HOMURA: Taming the Sand-Glass for Time-Constrained LLM Translation via Reinforcement Learning
作者: Ziang Cui, Mengran Yu, Tianjiao Li, Chenyu Shi, Yingxuan Shi, Lusheng Zhang, Hongwei Lin
分类: cs.CL, cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出HOMURA,通过强化学习解决LLM翻译中时间约束下的跨语言冗余问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 机器翻译 时间约束 大型语言模型 跨语言冗余 字幕生成 动态奖励
📋 核心要点
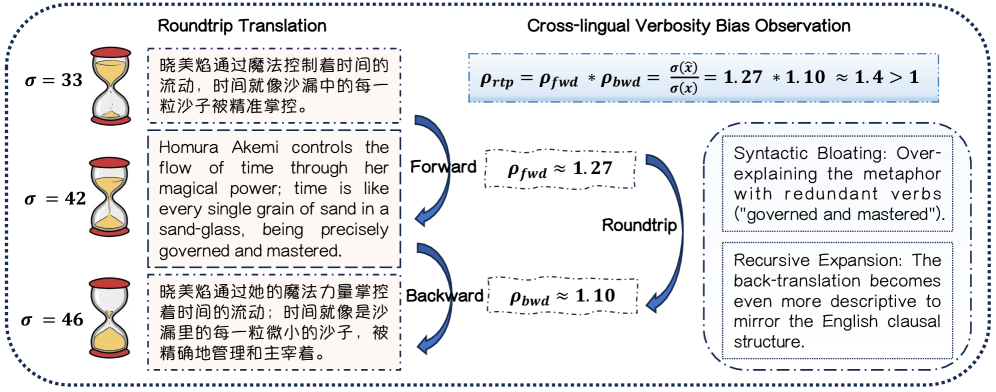
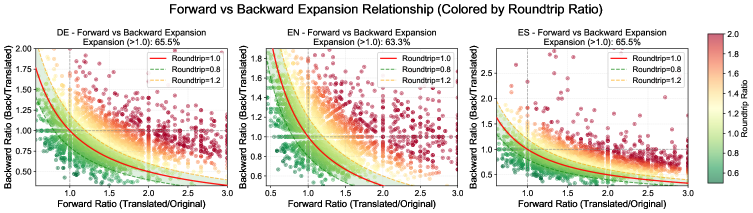
- 现有LLM翻译存在跨语言冗余偏差,不适用于字幕等时间敏感场景,提示工程难以兼顾语义和时限。
- HOMURA采用强化学习框架,通过KL正则化和动态音节比率奖励,优化语义保真度和时间一致性。
- 实验表明,HOMURA显著优于LLM基线,在保证语义的前提下,实现了精确的长度控制。
📝 摘要(中文)
大型语言模型(LLM)在多语言翻译方面取得了显著进展,但存在系统性的跨语言冗余偏差,使其不适用于字幕和配音等严格的时间约束任务。现有的提示工程方法难以解决语义保真度和严格时间可行性之间的冲突。为了弥合这一差距,我们首先引入了Sand-Glass,这是一个专门用于评估音节级时长约束下翻译的基准。此外,我们提出了HOMURA,一个强化学习框架,它显式地优化了语义保留和时间一致性之间的权衡。通过采用具有新颖的动态音节比率奖励的KL正则化目标,HOMURA有效地“驯服”了输出长度。实验结果表明,我们的方法显著优于强大的LLM基线,实现了精确的长度控制,在不影响语义充分性的前提下,尊重了语言密度等级。
🔬 方法详解
问题定义:LLM在多语言翻译中表现出色,但其固有的冗余性使其难以满足字幕、配音等对时间有严格约束的应用场景。现有方法,如提示工程,难以在保证翻译质量(语义保真度)的同时,满足时间约束(例如,音节数量限制)。因此,需要一种能够有效控制翻译长度,同时保持语义完整性的方法。
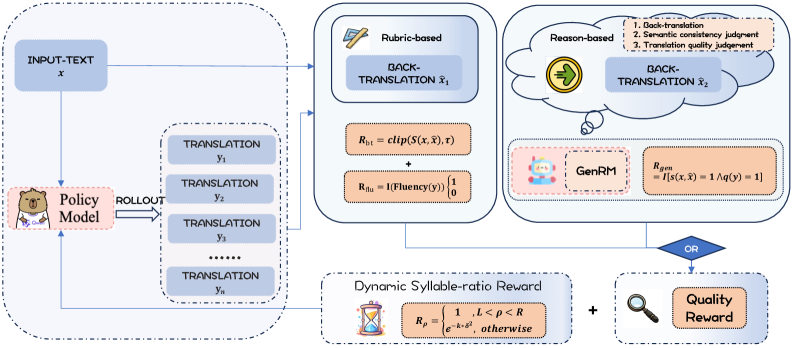
核心思路:HOMURA的核心思路是利用强化学习来优化翻译过程,使其在满足时间约束的同时,尽可能地保留原文的语义信息。通过将翻译过程建模为一个马尔可夫决策过程,并设计合适的奖励函数,HOMURA可以学习到一种策略,该策略能够在语义保真度和时间一致性之间取得平衡。
技术框架:HOMURA的整体框架包括以下几个主要模块:1) 环境(Environment):模拟翻译过程,接收Agent的动作(token),并返回下一个状态和奖励。2) Agent:基于LLM的翻译模型,负责生成翻译文本,并根据环境的反馈调整策略。3) 奖励函数(Reward Function):用于评估Agent生成的翻译文本的质量,包括语义保真度和时间一致性。4) 训练过程:使用强化学习算法(如PPO)训练Agent,使其能够生成满足时间约束且语义准确的翻译文本。
关键创新:HOMURA的关键创新在于:1) 引入了Sand-Glass基准,用于评估时间约束下的翻译性能。2) 提出了动态音节比率奖励,该奖励能够根据目标语言的语言密度动态调整,从而更好地控制翻译长度。3) 使用KL正则化来约束Agent的策略,防止其过度优化时间一致性而牺牲语义保真度。
关键设计:HOMURA的关键设计包括:1) 奖励函数:奖励函数由两部分组成:语义奖励和时间奖励。语义奖励用于评估翻译文本的语义保真度,可以使用BLEU、ROUGE等指标。时间奖励用于评估翻译文本的时间一致性,可以使用音节比率作为指标。动态音节比率奖励根据源语言和目标语言的音节密度进行调整,以适应不同语言的特点。2) KL正则化:KL正则化用于约束Agent的策略,防止其过度优化时间一致性而牺牲语义保真度。通过在奖励函数中加入KL散度项,可以鼓励Agent保持策略的稳定性,从而提高翻译质量。3) 强化学习算法:使用PPO算法训练Agent,PPO算法是一种常用的策略梯度算法,具有较好的稳定性和收敛性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HOMURA在Sand-Glass基准上显著优于强大的LLM基线。HOMURA能够实现精确的长度控制,在不影响语义充分性的前提下,尊重了语言密度等级。具体而言,HOMURA在时间一致性方面取得了显著提升,同时保持了较高的语义保真度。与现有方法相比,HOMURA能够更好地平衡语义保真度和时间一致性。
🎯 应用场景
HOMURA可应用于对时间有严格要求的机器翻译场景,如实时字幕生成、视频配音、同声传译等。该研究有助于提升LLM在资源受限环境下的应用能力,并为开发更高效、更实用的多语言翻译系统提供借鉴。未来,该方法有望扩展到其他自然语言处理任务,如文本摘要、对话生成等。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable strides in multilingual translation but are hindered by a systemic cross-lingual verbosity bias, rendering them unsuitable for strict time-constrained tasks like subtitling and dubbing. Current prompt-engineering approaches struggle to resolve this conflict between semantic fidelity and rigid temporal feasibility. To bridge this gap, we first introduce Sand-Glass, a benchmark specifically designed to evaluate translation under syllable-level duration constraints. Furthermore, we propose HOMURA, a reinforcement learning framework that explicitly optimizes the trade-off between semantic preservation and temporal compliance. By employing a KL-regularized objective with a novel dynamic syllable-ratio reward, HOMURA effectively "tames" the output length. Experimental results demonstrate that our method significantly outperforms strong LLM baselines, achieving precise length control that respects linguistic density hierarchies without compromising semantic adequacy.