Boundary-Aware NL2SQL: Integrating Reliability through Hybrid Reward and Data Synthesis
作者: Songsong Tian, Kongsheng Zhuo, Zhendong Wang, Rong Shen, Shengtao Zhang, Yong Wu
分类: cs.CL
发布日期: 2026-01-15
🔗 代码/项目: GITHUB
💡 一句话要点
提出BAR-SQL框架,通过混合奖励和数据合成提升NL2SQL的可靠性和边界感知能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NL2SQL 数据合成 强化学习 混合奖励 边界感知 知识推理 企业级应用
📋 核心要点
- 现有NL2SQL方法在处理企业级复杂查询和边界情况(如歧义、模式限制)时表现不足,缺乏可靠性和边界感知能力。
- BAR-SQL通过种子突变数据合成构建企业语料库,并采用知识驱动的推理合成生成Chain-of-Thought轨迹,提升模型可解释性。
- 实验结果表明,BAR-SQL在Ent-SQL-Bench基准测试上取得了91.48%的平均准确率,优于Claude 4.5 Sonnet和GPT-5等领先模型。
📝 摘要(中文)
本文提出了BAR-SQL(Boundary-Aware Reliable NL2SQL),一个统一的训练框架,将可靠性和边界感知直接嵌入到生成过程中。我们引入了一种种子突变数据合成范式,构建了一个具有代表性的企业语料库,显式地包含了多步骤分析查询以及包括歧义和模式限制在内的边界情况。为了确保可解释性,我们采用了知识驱动的推理合成,生成明确锚定于模式元数据和业务规则的Chain-of-Thought轨迹。该模型通过两阶段过程进行训练:监督式微调(SFT),然后是通过群体相对策略优化的强化学习。我们设计了一种任务条件混合奖励机制,该机制同时优化SQL执行准确性(利用抽象语法树分析和密集结果匹配)和拒绝回答中的语义精度。为了评估可靠性和生成准确性,我们构建并发布了Ent-SQL-Bench,它联合评估了SQL精度和跨歧义和无法回答的查询的边界感知拒绝回答。在该基准测试上的实验结果表明,BAR-SQL实现了91.48%的平均准确率,在SQL生成质量和边界感知拒绝回答能力方面均优于领先的专有模型,包括Claude 4.5 Sonnet和GPT-5。
🔬 方法详解
问题定义:论文旨在解决NL2SQL模型在企业级应用中面临的可靠性和边界感知问题。现有方法在处理复杂的多步骤分析查询、歧义查询以及模式限制查询时,准确率和鲁棒性不足,难以满足实际应用需求。此外,现有模型的可解释性较差,难以理解其推理过程。
核心思路:论文的核心思路是将可靠性和边界感知能力直接嵌入到NL2SQL模型的训练过程中。通过数据合成和混合奖励机制,使模型能够更好地处理复杂查询和边界情况,并在无法回答时进行有效拒绝。同时,利用知识驱动的推理合成,提高模型的可解释性。
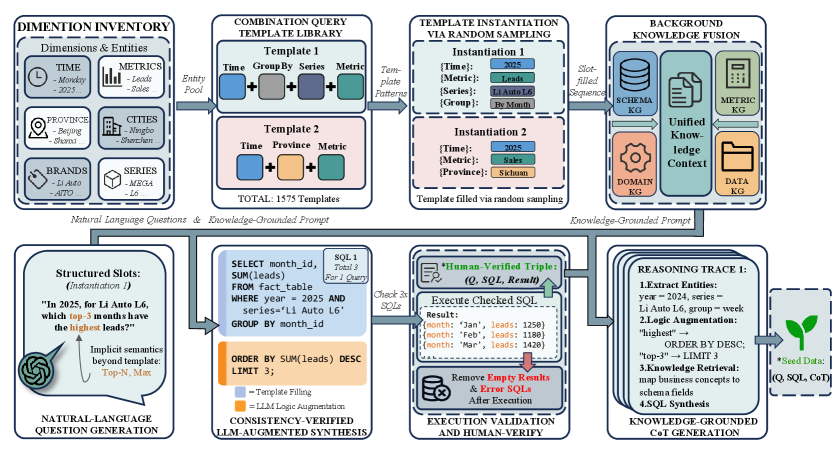
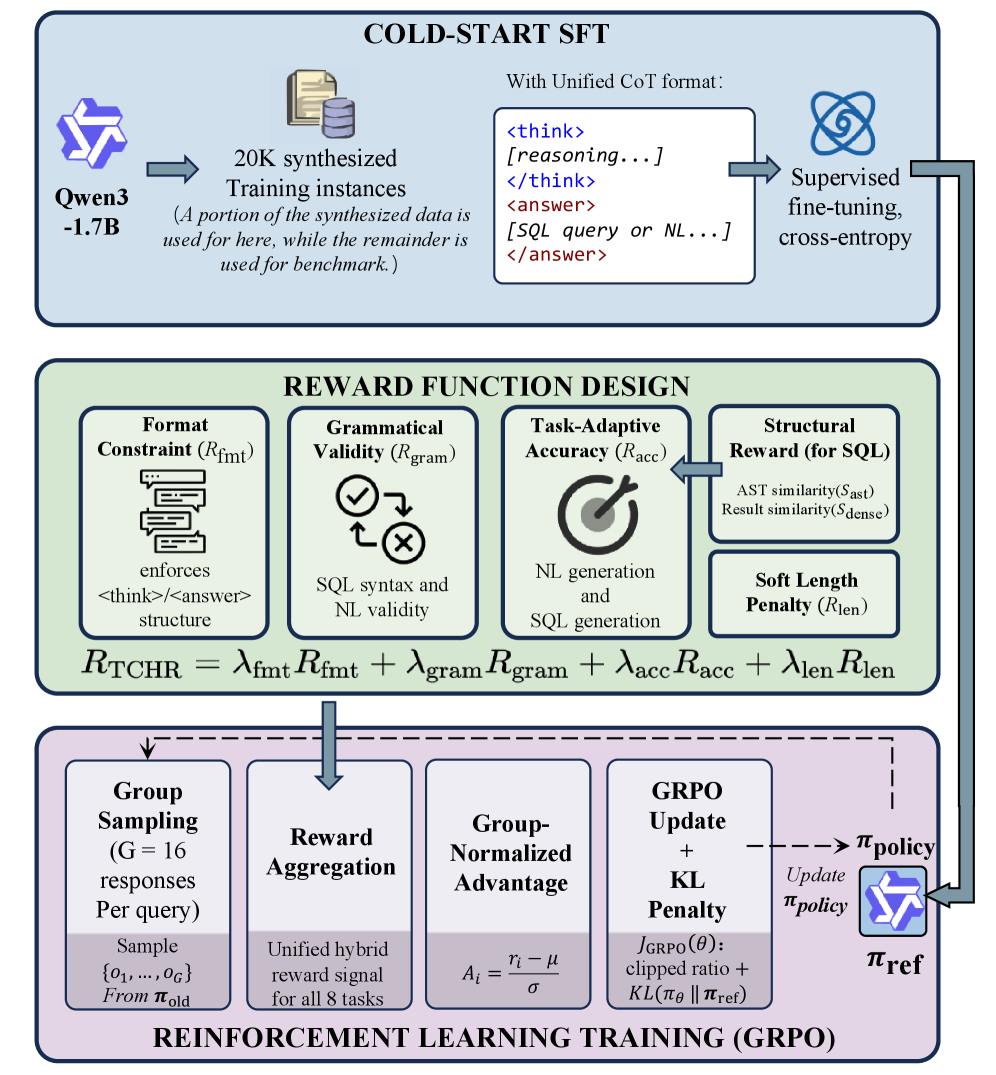
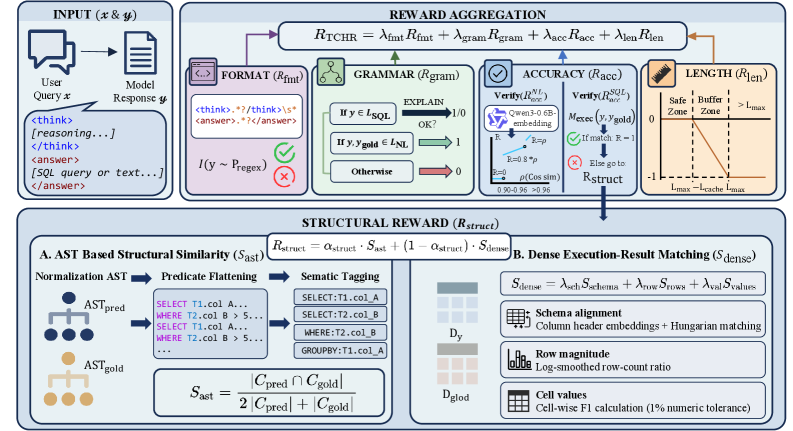
技术框架:BAR-SQL框架包含以下主要模块:1) 种子突变数据合成:生成包含多步骤分析查询和边界情况的企业语料库。2) 知识驱动的推理合成:生成Chain-of-Thought轨迹,提高模型可解释性。3) 两阶段训练:首先进行监督式微调(SFT),然后通过群体相对策略优化进行强化学习。4) 任务条件混合奖励机制:同时优化SQL执行准确性和拒绝回答的语义精度。
关键创新:论文的关键创新在于:1) 边界感知的数据合成方法:通过种子突变,生成包含歧义和模式限制等边界情况的数据,提升模型的鲁棒性。2) 知识驱动的推理合成:利用模式元数据和业务规则,生成可解释的Chain-of-Thought轨迹。3) 任务条件混合奖励机制:综合考虑SQL执行准确性和拒绝回答的语义精度,更有效地训练模型。
关键设计:在数据合成方面,采用了种子突变策略,通过对现有SQL查询进行修改,生成新的查询。在奖励函数设计方面,采用了混合奖励机制,综合考虑了SQL执行结果的准确性(通过抽象语法树分析和密集结果匹配)以及拒绝回答的合理性。强化学习阶段使用了Group Relative Policy Optimization,以提高训练效率和稳定性。具体参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
BAR-SQL在Ent-SQL-Bench基准测试上取得了91.48%的平均准确率,显著优于领先的专有模型,包括Claude 4.5 Sonnet和GPT-5。该结果表明,BAR-SQL在SQL生成质量和边界感知拒绝回答能力方面均具有优势。
🎯 应用场景
BAR-SQL框架可应用于企业级数据分析和智能问答系统,帮助用户通过自然语言查询数据库,获取所需信息。该研究成果能够提升NL2SQL模型的可靠性和边界感知能力,使其在复杂和不确定环境下更加稳定和准确,具有广泛的应用前景。
📄 摘要(原文)
In this paper, we present BAR-SQL (Boundary-Aware Reliable NL2SQL), a unified training framework that embeds reliability and boundary awareness directly into the generation process. We introduce a Seed Mutation data synthesis paradigm that constructs a representative enterprise corpus, explicitly encompassing multi-step analytical queries alongside boundary cases including ambiguity and schema limitations. To ensure interpretability, we employ Knowledge-Grounded Reasoning Synthesis, which produces Chain-of-Thought traces explicitly anchored in schema metadata and business rules. The model is trained through a two-stage process: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning via Group Relative Policy Optimization. We design a Task-Conditioned Hybrid Reward mechanism that simultaneously optimizes SQL execution accuracy-leveraging Abstract Syntax Tree analysis and dense result matching-and semantic precision in abstention responses. To evaluate reliability alongside generation accuracy, we construct and release Ent-SQL-Bench, which jointly assesse SQL precision and boundary-aware abstention across ambiguous and unanswerable queries. Experimental results on this benchmark demonstrate that BAR-SQL achieves 91.48% average accuracy, outperforming leading proprietary models, including Claude 4.5 Sonnet and GPT-5, in both SQL generation quality and boundary-aware abstention capability. The source code and benchmark are available anonymously at: https://github.com/TianSongS/BAR-SQL.