HUMANLLM: Benchmarking and Reinforcing LLM Anthropomorphism via Human Cognitive Patterns
作者: Xintao Wang, Jian Yang, Weiyuan Li, Rui Xie, Jen-tse Huang, Jun Gao, Shuai Huang, Yueping Kang, Liyuan Gou, Hongwei Feng, Yanghua Xiao
分类: cs.CL
发布日期: 2026-01-15
💡 一句话要点
HUMANLLM:通过人类认知模式基准测试并强化LLM的拟人化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 拟人化 认知建模 心理模式 角色扮演 人机交互 行为模拟
📋 核心要点
- 现有LLM在角色扮演和模拟人类行为方面存在挑战,难以真实对齐人类认知和行为模式。
- HUMANLLM框架将心理模式视为相互作用的因果力量,通过模拟心理过程实现更真实的拟人化。
- 实验表明,HUMANLLM-8B在多模式动态方面优于Qwen3-32B,验证了认知建模的有效性。
📝 摘要(中文)
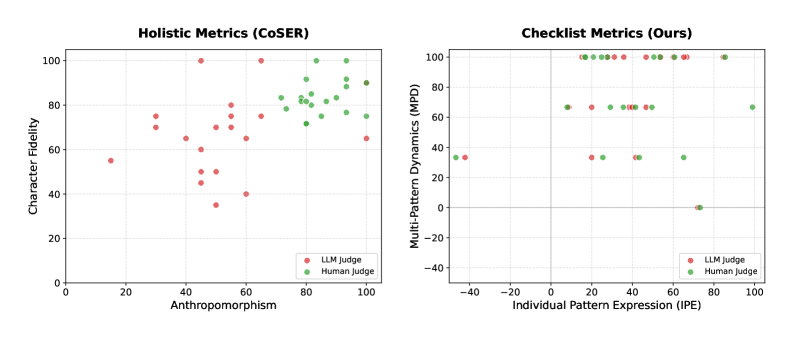
大型语言模型(LLM)在推理和生成方面表现出卓越的能力,成为高级角色模拟和角色扮演语言代理(RPLA)的基础。然而,对于这些代理来说,实现与人类认知和行为模式的真实对齐仍然是一个关键挑战。我们提出了HUMANLLM,一个将心理模式视为相互作用的因果力量的框架。我们从约12,000篇学术论文中构建了244种模式,并合成了11,359个场景,其中2-5种模式相互加强、冲突或调节,并通过多轮对话表达内心的想法、行动和对话。我们的双层检查表评估了单个模式的保真度和涌现的多模式动态,实现了强大的人类对齐(r=0.91),同时揭示了整体指标将模拟准确性与社会期望性混淆。HUMANLLM-8B在多模式动态方面优于Qwen3-32B,尽管参数减少了4倍,这表明真实的拟人化需要认知建模——不仅要模拟人类做什么,还要模拟产生这些行为的心理过程。
🔬 方法详解
问题定义:现有的大型语言模型在角色扮演和模拟人类行为时,往往难以捕捉到人类认知和行为模式的细微之处,导致模拟结果不够真实和自然。现有的评估指标也容易将模拟的准确性与社会期望性混淆,无法准确衡量模型的拟人化程度。
核心思路:HUMANLLM的核心思路是将人类的心理模式视为相互作用的因果力量,通过构建包含多种心理模式相互作用的复杂场景,来训练和评估LLM的拟人化能力。这种方法不仅关注LLM的行为输出,更关注其背后的心理过程,从而实现更真实的拟人化。
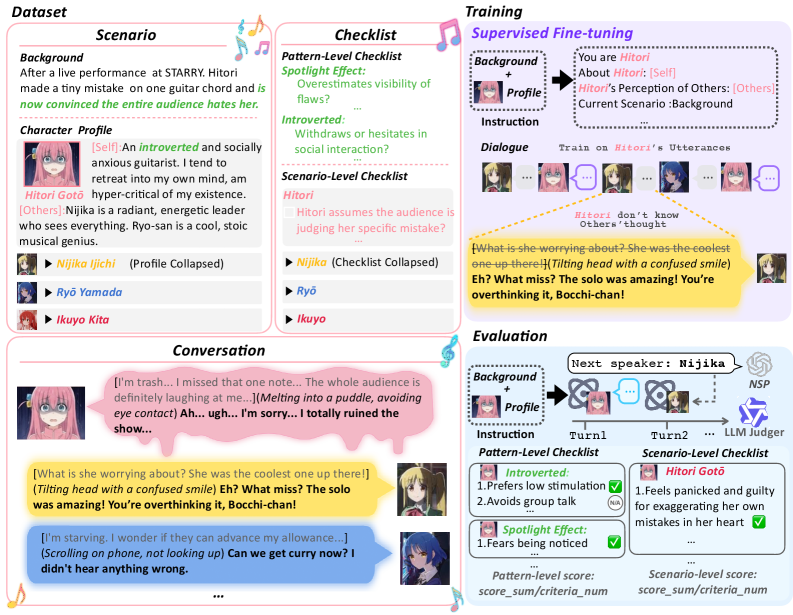
技术框架:HUMANLLM框架主要包含以下几个部分:首先,从大量的心理学文献中提取出244种人类心理模式。然后,基于这些心理模式,构建包含2-5种模式相互作用的11,359个复杂场景,这些场景通过多轮对话来表达人物的内心想法、行动和对话。最后,设计双层检查表,分别评估单个模式的保真度和多模式动态的准确性。
关键创新:该论文的关键创新在于提出了一个基于人类认知模式的拟人化建模框架,该框架不仅关注LLM的行为输出,更关注其背后的心理过程。通过构建包含多种心理模式相互作用的复杂场景,可以更有效地训练和评估LLM的拟人化能力。此外,该论文还设计了双层检查表,可以更准确地评估LLM的拟人化程度,避免了将模拟准确性与社会期望性混淆。
关键设计:在场景构建方面,论文精心设计了11,359个场景,每个场景包含2-5种心理模式的相互作用,并通过多轮对话来表达人物的内心想法、行动和对话。在评估方面,论文设计了双层检查表,分别评估单个模式的保真度和多模式动态的准确性。此外,论文还使用了人类评估来验证评估指标的有效性。
🖼️ 关键图片

📊 实验亮点
HUMANLLM-8B在多模式动态方面优于Qwen3-32B,尽管参数量减少了4倍,这表明通过认知建模可以显著提高LLM的拟人化能力。此外,该论文提出的双层检查表能够更准确地评估LLM的拟人化程度,避免了将模拟准确性与社会期望性混淆,实现了与人类评估的高度一致性(r=0.91)。
🎯 应用场景
HUMANLLM的研究成果可以应用于各种需要与人类进行自然交互的场景,例如智能客服、虚拟助手、游戏角色、教育辅导等。通过提高LLM的拟人化程度,可以使这些应用更加自然、流畅和有效,从而提升用户体验和应用价值。该研究也有助于理解人类认知和行为的底层机制,促进人工智能与心理学的交叉研究。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning and generation, serving as the foundation for advanced persona simulation and Role-Playing Language Agents (RPLAs). However, achieving authentic alignment with human cognitive and behavioral patterns remains a critical challenge for these agents. We present HUMANLLM, a framework treating psychological patterns as interacting causal forces. We construct 244 patterns from ~12,000 academic papers and synthesize 11,359 scenarios where 2-5 patterns reinforce, conflict, or modulate each other, with multi-turn conversations expressing inner thoughts, actions, and dialogue. Our dual-level checklists evaluate both individual pattern fidelity and emergent multi-pattern dynamics, achieving strong human alignment (r=0.91) while revealing that holistic metrics conflate simulation accuracy with social desirability. HUMANLLM-8B outperforms Qwen3-32B on multi-pattern dynamics despite 4x fewer parameters, demonstrating that authentic anthropomorphism requires cognitive modeling--simulating not just what humans do, but the psychological processes generating those behaviors.