The Straight and Narrow: Do LLMs Possess an Internal Moral Path?
作者: Luoming Hu, Jingjie Zeng, Liang Yang, Hongfei Lin
分类: cs.CL
发布日期: 2026-01-15
💡 一句话要点
利用道德基础理论,通过干预LLM内部道德表征提升其道德对齐性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德对齐 道德基础理论 线性探测 自适应道德融合
📋 核心要点
- 现有LLM对齐方法主要依赖外部防护,忽略了模型内部道德表征,导致对齐效果受限。
- 论文提出利用道德基础理论,提取可控的道德向量,直接干预LLM的内部道德表征。
- 实验表明,该方法能有效减少LLM对良性查询的错误拒绝,并降低越狱攻击的成功率。
📝 摘要(中文)
增强大型语言模型(LLM)的道德对齐是人工智能安全的关键挑战。目前的对齐技术通常只起到表面上的防护作用,而LLM内在的道德表征在很大程度上未被触及。本文利用道德基础理论(MFT)来映射和操纵LLM的细粒度道德图景,从而弥合了这一差距。通过跨语言线性探测,验证了中间层道德表征的共享性,并揭示了英语和中文之间共享但不同的道德子空间。在此基础上,提取可操纵的道德向量,并在内部和行为层面成功验证了其有效性。利用道德的高度泛化性,提出自适应道德融合(AMF),这是一种动态的推理时干预,将探针检测与向量注入相结合,以解决安全性和帮助性之间的权衡。经验结果表明,与标准基线相比,我们的方法作为一种有针对性的内在防御,有效地减少了对良性查询的错误拒绝,同时最大限度地降低了越狱成功率。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)的道德对齐方法通常依赖于外部的规则和过滤机制,这些方法并不能真正改变LLM内部的道德表征。因此,LLM在面对复杂的道德困境时,仍然可能产生不符合道德规范的输出,并且容易受到对抗性攻击(如越狱攻击)。现有的方法缺乏对LLM内部道德观念的理解和有效干预手段。
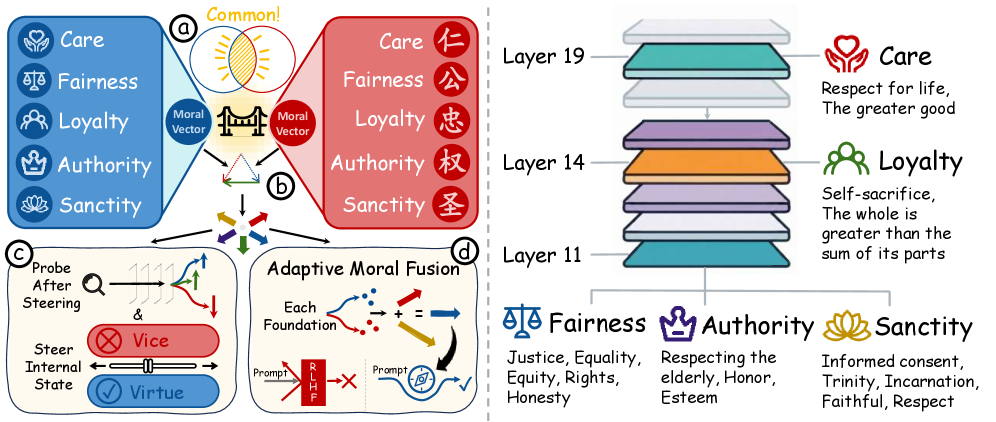
核心思路:本文的核心思路是利用道德基础理论(Moral Foundations Theory, MFT)来理解和操纵LLM内部的道德表征。MFT认为人类的道德观念可以分解为几个基本的道德维度。通过将LLM的内部状态映射到这些道德维度上,可以提取出代表特定道德观念的向量。然后,通过操纵这些道德向量,就可以在不改变LLM整体行为的前提下,有针对性地调整其道德倾向。
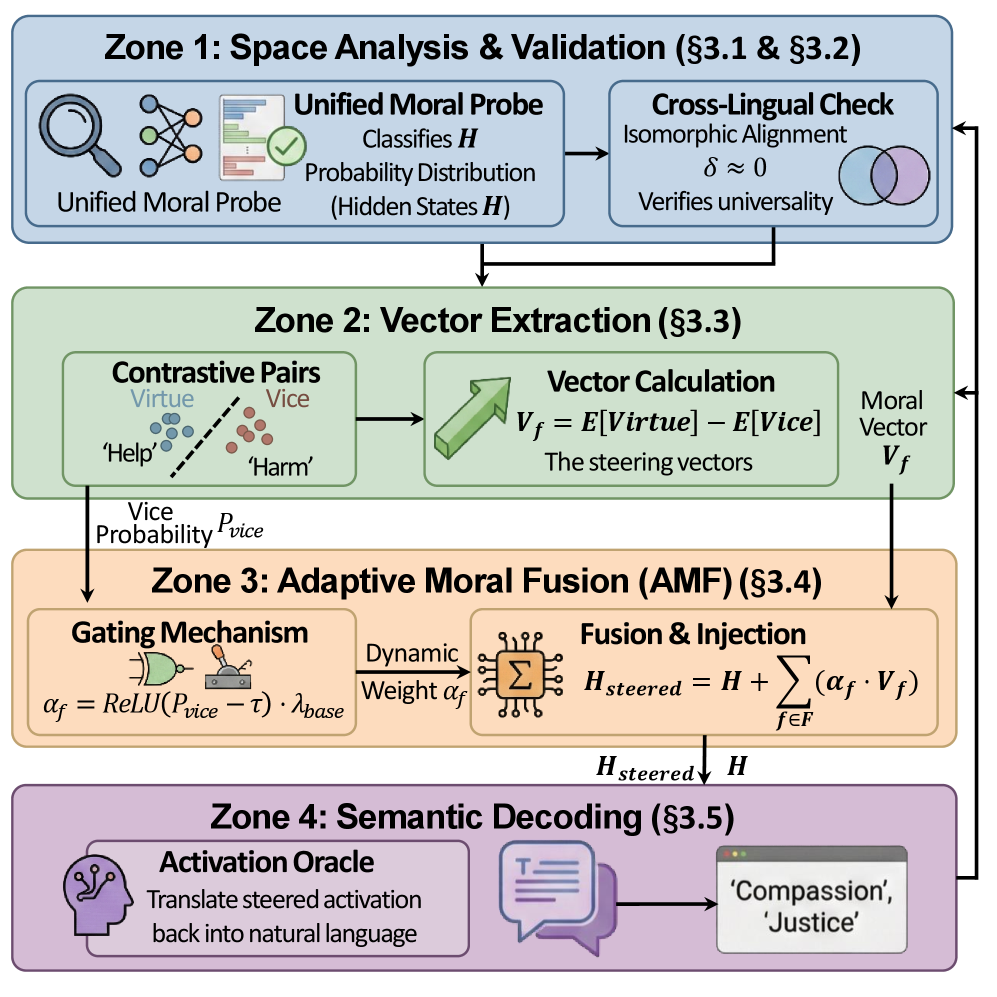
技术框架:该方法主要包含以下几个阶段:1) 道德表征探测:使用跨语言线性探测技术,在LLM的中间层寻找与MFT相关的道德表征。2) 道德向量提取:基于探测结果,提取代表不同道德维度的可操纵的道德向量。3) 自适应道德融合(AMF):在推理时,动态地检测输入文本的道德倾向,并注入相应的道德向量,从而调整LLM的输出。AMF旨在平衡安全性和帮助性,避免过度拒绝良性查询。
关键创新:该论文的关键创新在于:1) 将MFT应用于LLM的道德对齐:首次尝试利用MFT来理解和操纵LLM内部的道德表征。2) 提出自适应道德融合(AMF):AMF能够根据输入文本的道德倾向,动态地调整LLM的输出,从而在安全性和帮助性之间取得平衡。3) 跨语言道德表征的发现:验证了不同语言的LLM之间存在共享的道德表征。
关键设计:1) 线性探测:使用线性探测来寻找LLM中间层与MFT相关的神经元。探测器的训练目标是预测输入文本的道德标签。2) 道德向量的提取:通过计算探测器权重,提取代表不同道德维度的向量。3) AMF的动态调整:AMF使用一个分类器来检测输入文本的道德倾向,并根据检测结果动态地调整注入的道德向量的强度。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够有效降低LLM对良性查询的错误拒绝率,并显著降低越狱攻击的成功率。与基线方法相比,该方法在安全性和帮助性之间取得了更好的平衡。具体的性能提升数据未知,但论文强调了其在减少错误拒绝和抵抗越狱攻击方面的有效性。
🎯 应用场景
该研究成果可应用于提升LLM在各种场景下的道德安全性和可靠性,例如:智能客服、内容生成、教育辅导等。通过干预LLM的内部道德表征,可以减少其产生有害或不当内容的风险,并提高其在处理敏感话题时的判断能力。此外,该方法还可以用于评估和比较不同LLM的道德倾向,为模型的安全部署提供参考。
📄 摘要(原文)
Enhancing the moral alignment of Large Language Models (LLMs) is a critical challenge in AI safety. Current alignment techniques often act as superficial guardrails, leaving the intrinsic moral representations of LLMs largely untouched. In this paper, we bridge this gap by leveraging Moral Foundations Theory (MFT) to map and manipulate the fine-grained moral landscape of LLMs. Through cross-lingual linear probing, we validate the shared nature of moral representations in middle layers and uncover a shared yet different moral subspace between English and Chinese. Building upon this, we extract steerable Moral Vectors and successfully validate their efficacy at both internal and behavioral levels. Leveraging the high generalizability of morality, we propose Adaptive Moral Fusion (AMF), a dynamic inference-time intervention that synergizes probe detection with vector injection to tackle the safety-helpfulness trade-off. Empirical results confirm that our approach acts as a targeted intrinsic defense, effectively reducing incorrect refusals on benign queries while minimizing jailbreak success rates compared to standard baselines.