Skill-Aware Data Selection and Fine-Tuning for Data-Efficient Reasoning Distillation
作者: Lechen Zhang, Yunxiang Zhang, Wei Hu, Lu Wang
分类: cs.CL
发布日期: 2026-01-15
💡 一句话要点
提出技能感知的数据选择与微调方法,实现数据高效的推理蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 推理蒸馏 数据选择 技能感知 监督微调 数学推理
📋 核心要点
- 现有推理模型蒸馏方法依赖大规模数据进行监督微调,数据效率低,成本高昂。
- 提出一种以技能为中心的蒸馏框架,通过技能选择数据和技能感知微调,提升数据效率。
- 实验表明,仅用少量数据,该方法在数学推理任务上显著超越随机选择数据的微调方法。
📝 摘要(中文)
大型推理模型(如DeepSeek-R1)及其蒸馏变体在复杂推理任务上表现出色。然而,蒸馏这些模型通常需要大规模数据进行监督微调(SFT),这促使人们寻求数据高效的训练方法。为了解决这个问题,我们提出了一个以技能为中心的蒸馏框架,该框架通过两个组成部分有效地将推理能力转移到较弱的模型:(1)基于技能的数据选择,优先选择针对学生模型较弱技能的示例;(2)技能感知微调,鼓励在问题解决过程中显式地进行技能分解。仅使用从10万个教师生成语料库中选择的1000个训练示例,我们的方法在五个数学推理基准测试中,超越了Qwen3-4B的随机SFT基线+1.6%,超越了Qwen3-8B的随机SFT基线+1.4%。进一步的分析证实,这些收益集中在训练期间强调的技能上,突出了以技能为中心的训练对于高效推理蒸馏的有效性。
🔬 方法详解
问题定义:论文旨在解决大型推理模型蒸馏过程中数据效率低下的问题。现有的监督微调(SFT)方法需要大量的训练数据才能将教师模型的推理能力有效地转移到学生模型,这增加了计算成本和数据收集的难度。尤其是在学生模型某些技能较弱的情况下,随机选择数据进行微调可能无法充分提升这些薄弱环节的能力。
核心思路:论文的核心思路是针对学生模型在不同技能上的表现差异,有选择性地挑选训练数据,并设计相应的微调策略。通过优先选择能够提升学生模型薄弱技能的训练样本,并鼓励模型在训练过程中显式地进行技能分解,从而实现数据高效的推理能力蒸馏。
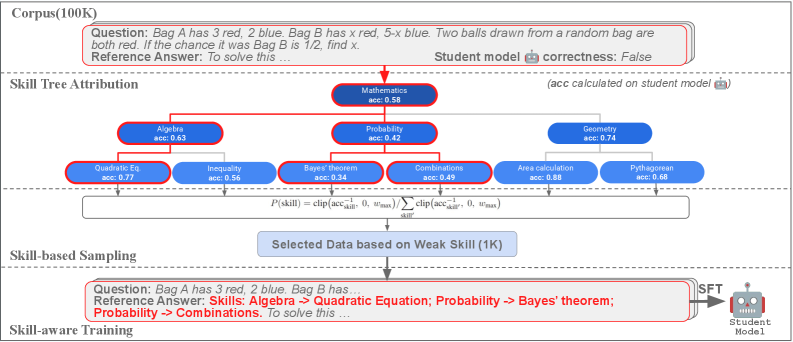
技术框架:该框架包含两个主要组成部分:(1)基于技能的数据选择:首先,评估学生模型在不同技能上的表现。然后,根据学生模型的薄弱技能,从教师模型生成的大规模数据集中选择相应的训练样本,优先选择能够提升这些薄弱技能的样本。(2)技能感知微调:在微调过程中,鼓励学生模型显式地进行技能分解。具体来说,可以设计特殊的损失函数或训练目标,促使模型在解决问题的过程中,能够识别并应用相关的技能。
关键创新:该方法最重要的创新点在于将技能的概念引入到推理模型的蒸馏过程中。通过对学生模型的技能进行评估,并有针对性地选择训练数据和设计微调策略,从而实现了数据高效的推理能力迁移。与传统的随机数据选择方法相比,该方法能够更有效地提升学生模型在特定技能上的表现。
关键设计:在技能评估方面,需要设计合适的指标来衡量学生模型在不同技能上的表现。在数据选择方面,可以采用基于技能的采样策略,例如优先选择那些能够提升学生模型薄弱技能的样本。在技能感知微调方面,可以设计特殊的损失函数,例如鼓励模型在解决问题的过程中,能够预测需要使用的技能,并对预测错误的技能进行惩罚。
🖼️ 关键图片
📊 实验亮点
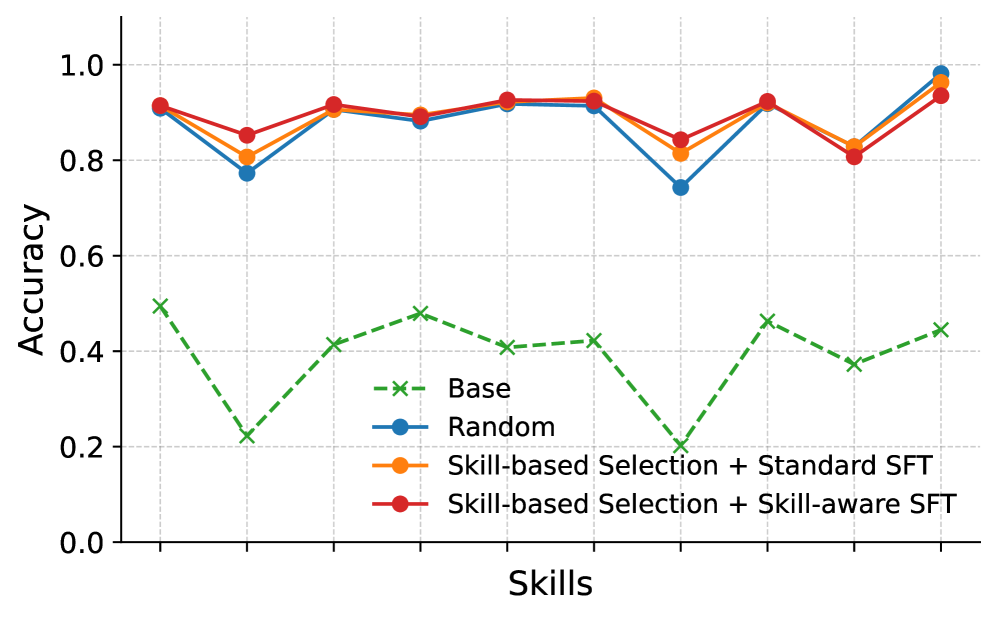
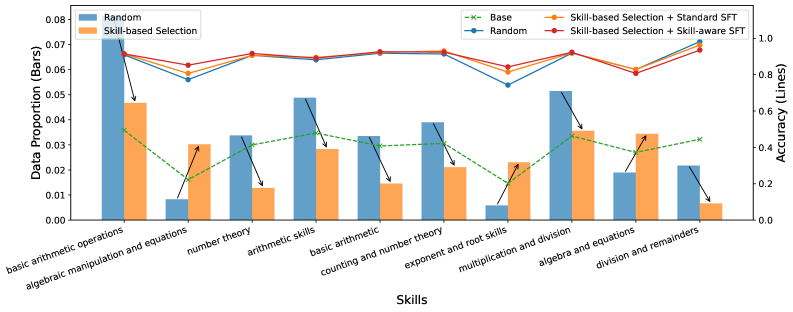
实验结果表明,仅使用1000个训练样本,该方法在五个数学推理基准测试中,超越了Qwen3-4B的随机SFT基线+1.6%,超越了Qwen3-8B的随机SFT基线+1.4%。分析表明,性能提升主要集中在训练期间强调的技能上,验证了该方法在提升特定技能方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。通过数据高效的蒸馏方法,可以将大型推理模型的强大能力迁移到资源受限的设备上,例如移动设备或嵌入式系统,从而实现更广泛的应用。
📄 摘要(原文)
Large reasoning models such as DeepSeek-R1 and their distilled variants achieve strong performance on complex reasoning tasks. Yet, distilling these models often demands large-scale data for supervised fine-tuning (SFT), motivating the pursuit of data-efficient training methods. To address this, we propose a skill-centric distillation framework that efficiently transfers reasoning ability to weaker models with two components: (1) Skill-based data selection, which prioritizes examples targeting the student model's weaker skills, and (2) Skill-aware fine-tuning, which encourages explicit skill decomposition during problem solving. With only 1,000 training examples selected from a 100K teacher-generated corpus, our method surpasses random SFT baselines by +1.6% on Qwen3-4B and +1.4% on Qwen3-8B across five mathematical reasoning benchmarks. Further analysis confirms that these gains concentrate on skills emphasized during training, highlighting the effectiveness of skill-centric training for efficient reasoning distillation.