Loop as a Bridge: Can Looped Transformers Truly Link Representation Space and Natural Language Outputs?
作者: Guanxu Chen, Dongrui Liu, Jing Shao
分类: cs.CL, cs.AI
发布日期: 2026-01-15
备注: 9 pages,6 figures
💡 一句话要点
研究循环Transformer能否通过迭代提升表征空间与自然语言输出的关联性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 循环Transformer 大型语言模型 表征学习 自然语言生成 知识表示 迭代学习 内省机制
📋 核心要点
- 大型语言模型内部知识与语言输出存在差距,难以有效利用内部表征。
- 研究循环Transformer的迭代特性,探索其作为内省机制,弥合知识与输出的潜力。
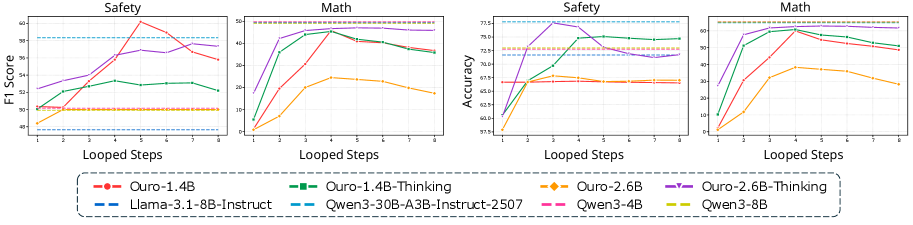
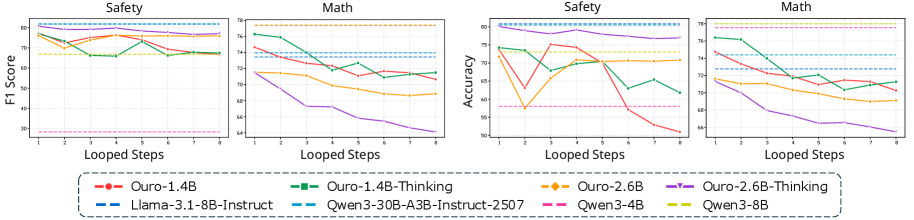
- 实验表明增加循环次数虽缩小差距,但伴随内部知识退化,且表征感知能力未随循环提升。
📝 摘要(中文)
大型语言模型(LLMs)常常表现出其内部知识与其显式语言输出之间的差距。本报告实证研究了循环Transformer(LTs)——通过迭代共享层来增加计算深度的架构——是否可以通过利用其迭代特性作为一种内省形式来弥合这一差距。我们的实验表明,虽然增加循环迭代次数缩小了差距,但这部分是由于其表征所携带的内部知识的退化所驱动的。此外,另一项实证分析表明,当前LTs感知表征的能力并没有随着循环次数的增加而提高;它只存在于最后一个循环中。这些结果表明,虽然LTs为扩展计算深度提供了一个有希望的方向,但它们尚未实现真正连接表征空间和自然语言所需的内省能力。
🔬 方法详解
问题定义:大型语言模型(LLMs)的内部知识与其最终的自然语言输出之间存在鸿沟。现有的Transformer模型难以充分利用其内部表征所蕴含的知识,导致输出结果可能与模型实际“知道”的内容不符。循环Transformer (LTs) 旨在通过迭代共享层来增加计算深度,期望通过多次迭代来更好地整合和提炼内部知识,从而弥合这一鸿沟。
核心思路:该论文的核心思路是将循环Transformer的迭代过程视为一种“内省”机制。通过多次循环,模型可以反复审视和修正其内部表征,从而更好地将内部知识与最终的语言输出对齐。作者假设,随着循环次数的增加,模型能够更有效地利用其内部表征,从而缩小知识与输出之间的差距。
技术框架:该研究主要基于现有的循环Transformer架构进行实验分析。具体而言,研究人员关注的是循环迭代次数对模型性能的影响。他们通过改变循环次数,并观察模型在不同任务上的表现,来评估循环Transformer的“内省”能力。实验中涉及的关键模块包括Transformer层、循环机制以及用于评估模型性能的指标。
关键创新:该论文的关键创新在于其对循环Transformer的“内省”能力的实证研究。以往的研究主要关注循环Transformer在提高模型性能方面的潜力,而该论文则深入探讨了循环迭代过程对模型内部表征和知识整合的影响。通过实验分析,论文揭示了循环Transformer在弥合知识与输出差距方面的局限性,并提出了未来研究的方向。
关键设计:实验设计主要围绕循环次数展开。研究人员通过改变循环次数,并观察模型在不同任务上的表现,来评估循环Transformer的“内省”能力。此外,研究人员还设计了专门的实验来评估模型在不同循环阶段感知表征的能力。具体的参数设置和损失函数等技术细节可能因不同的实验任务而有所不同,但核心目标都是评估循环迭代过程对模型内部表征和知识整合的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,增加循环Transformer的循环次数虽然可以在一定程度上缩小内部知识与语言输出之间的差距,但同时也伴随着内部知识的退化。更重要的是,实验发现循环Transformer感知表征的能力并没有随着循环次数的增加而提高,这种能力主要体现在最后一个循环中。这些发现揭示了当前循环Transformer在实现真正的“内省”能力方面存在的局限性。
🎯 应用场景
该研究成果对提升大型语言模型的可靠性和可解释性具有潜在应用价值。通过深入理解循环Transformer的内部工作机制,可以设计出更有效的模型架构,从而更好地利用模型内部知识,生成更准确、更符合人类意图的自然语言输出。此外,该研究还可以应用于对话系统、机器翻译等领域,提升这些应用的用户体验。
📄 摘要(原文)
Large Language Models (LLMs) often exhibit a gap between their internal knowledge and their explicit linguistic outputs. In this report, we empirically investigate whether Looped Transformers (LTs)--architectures that increase computational depth by iterating shared layers--can bridge this gap by utilizing their iterative nature as a form of introspection. Our experiments reveal that while increasing loop iterations narrows the gap, it is partly driven by a degradation of their internal knowledge carried by representations. Moreover, another empirical analysis suggests that current LTs' ability to perceive representations does not improve across loops; it is only present in the final loop. These results suggest that while LTs offer a promising direction for scaling computational depth, they have yet to achieve the introspection required to truly link representation space and natural language.