LLMs can Compress LLMs: Adaptive Pruning by Agents
作者: Sai Varun Kodathala, Rakesh Vunnam
分类: cs.CL, cs.AI, cs.CV
发布日期: 2026-01-14
备注: 17 Pages
💡 一句话要点
提出Agent引导的自适应剪枝方法,利用LLM压缩LLM,提升知识保留率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型剪枝 自适应剪枝 知识保留 LLM压缩
📋 核心要点
- 现有LLM剪枝方法依赖手工启发式规则确定每层稀疏度,导致剪枝后模型的事实知识严重退化。
- 提出Agent引导的剪枝方法,利用LLM作为agent,自适应选择剪枝层,并结合权重激活和梯度信息构建敏感度分析。
- 实验表明,该方法在Qwen3模型上实现了显著的性能提升,尤其是在事实知识保留方面,且无需重新训练。
📝 摘要(中文)
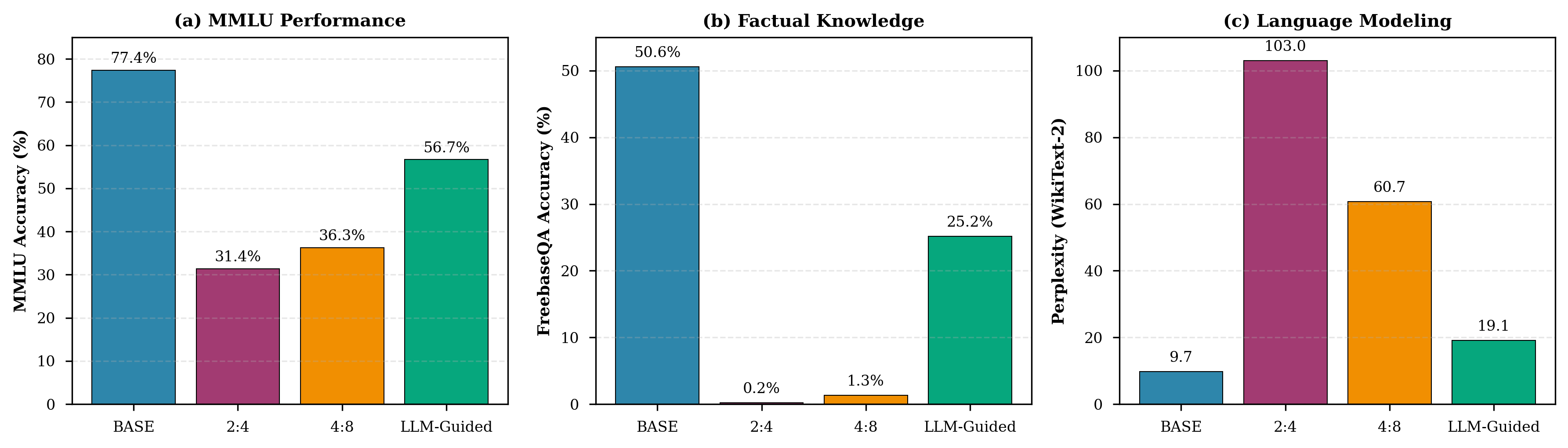
随着大型语言模型(LLMs)规模的持续增长,后训练剪枝已成为一种有前景的降低计算成本同时保持性能的方法。现有的方法,如SparseGPT和Wanda,通过逐层权重重建或激活感知的幅度剪枝来实现高稀疏性,但依赖于统一的或手工设计的启发式方法来确定每层的稀疏比例。此外,最近的研究表明,剪枝后的LLMs会遭受严重的事实知识退化,其中结构化剪枝方法在事实问答能力方面几乎完全崩溃。我们引入了agent引导的剪枝,其中基础模型充当自适应剪枝agent,以智能地选择在每次迭代中要剪枝的层,同时保留关键的知识路径。我们的方法通过将Wanda启发的权重-激活指标与梯度重要性分数相结合来构建逐层敏感性配置文件,并将其标准化为z-score以进行模型无关的比较。这些统计数据由具有自我反思能力的LLM agent处理,使其能够从先前的剪枝结果中学习并迭代地改进其策略。检查点回滚机制通过在困惑度退化超过阈值时恢复来维持模型质量。我们在Qwen3模型(4B和8B参数)上以大约45%的稀疏度评估了我们的方法,证明了相对于结构化剪枝基线的显着改进:MMLU准确率相对提高了56%,FreebaseQA上的事实知识保留率提高了19倍,困惑度退化降低了69%。值得注意的是,我们的框架不需要重新训练,以模型无关的方式运行,并且仅需2-4次回滚即可在21-40次迭代中表现出有效的自我纠正,这表明基础模型可以有效地指导其他基础模型的压缩。
🔬 方法详解
问题定义:现有LLM剪枝方法,如SparseGPT和Wanda,通常采用静态或手工设计的启发式规则来确定每层的剪枝比例,忽略了不同层对模型性能和知识保留的不同重要性。结构化剪枝尤其容易导致事实知识的严重退化,限制了剪枝后模型的可用性。
核心思路:论文的核心思路是利用大型语言模型(LLM)自身的推理和学习能力,让其作为agent,根据模型的当前状态和剪枝反馈,自适应地选择要剪枝的层。通过这种方式,可以更智能地平衡模型大小和性能,同时最大限度地保留关键知识。
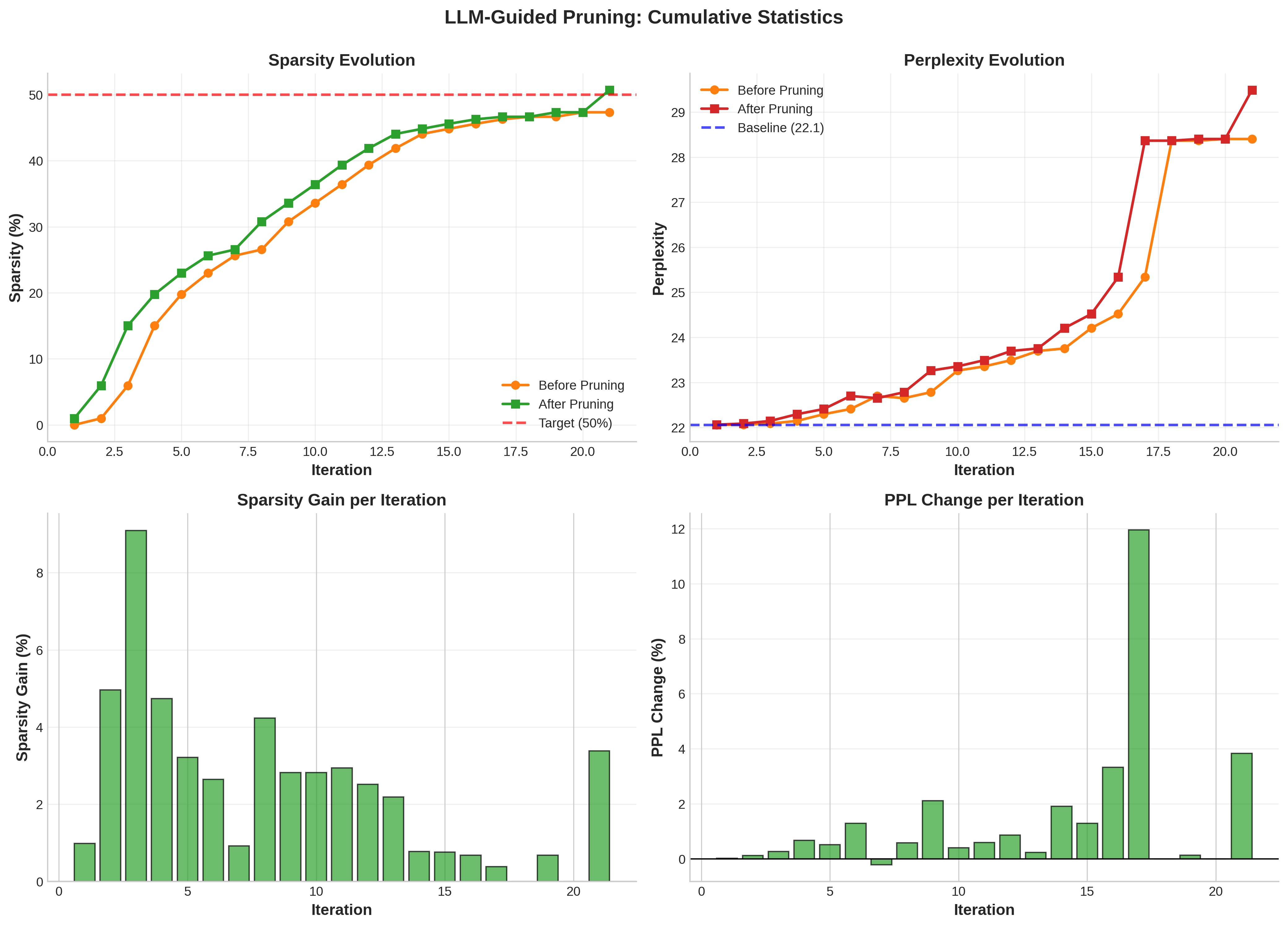
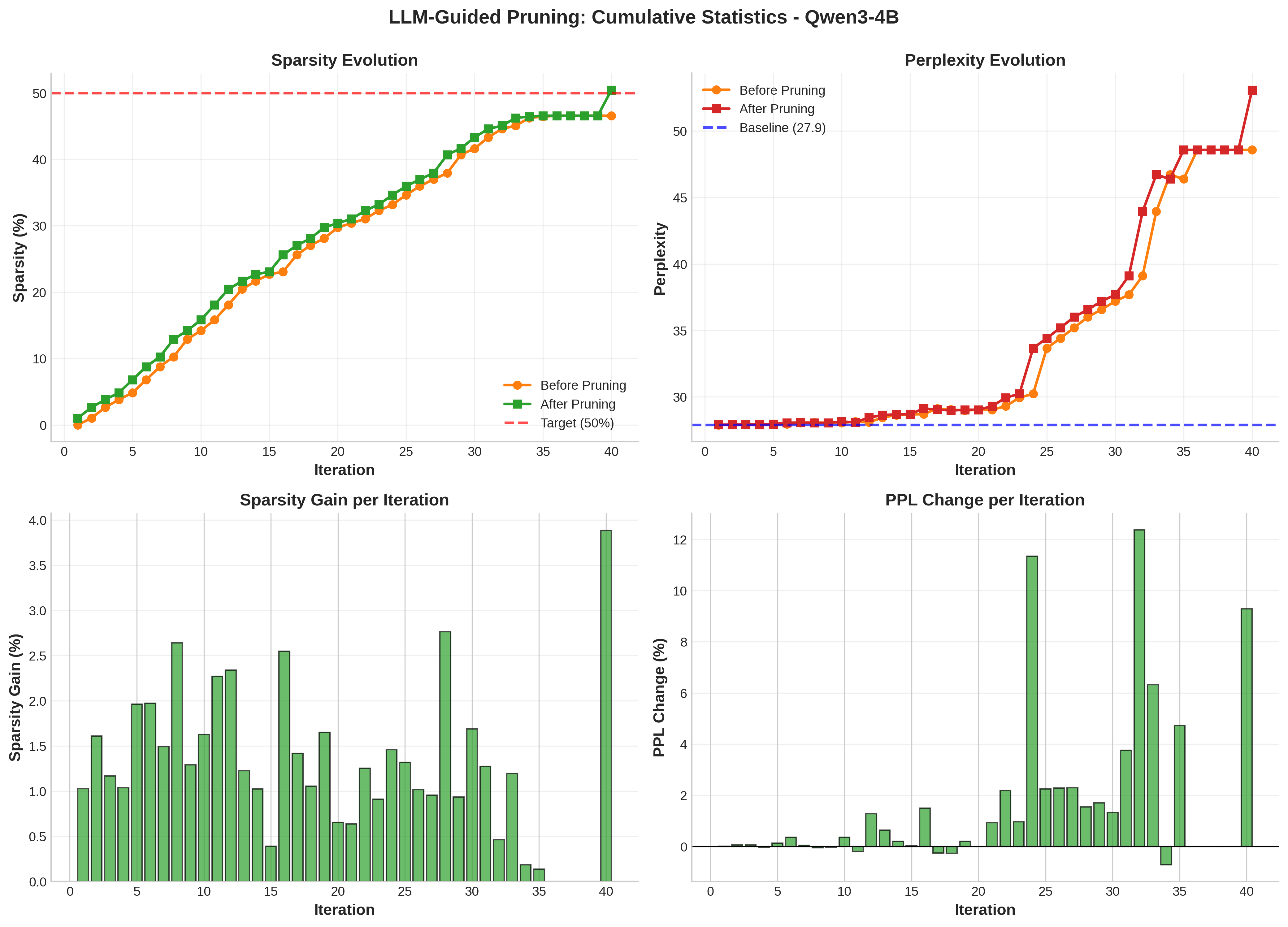
技术框架:该方法的核心是一个agent引导的剪枝框架,主要包括以下几个阶段:1) 敏感度分析:计算每一层的敏感度得分,结合Wanda启发的权重-激活指标和梯度重要性分数。2) Agent决策:使用LLM agent处理这些敏感度得分,agent具备自我反思能力,可以从之前的剪枝结果中学习,并决定当前迭代中要剪枝的层。3) 剪枝执行:根据agent的决策,对选定的层进行剪枝。4) 性能评估与回滚:评估剪枝后的模型性能(困惑度),如果性能下降超过阈值,则回滚到之前的检查点。这个过程迭代进行,直到达到目标稀疏度或满足其他停止条件。
关键创新:最重要的技术创新点在于使用LLM作为剪枝agent,使其能够根据模型的具体情况和剪枝反馈,动态调整剪枝策略。这与传统的静态剪枝方法形成了鲜明对比,后者通常采用固定的启发式规则,无法适应不同模型的特性。
关键设计:1) 敏感度得分计算:结合Wanda的权重-激活指标和梯度重要性,并进行z-score标准化,使得不同层的敏感度得分具有可比性。2) Agent的Prompt设计:设计合适的prompt,引导LLM agent进行有效的决策,包括提供模型的当前状态、之前的剪枝结果和性能反馈。3) 回滚机制:设置困惑度下降阈值,当性能下降超过该阈值时,回滚到之前的检查点,避免过度剪枝导致模型崩溃。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在Qwen3模型(4B和8B)上实现了显著的性能提升。在45%的稀疏度下,MMLU准确率相对提高了56%,FreebaseQA上的事实知识保留率提高了19倍,困惑度退化降低了69%。此外,该方法仅需2-4次回滚即可实现有效的自我纠正,证明了其鲁棒性和实用性。
🎯 应用场景
该研究成果可广泛应用于各种需要压缩LLM的场景,例如在资源受限的设备上部署LLM,或者降低LLM的推理成本。通过自适应剪枝,可以在保证模型性能的同时,显著减小模型大小,提高推理速度,从而加速LLM在边缘计算、移动设备等领域的应用。
📄 摘要(原文)
As Large Language Models (LLMs) continue to scale, post-training pruning has emerged as a promising approach to reduce computational costs while preserving performance. Existing methods such as SparseGPT and Wanda achieve high sparsity through layer-wise weight reconstruction or activation-aware magnitude pruning, but rely on uniform or hand-crafted heuristics to determine per-layer sparsity ratios. Moreover, recent work has shown that pruned LLMs suffer from severe factual knowledge degradation, with structured pruning methods experiencing near-total collapse in factual question-answering capabilities. We introduce agent-guided pruning, where a foundation model acts as an adaptive pruning agent to intelligently select which layers to prune at each iteration while preserving critical knowledge pathways. Our method constructs layer-wise sensitivity profiles by combining Wanda-inspired weight-activation metrics with gradient importance scores, normalized as z-scores for model-agnostic comparison. These statistics are processed by an LLM agent equipped with self-reflection capabilities, enabling it to learn from previous pruning outcomes and iteratively refine its strategy. A checkpoint rollback mechanism maintains model quality by reverting when perplexity degradation exceeds a threshold. We evaluate our approach on Qwen3 models (4B and 8B parameters) at approximately 45% sparsity, demonstrating substantial improvements over structured pruning baselines: 56% relative improvement in MMLU accuracy, 19x better factual knowledge retention on FreebaseQA, and 69% lower perplexity degradation. Notably, our framework requires no retraining, operates in a model-agnostic manner, and exhibits effective self-correction with only 2-4 rollbacks across 21-40 iterations, demonstrating that foundation models can effectively guide the compression of other foundation models.