MoST: Mixing Speech and Text with Modality-Aware Mixture of Experts
作者: Yuxuan Lou, Kai Yang, Yang You
分类: cs.CL, cs.AI, cs.LG, cs.SD
发布日期: 2026-01-15
🔗 代码/项目: GITHUB
💡 一句话要点
MoST:通过模态感知专家混合模型融合语音和文本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 语音文本融合 专家混合模型 模态感知 大型语言模型
📋 核心要点
- 现有模型在处理语音和文本等多模态数据时,忽略了不同模态间固有的表示差异,导致性能瓶颈。
- MoST提出模态感知专家混合(MAMoE)架构,通过模态特定专家和共享专家,实现模态特定学习和跨模态理解。
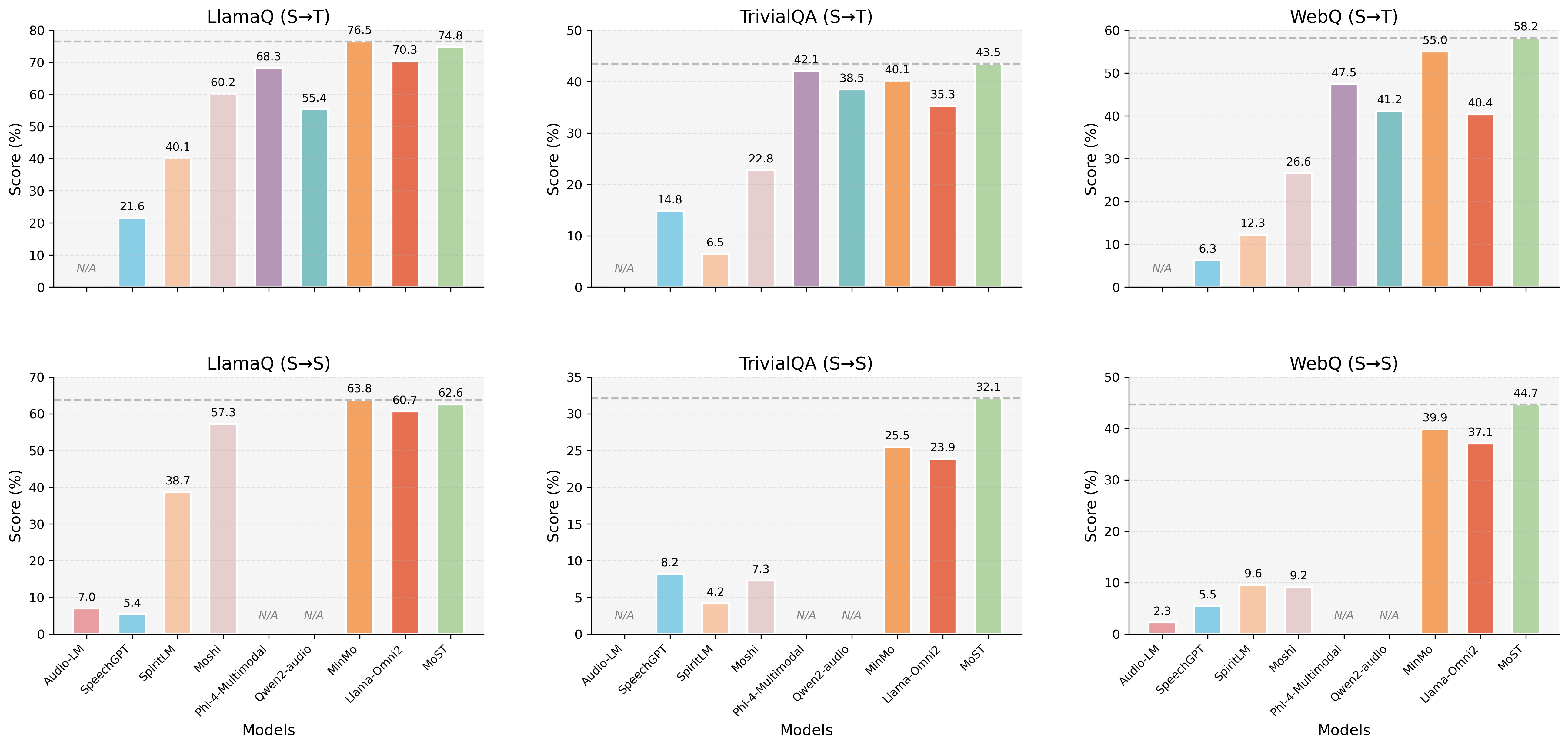
- 实验结果表明,MoST在ASR、TTS等任务上优于同等参数规模的模型,证明了模态特定路由机制和共享专家设计的有效性。
📝 摘要(中文)
本文提出了一种新颖的多模态大型语言模型MoST(语音和文本混合模型),它通过提出的模态感知专家混合(MAMoE)架构无缝集成了语音和文本处理。现有模型通常使用相同的参数处理不同的模态表示,忽略了它们固有的表示差异。MoST引入了专门的路由路径,根据输入类型将tokens导向模态适当的专家。MAMoE通过两个互补的组件同时增强了模态特定学习和跨模态理解:捕获领域特定模式的模态特定专家组和促进模态间信息传递的共享专家。在此架构的基础上,我们开发了一种高效的转换流程,通过在ASR和TTS数据集上进行战略性后训练来调整预训练的MoE语言模型,然后使用精心策划的语音-文本指令数据集进行微调。该流程的关键特性是它完全依赖于完全可访问的开源数据集来实现强大的性能和数据效率。在ASR、TTS、音频语言建模和口语问答基准上的综合评估表明,MoST始终优于参数数量相当的现有模型。消融研究证实,模态特定路由机制和共享专家设计显著提高了所有测试领域的性能。据我们所知,MoST代表了第一个完全开源的基于专家混合架构的语音-文本LLM。
🔬 方法详解
问题定义:现有的大型语言模型在处理多模态数据时,通常采用统一的参数处理不同模态的特征表示,忽略了语音和文本等模态之间固有的差异性。这种处理方式限制了模型对特定模态信息的有效学习和跨模态信息的充分融合,导致模型在语音识别、语音合成等任务上的性能提升受限。
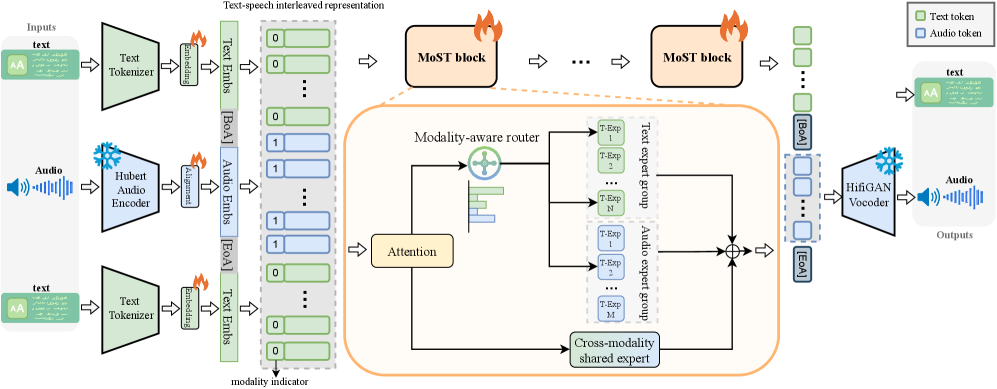
核心思路:MoST的核心思路是利用模态感知的专家混合(MAMoE)架构,为不同的模态分配不同的专家组,从而实现模态特定的学习。同时,引入共享专家来促进不同模态之间的信息交流和融合。通过这种方式,模型可以更好地捕捉不同模态的特征,并实现更有效的跨模态理解。
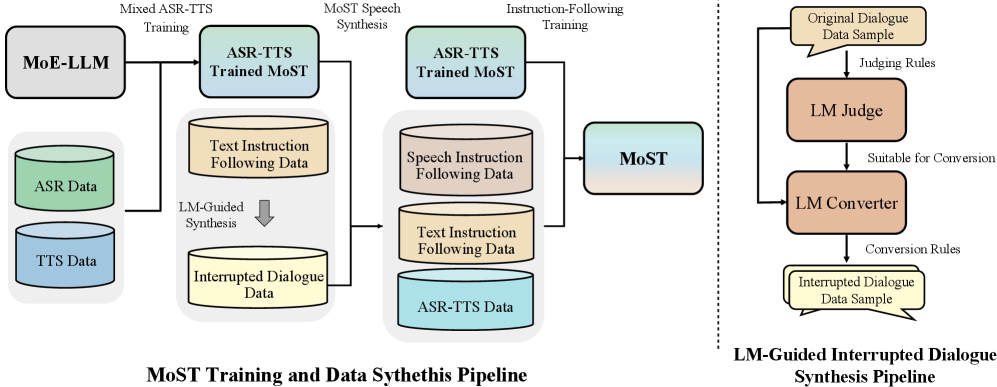
技术框架:MoST的整体架构基于Transformer模型,并引入了MAMoE模块。MAMoE模块包含模态特定专家组和共享专家组。输入tokens首先经过模态特定路由机制,被分配到相应的模态特定专家组进行处理。然后,所有tokens都会经过共享专家组,以实现跨模态信息的融合。最后,模型输出预测结果。训练流程包括三个阶段:首先,在ASR和TTS数据集上进行后训练,以增强模型对语音和文本模态的理解;然后,使用语音-文本指令数据集进行微调,以提升模型在特定任务上的性能。
关键创新:MoST的关键创新在于提出的模态感知专家混合(MAMoE)架构。与传统的专家混合模型不同,MAMoE能够根据输入模态的类型,将tokens路由到不同的专家组进行处理。这种模态特定的路由机制使得模型能够更好地捕捉不同模态的特征,从而提升模型的性能。此外,共享专家的设计也促进了不同模态之间的信息交流和融合。
关键设计:MAMoE模块中的专家数量、路由策略以及共享专家的比例是关键的设计参数。论文中可能采用了特定的损失函数来优化模态特定专家和共享专家的学习。具体的网络结构细节(如Transformer层数、隐藏层大小等)以及训练参数(如学习率、batch size等)未知,但这些参数的选择对模型的性能至关重要。
🖼️ 关键图片
📊 实验亮点
MoST在ASR、TTS、音频语言建模和口语问答等多个基准测试中,均优于参数规模相当的现有模型。消融实验表明,模态特定路由机制和共享专家设计对性能提升有显著贡献。MoST是首个完全开源的基于专家混合架构的语音-文本LLM。
🎯 应用场景
MoST具有广泛的应用前景,包括语音助手、智能客服、多模态对话系统等。它可以提升语音识别和语音合成的准确性和自然度,并支持更复杂的多模态交互。未来,MoST可以应用于教育、医疗等领域,例如开发智能语音辅导系统或辅助医生进行诊断。
📄 摘要(原文)
We present MoST (Mixture of Speech and Text), a novel multimodal large language model that seamlessly integrates speech and text processing through our proposed Modality-Aware Mixture of Experts (MAMoE) architecture. While current multimodal models typically process diverse modality representations with identical parameters, disregarding their inherent representational differences, we introduce specialized routing pathways that direct tokens to modality-appropriate experts based on input type. MAMoE simultaneously enhances modality-specific learning and cross-modal understanding through two complementary components: modality-specific expert groups that capture domain-specific patterns and shared experts that facilitate information transfer between modalities. Building on this architecture, we develop an efficient transformation pipeline that adapts the pretrained MoE language model through strategic post-training on ASR and TTS datasets, followed by fine-tuning with a carefully curated speech-text instruction dataset. A key feature of this pipeline is that it relies exclusively on fully accessible, open-source datasets to achieve strong performance and data efficiency. Comprehensive evaluations across ASR, TTS, audio language modeling, and spoken question answering benchmarks show that MoST consistently outperforms existing models of comparable parameter counts. Our ablation studies confirm that the modality-specific routing mechanism and shared experts design significantly contribute to performance gains across all tested domains. To our knowledge, MoST represents the first fully open-source speech-text LLM built on a Mixture of Experts architecture. \footnote{We release MoST model, training code, inference code, and training data at https://github.com/NUS-HPC-AI-Lab/MoST