Long-Chain Reasoning Distillation via Adaptive Prefix Alignment
作者: Zhenghao Liu, Zhuoyang Wu, Xinze Li, Yukun Yan, Shuo Wang, Zulong Chen, Yu Gu, Ge Yu, Maosong Sun
分类: cs.CL
发布日期: 2026-01-15
🔗 代码/项目: GITHUB
💡 一句话要点
提出自适应前缀对齐蒸馏方法P-ALIGN,提升小模型长链推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长链推理 知识蒸馏 自适应前缀对齐 数学推理 大型语言模型 思维链 模型压缩
📋 核心要点
- 现有方法难以让小模型有效学习大型语言模型生成的过长且复杂的推理轨迹。
- P-ALIGN通过自适应截断教师模型推理轨迹,并对齐前缀,来提升蒸馏效果。
- 实验表明,P-ALIGN在数学推理任务上显著优于现有基线方法,提升超过3%。
📝 摘要(中文)
大型语言模型(LLMs)在复杂数学问题求解中展现了卓越的推理能力。最近的研究表明,蒸馏长推理轨迹可以有效提升小规模学生模型的推理性能。然而,教师模型生成的推理轨迹通常过长且结构复杂,使得学生模型难以学习。这种不匹配导致了监督信号与学生模型学习能力之间的差距。为了解决这一挑战,我们提出了前缀对齐蒸馏(P-ALIGN)框架,通过自适应前缀对齐充分利用教师模型的思维链(CoT)进行蒸馏。具体来说,P-ALIGN通过判断剩余后缀是否简洁且足以指导学生模型,自适应地截断教师模型生成的推理轨迹。然后,P-ALIGN利用教师模型生成的前缀来监督学生模型,鼓励有效的前缀对齐。在多个数学推理基准上的实验表明,P-ALIGN优于所有基线3%以上。进一步的分析表明,P-ALIGN构建的前缀提供了更有效的监督信号,同时避免了冗余和不确定推理组件的负面影响。所有代码均可在https://github.com/NEUIR/P-ALIGN获取。
🔬 方法详解
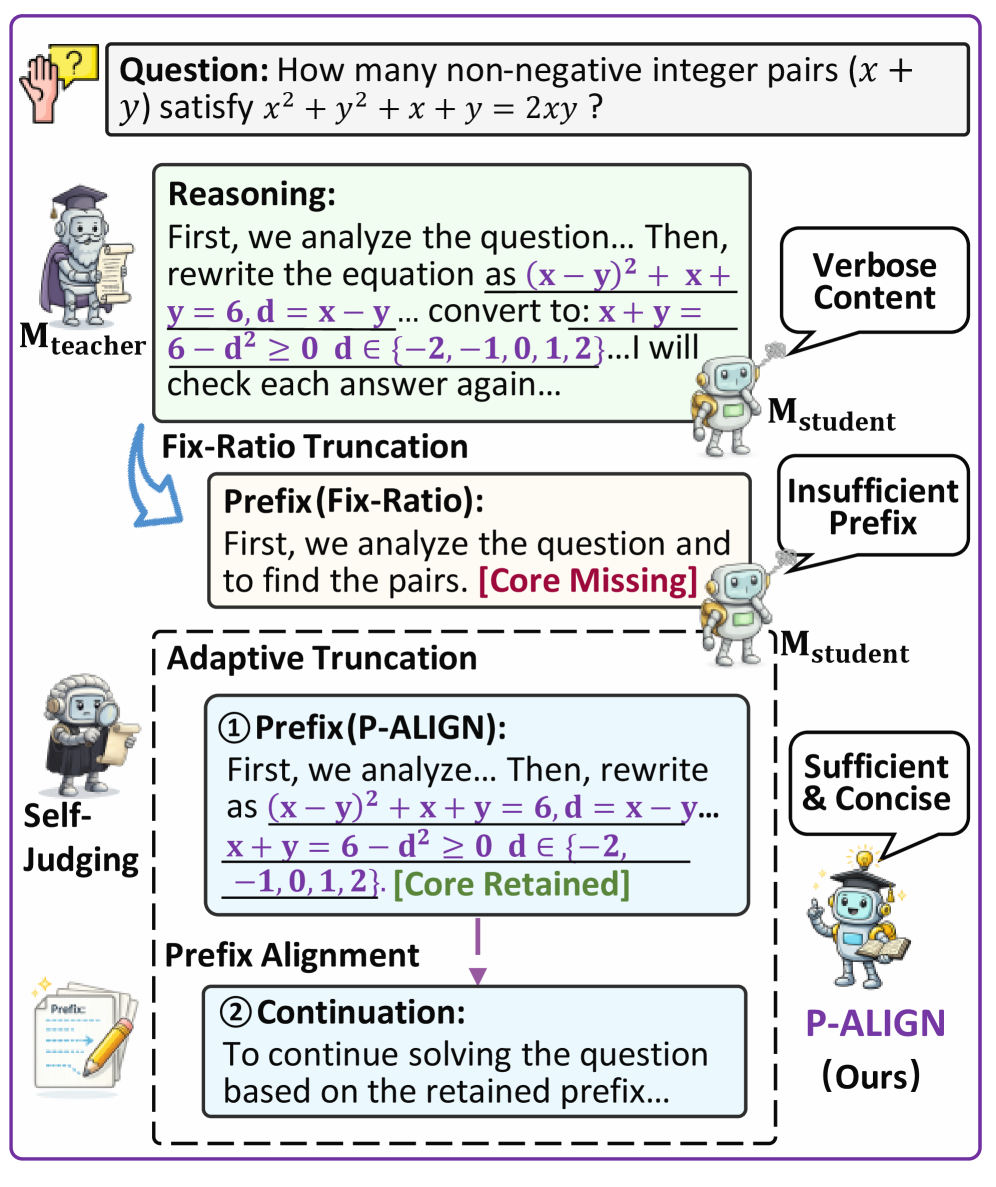
问题定义:论文旨在解决将大型语言模型(LLMs)的推理能力迁移到小型学生模型时,由于教师模型生成的推理轨迹过长和复杂,导致学生模型难以有效学习的问题。现有方法直接蒸馏完整的推理轨迹,忽略了学生模型的学习能力有限,容易受到冗余和不确定推理步骤的干扰。
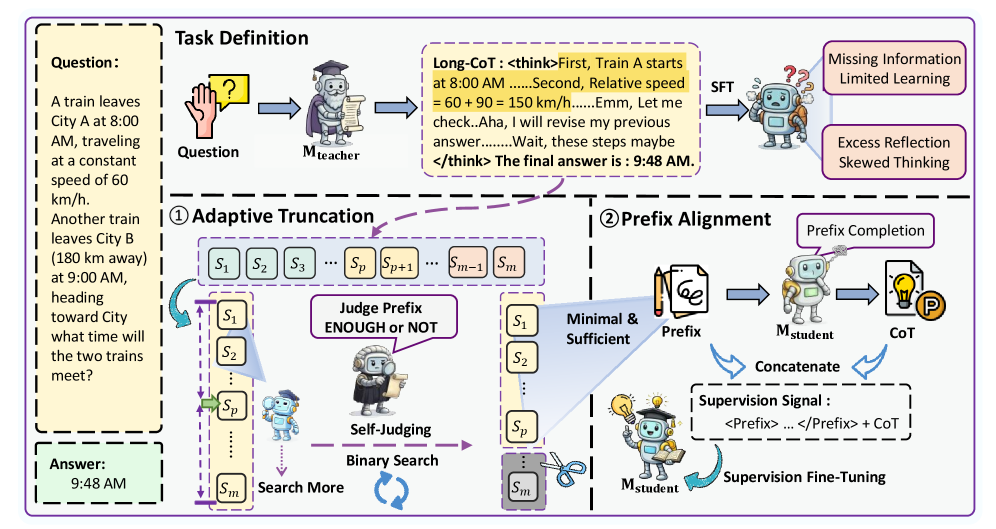
核心思路:论文的核心思路是自适应地截断教师模型生成的推理轨迹,只保留对学生模型学习最有帮助的前缀部分。通过判断剩余后缀是否简洁且足以指导学生模型,动态地选择最佳的前缀长度。然后,利用这个前缀来监督学生模型,鼓励学生模型学习教师模型的推理过程。
技术框架:P-ALIGN框架主要包含两个阶段:1) 自适应前缀选择:根据教师模型生成的完整推理轨迹,评估不同长度的前缀对学生模型的指导意义,选择最优的前缀。2) 前缀对齐蒸馏:利用选择好的前缀作为监督信号,训练学生模型,使其能够生成与教师模型相似的推理过程。
关键创新:P-ALIGN的关键创新在于提出了自适应前缀对齐的蒸馏方法。与以往直接蒸馏完整推理轨迹的方法不同,P-ALIGN能够根据学生模型的学习能力,动态地选择最有用的推理片段进行学习,从而提高蒸馏效率和效果。这种方法能够避免冗余和不确定推理步骤对学生模型的干扰。
关键设计:P-ALIGN的关键设计包括:1) 前缀选择策略:使用某种指标(例如,基于困惑度或奖励)来评估不同长度的前缀对学生模型的指导意义。2) 损失函数:设计合适的损失函数,鼓励学生模型生成与教师模型前缀相似的推理过程。损失函数可以包括交叉熵损失、KL散度等。3) 截断阈值:设置一个阈值来判断剩余后缀是否简洁且足以指导学生模型,从而决定是否截断推理轨迹。
🖼️ 关键图片
📊 实验亮点
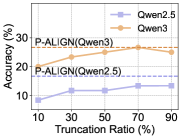
实验结果表明,P-ALIGN在多个数学推理基准上显著优于现有基线方法,性能提升超过3%。这表明P-ALIGN能够更有效地利用教师模型的推理轨迹,为学生模型提供更有效的监督信号。分析表明,P-ALIGN选择的前缀能够避免冗余和不确定推理组件的负面影响,从而提高蒸馏效果。
🎯 应用场景
该研究成果可应用于各种需要长链推理能力的场景,例如数学问题求解、知识图谱推理、代码生成等。通过将大型语言模型的推理能力迁移到小型模型,可以在资源受限的设备上实现高效的推理,具有广泛的应用前景和实际价值。未来可以进一步探索更有效的自适应前缀选择策略和蒸馏方法,提升小模型的推理能力。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in solving complex mathematical problems. Recent studies show that distilling long reasoning trajectories can effectively enhance the reasoning performance of small-scale student models. However, teacher-generated reasoning trajectories are often excessively long and structurally complex, making them difficult for student models to learn. This mismatch leads to a gap between the provided supervision signal and the learning capacity of the student model. To address this challenge, we propose Prefix-ALIGNment distillation (P-ALIGN), a framework that fully exploits teacher CoTs for distillation through adaptive prefix alignment. Specifically, P-ALIGN adaptively truncates teacher-generated reasoning trajectories by determining whether the remaining suffix is concise and sufficient to guide the student model. Then, P-ALIGN leverages the teacher-generated prefix to supervise the student model, encouraging effective prefix alignment. Experiments on multiple mathematical reasoning benchmarks demonstrate that P-ALIGN outperforms all baselines by over 3%. Further analysis indicates that the prefixes constructed by P-ALIGN provide more effective supervision signals, while avoiding the negative impact of redundant and uncertain reasoning components. All code is available at https://github.com/NEUIR/P-ALIGN.