SIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
作者: Yiming Ren, Junjie Wang, Yuxin Meng, Yihang Shi, Zhiqiang Lin, Ruihang Chu, Yiran Xu, Ziming Li, Yunfei Zhao, Zihan Wang, Yu Qiao, Ruiming Tang, Minghao Liu, Yujiu Yang
分类: cs.CL, cs.AI, cs.MM
发布日期: 2026-01-15
💡 一句话要点
提出FITO范式以解决多模态科学文献理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态理解 科学文献 证据链 长篇文本 模型评估 跨模态融合 人工智能
📋 核心要点
- 现有方法在评估多模态大语言模型理解长篇科学论文时存在不足,无法有效要求因果推理和证据链构建。
- 论文提出FITO范式,要求模型在科学文献中构建跨模态证据链,并通过SIN-Data和SIN-Bench实现这一目标。
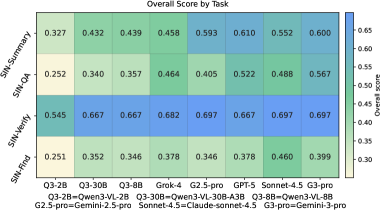
- 实验结果表明,Gemini-3-pro在整体评分上表现最佳,而GPT-5在问答准确性上最高,但在证据对齐评分上表现不佳,揭示了正确性与可追溯支持之间的差距。
📝 摘要(中文)
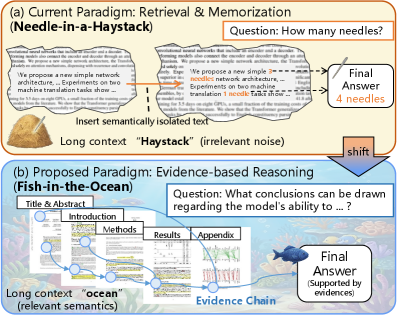
评估多模态大语言模型是否真正理解长篇科学论文仍然具有挑战性:仅依赖答案匹配的指标和合成的“针在干草堆中”测试往往无法要求文档中的因果、证据链接推理。我们提出了“海洋中的鱼”(FITO)范式,要求模型在原生科学文献中构建明确的跨模态证据链。为实现FITO,我们构建了SIN-Data,一个保留文本和图形原生交错的科学交错语料库,并在此基础上构建了SIN-Bench,涵盖证据发现、假设验证、基于证据的问答和证据锚定综合四个渐进任务。我们进一步引入了“无证据,无分数”的评分机制,通过与可验证锚点的匹配、相关性和逻辑来诊断证据质量。
🔬 方法详解
问题定义:本论文旨在解决多模态大语言模型在理解长篇科学文献时的局限性,现有方法往往无法有效评估模型的因果推理能力和证据链构建能力。
核心思路:提出FITO范式,要求模型在原生科学文献中构建明确的跨模态证据链,以增强模型的推理能力和理解深度。
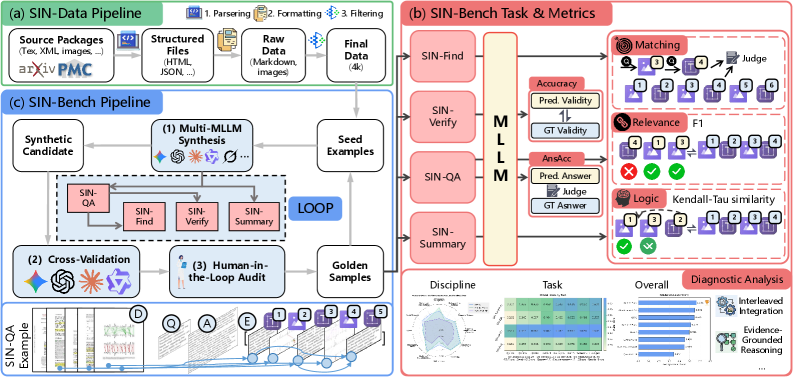
技术框架:整体架构包括SIN-Data语料库的构建,保留文本与图形的原生交错,以及SIN-Bench的四个任务模块:证据发现(SIN-Find)、假设验证(SIN-Verify)、基于证据的问答(SIN-QA)和证据锚定综合(SIN-Summary)。
关键创新:引入“无证据,无分数”的评分机制,强调模型预测的可验证性,诊断证据质量的匹配、相关性和逻辑性,显著区别于传统的答案匹配方法。
关键设计:在模型训练中,设置了针对证据链构建的损失函数,优化网络结构以增强跨模态信息的融合能力,同时设计了多层次的评估指标以全面评估模型性能。
🖼️ 关键图片
📊 实验亮点
实验结果显示,Gemini-3-pro在整体评分上达到了0.573的最佳平均分,而GPT-5在SIN-QA问答准确性上达到了0.767,尽管在证据对齐的整体评分上表现不佳,揭示了模型在正确性与证据支持之间的差距。
🎯 应用场景
该研究的潜在应用领域包括科学文献的自动分析、智能问答系统以及科研辅助工具等。通过提升模型对长篇科学文献的理解能力,能够为研究人员提供更高效的信息检索和知识获取方式,推动科学研究的进展。
📄 摘要(原文)
Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.