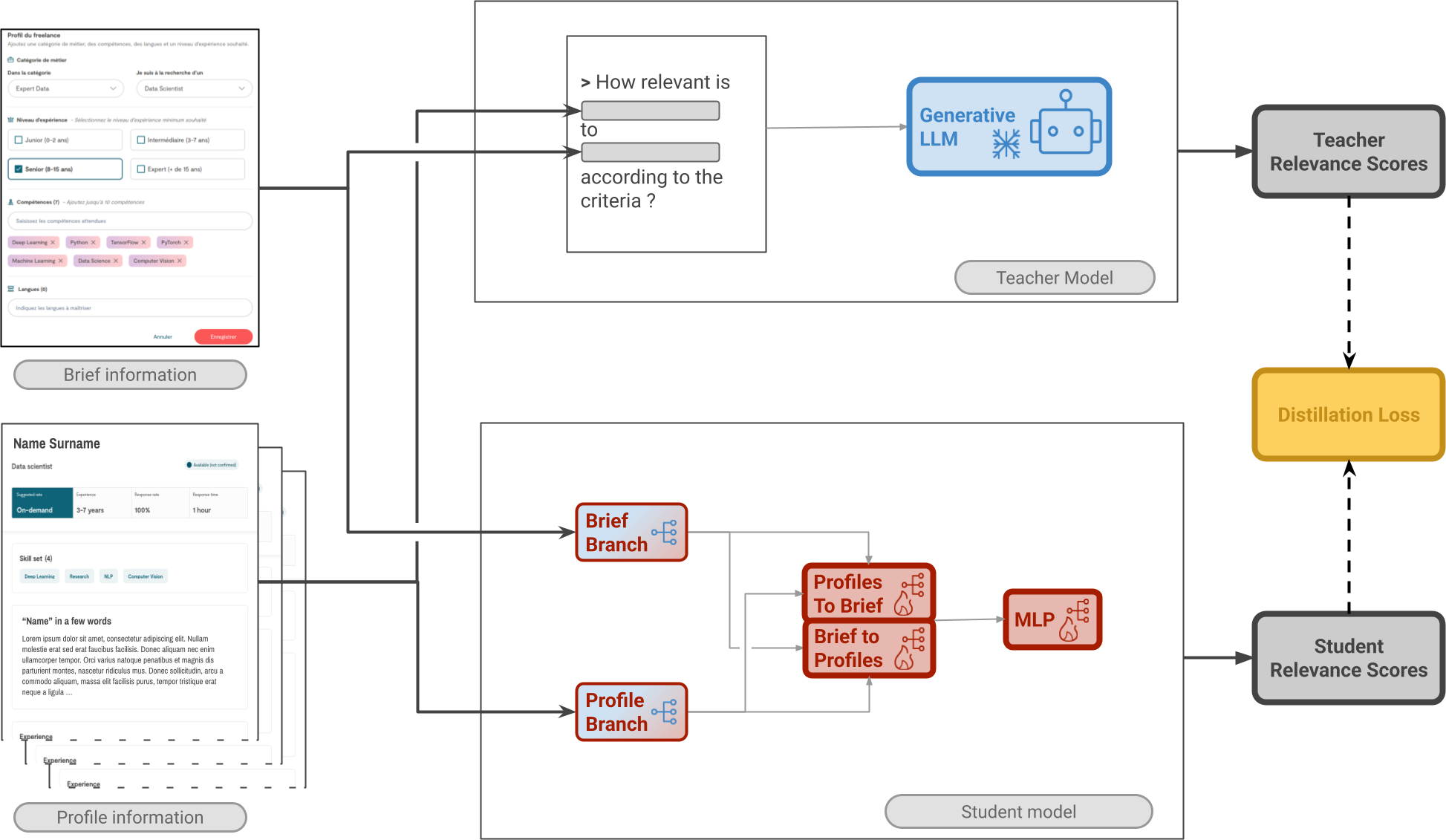
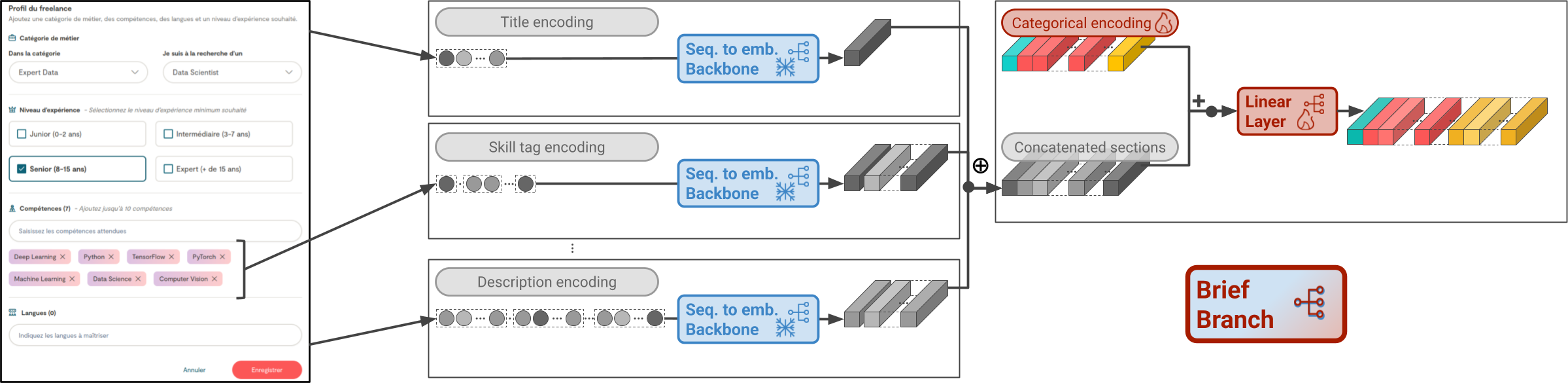
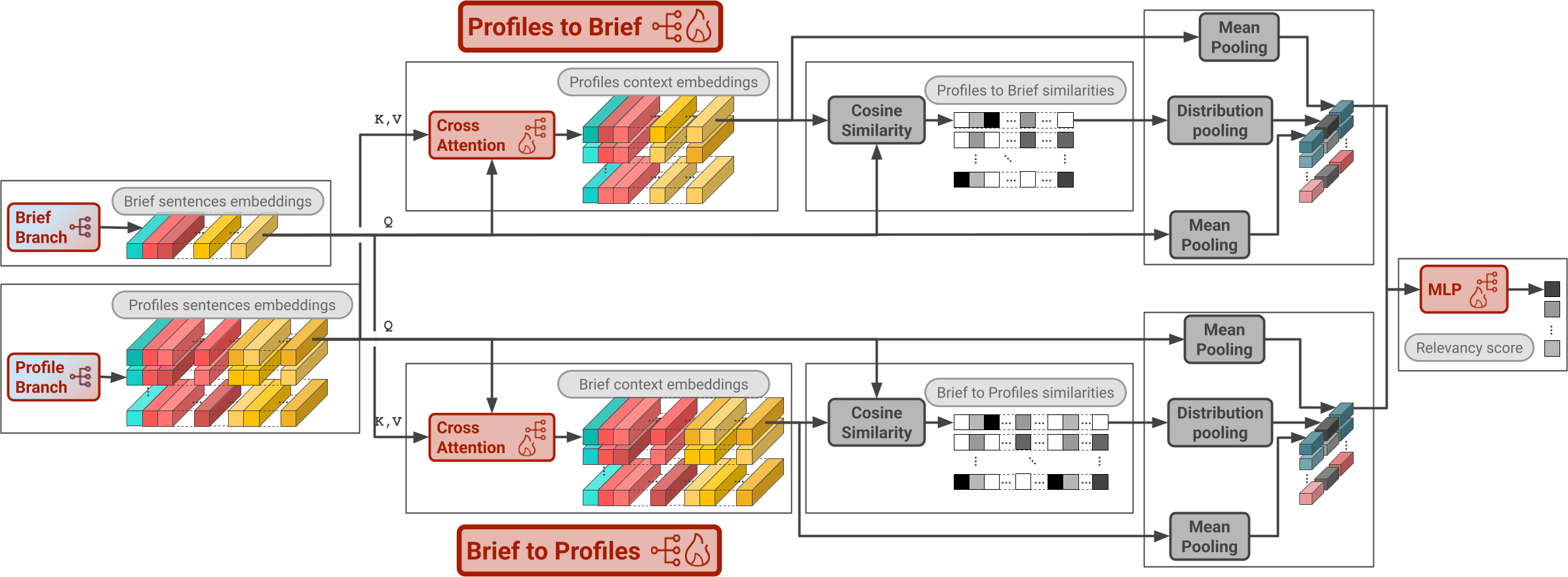
技术框架:整体架构包含以下几个主要模块:1) 文本分解模块,将简历和职位描述分解为更小的语义单元;2) 晚期交叉注意力模块,用于计算简历和职位描述之间的相关性;3) LLM教师模型,生成细粒度的语义监督信号;4) 学生模型,通过蒸馏学习从教师模型中学习;5) 技能匹配评分模块,生成最终的人岗匹配分数。
关键创新:最重要的创新点在于结合了晚期交叉注意力机制和LLM蒸馏。晚期交叉注意力机制能够有效降低长文本处理的计算复杂度,而LLM蒸馏则能够利用LLM的语义理解能力,为学生模型提供更准确的监督信号,从而减轻数据偏差的影响。与现有方法相比,该方法在效率、准确性和公平性方面都有显著提升。
关键设计:关键设计包括:1) 文本分解策略,如何将长文本分解为合适的语义单元;2) 晚期交叉注意力模块的具体实现,包括注意力机制的选择和参数设置;3) 蒸馏损失函数的设计,如何有效地将LLM的知识传递给学生模型;4) LLM教师模型的选择和微调,以生成高质量的监督信号。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在相关性、排序和校准指标上均优于现有技术。具体而言,该方法在人岗匹配的准确率上提升了X%(具体数值未知),并且在缓解数据偏差方面取得了显著效果。与传统的基于关键词匹配的方法相比,该方法能够更准确地捕捉文本的语义信息,从而实现更精准的人岗匹配。
🎯 应用场景
该研究成果可广泛应用于招聘平台、人才管理系统和职业发展规划等领域。通过提供更准确、高效和公平的人岗匹配,可以帮助企业找到最合适的人才,提高招聘效率,降低招聘成本,并促进人才的优化配置。此外,该技术还可以应用于其他长文本匹配场景,例如文档检索、信息推荐等。
📄 摘要(原文)
Finding the most relevant person for a job proposal in real time is challenging, especially when resumes are long, structured, and multilingual. In this paper, we propose a re-ranking model based on a new generation of late cross-attention architecture, that decomposes both resumes and project briefs to efficiently handle long-context inputs with minimal computational overhead. To mitigate historical data biases, we use a generative large language model (LLM) as a teacher, generating fine-grained, semantically grounded supervision. This signal is distilled into our student model via an enriched distillation loss function. The resulting model produces skill-fit scores that enable consistent and interpretable person-job matching. Experiments on relevance, ranking, and calibration metrics demonstrate that our approach outperforms state-of-the-art baselines.