Routing with Generated Data: Annotation-Free LLM Skill Estimation and Expert Selection
作者: Tianyi Niu, Justin Chih-Yao Chen, Genta Indra Winata, Shi-Xiong Zhang, Supriyo Chakraborty, Sambit Sahu, Yue Zhang, Elias Stengel-Eskin, Mohit Bansal
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-14
备注: Code: https://github.com/tianyiniu/RoutingGenData
💡 一句话要点
提出RGD设定与CASCAL路由,解决无标注数据下LLM专家模型动态选择问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM路由 生成数据 无监督学习 模型选择 专家模型 共识投票 层次聚类
📋 核心要点
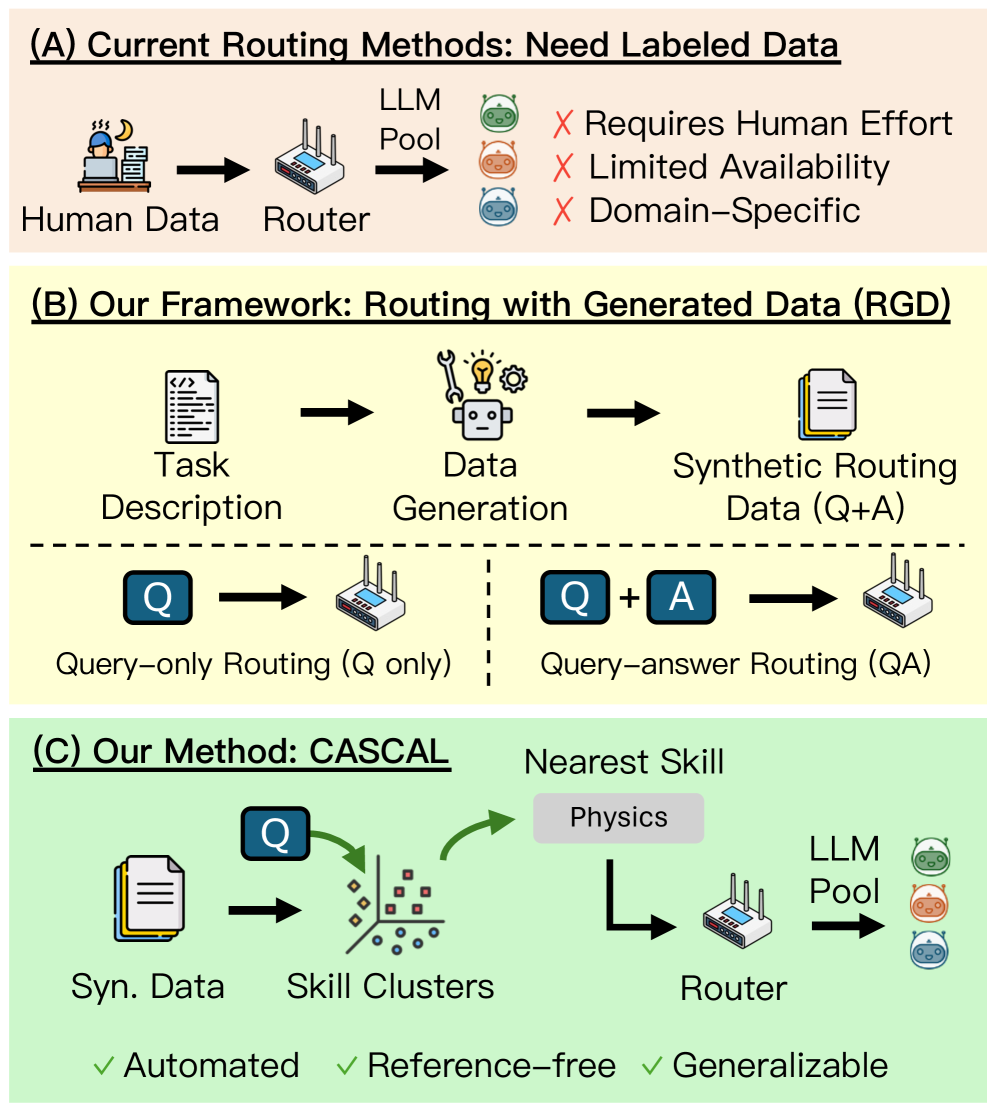
- 现有LLM路由方法依赖标注数据,但在实际场景中,用户请求分布未知,标注数据难以获取。
- 论文提出RGD设定,利用生成式LLM生成数据训练路由模型,并设计了仅查询路由模型CASCAL。
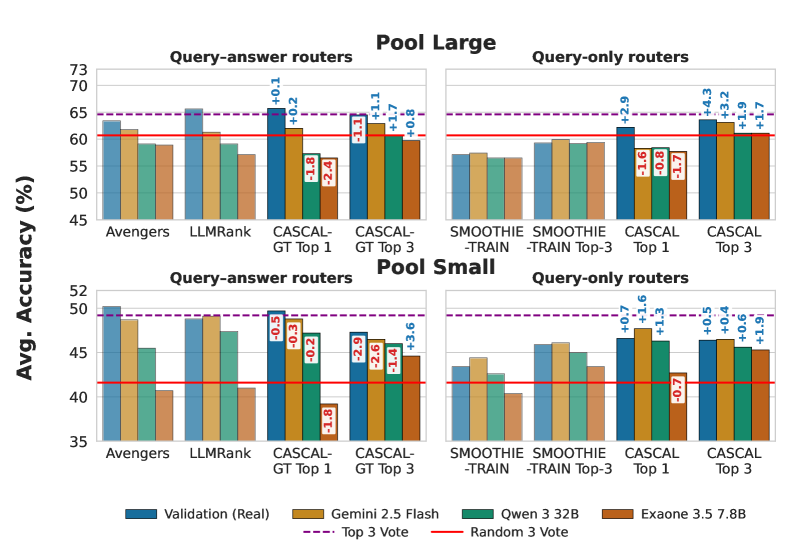
- 实验表明,CASCAL在弱生成器数据下训练时,性能优于其他路由模型,绝对精度提升4.6%。
📝 摘要(中文)
本文提出了Routing with Generated Data (RGD)这一新设定,旨在解决实际应用中用户请求分布异构且未知时,路由模型缺乏标注数据的问题。RGD设定下,路由模型仅使用生成式LLM产生的问题和答案进行训练。论文评估了查询-答案路由和仅查询路由在四个基准数据集和12个模型上的性能,发现查询-答案路由的性能随着生成器质量的下降而更快地退化。分析表明,有效的生成器需要准确回答自身提出的问题,并且其问题能够充分区分模型池的性能。论文进一步展示了如何通过过滤来提高生成数据的质量,并提出了一种新颖的仅查询路由模型CASCAL,该模型通过共识投票估计模型的正确性,并通过层次聚类识别模型特定的技能领域。CASCAL对生成器质量具有更强的鲁棒性,在使用弱生成器数据训练时,其绝对精度比最佳查询-答案路由高出4.6%。
🔬 方法详解
问题定义:论文旨在解决在缺乏真实标注数据的情况下,如何有效地训练LLM路由模型,从而动态地为给定的输入选择最佳模型的问题。现有方法依赖于人工标注数据,成本高昂且难以适应不断变化的用户请求分布。特别是在用户请求分布异构且未知的情况下,获取具有代表性的标注数据变得更加困难。
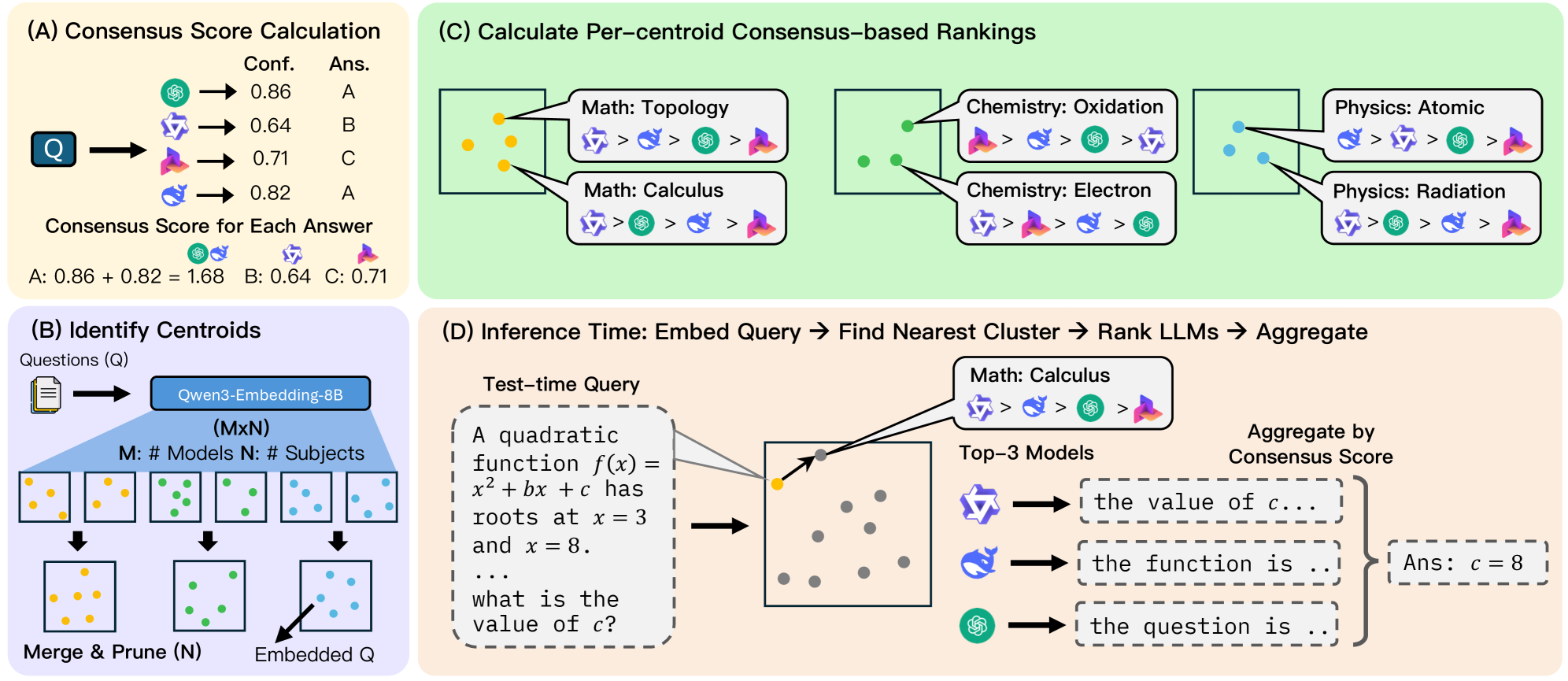
核心思路:论文的核心思路是利用生成式LLM来生成训练数据,从而避免对人工标注数据的依赖。通过分析生成数据的质量对路由模型性能的影响,论文提出了提高生成数据质量的方法,并设计了一种对生成数据质量具有鲁棒性的路由模型CASCAL。CASCAL的核心思想是通过共识投票估计模型的正确性,并通过层次聚类识别模型特定的技能领域。
技术框架:RGD的整体框架包含两个主要部分:数据生成和路由模型训练。首先,使用生成式LLM根据高层任务描述生成问题和答案。然后,使用生成的数据训练路由模型。CASCAL路由模型包含两个主要模块:共识投票模块和层次聚类模块。共识投票模块用于估计模型对给定输入的正确性,层次聚类模块用于识别模型特定的技能领域。
关键创新:论文的关键创新在于提出了RGD这一新的研究设定,并设计了CASCAL路由模型。RGD设定为研究在缺乏标注数据的情况下训练路由模型提供了新的视角。CASCAL模型通过共识投票和层次聚类,有效地利用了生成数据中的信息,提高了路由模型的鲁棒性和准确性。与现有方法相比,CASCAL不需要人工标注数据,并且对生成数据质量具有更强的适应性。
关键设计:CASCAL的关键设计包括:1) 使用多个模型的预测结果进行共识投票,以提高正确性估计的准确性;2) 使用层次聚类来识别模型特定的技能领域,从而更好地利用模型的优势;3) 设计了一种损失函数,鼓励模型学习区分不同技能领域的输入。具体的参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CASCAL在弱生成器数据下训练时,性能优于其他路由模型,绝对精度提升4.6%。此外,论文还分析了生成器质量对路由模型性能的影响,并提出了提高生成数据质量的方法。这些发现为在缺乏标注数据的情况下训练LLM路由模型提供了重要的指导。
🎯 应用场景
该研究成果可应用于各种需要动态选择LLM的场景,例如智能客服、内容生成、代码生成等。通过RGD设定和CASCAL路由,可以降低对人工标注数据的依赖,提高LLM路由的效率和准确性,从而提升用户体验和降低运营成本。未来,该方法可以进一步扩展到多模态数据和更复杂的任务。
📄 摘要(原文)
Large Language Model (LLM) routers dynamically select optimal models for given inputs. Existing approaches typically assume access to ground-truth labeled data, which is often unavailable in practice, especially when user request distributions are heterogeneous and unknown. We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs. We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models, finding that query-answer routers degrade faster than query-only routers as generator quality decreases. Our analysis reveals two crucial characteristics of effective generators: they must accurately respond to their own questions, and their questions must produce sufficient performance differentiation among the model pool. We then show how filtering for these characteristics can improve the quality of generated data. We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering. CASCAL is substantially more robust to generator quality, outperforming the best query-answer router by 4.6% absolute accuracy when trained on weak generator data.