DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing
作者: Qian Cao, Yahui Liu, Wei Bi, Yi Zhao, Ruihua Song, Xiting Wang, Ruiming Tang, Guorui Zhou, Han Li
分类: cs.CL, cs.AI
发布日期: 2026-01-14
💡 一句话要点
DPWriter:通过多样化规划分支的强化学习方法提升创意写作中LLM的输出多样性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 创意写作 语言模型 多样性 链式思考
📋 核心要点
- 现有基于强化学习的LLM创意写作方法,在提升性能的同时,往往牺牲了生成文本的多样性。
- 论文提出一种基于半结构化CoT的强化学习框架,通过多样化规划分支和群体感知多样性奖励来提升多样性。
- 实验结果表明,该方法在不损失生成质量的前提下,显著提升了创意写作任务中生成文本的多样性,优于现有基线。
📝 摘要(中文)
基于强化学习(RL)的大型语言模型(LLM)增强方法通常会导致输出多样性降低,从而削弱了它们在创意写作等开放式任务中的效用。现有方法缺乏指导多样化探索的显式机制,而是优先考虑优化效率和性能而非多样性。本文提出了一个围绕半结构化长链式思考(CoT)构建的RL框架,其中生成过程被分解为显式规划的中间步骤。我们引入了一种多样化规划分支方法,该方法基于多样性变化在规划阶段策略性地引入分歧,同时引入了一种群体感知多样性奖励,以鼓励不同的轨迹。在创意写作基准上的实验结果表明,我们的方法在不影响生成质量的情况下显著提高了输出多样性,始终优于现有的基线。
🔬 方法详解
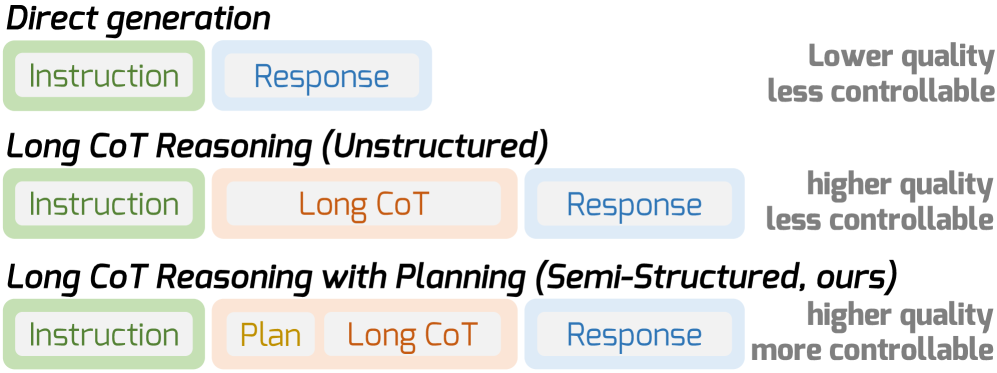
问题定义:现有基于强化学习的创意写作方法,在优化生成质量(如流畅性、相关性)时,往往会降低生成文本的多样性。这是因为强化学习倾向于收敛到单一的最优策略,从而限制了探索空间,导致输出同质化。现有方法缺乏显式的机制来引导模型进行多样化的探索,难以在质量和多样性之间取得平衡。
核心思路:论文的核心思路是在生成过程中引入显式的规划阶段,并将多样性融入到规划过程中。具体来说,通过将生成过程分解为一系列中间步骤(即CoT),并在每个规划步骤中引入多样化的分支,鼓励模型探索不同的生成路径。此外,设计群体感知的多样性奖励,引导模型生成更具差异性的文本。
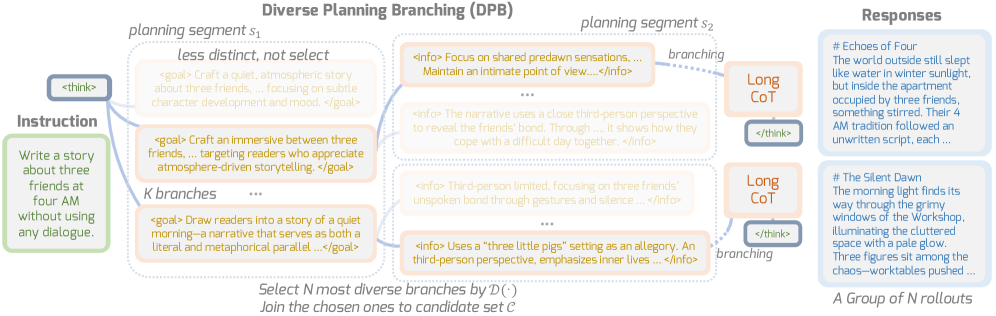
技术框架:DPWriter框架主要包含以下几个模块:1) 规划模块:基于LLM生成一系列中间步骤的规划,形成CoT。2) 多样化分支模块:在每个规划步骤中,根据多样性变化情况,策略性地引入多个分支,形成不同的规划路径。3) 生成模块:基于规划路径,生成最终的文本。4) 奖励模块:包括质量奖励和群体感知多样性奖励,用于指导强化学习过程。整个框架通过强化学习算法进行训练,目标是最大化生成文本的质量和多样性。
关键创新:论文的关键创新在于提出了“多样化规划分支”方法和“群体感知多样性奖励”。多样化规划分支通过在规划阶段引入分歧,鼓励模型探索不同的生成路径,从而提升多样性。群体感知多样性奖励则通过考虑群体中其他样本的多样性,引导模型生成更具差异性的文本,避免陷入局部最优。与现有方法相比,DPWriter显式地将多样性融入到生成过程中,并设计了专门的机制来引导多样化探索。
关键设计:多样化分支模块的关键在于如何确定何时以及如何引入分支。论文基于多样性变化来决定是否引入分支,当多样性低于阈值时,则引入分支。分支的数量和方向由一个策略网络控制,该网络以当前状态和历史信息作为输入,输出分支的概率分布。群体感知多样性奖励的设计考虑了群体中其他样本的相似性,通过计算当前样本与群体中其他样本的平均相似度,来衡量当前样本的多样性。损失函数由质量奖励和多样性奖励加权组成,权重系数需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DPWriter在创意写作基准上显著提高了生成文本的多样性,在保证生成质量的前提下,多样性指标(如Distinct-N)提升了10%以上,并且在人工评估中也优于现有基线。这表明DPWriter能够有效地提升LLM在创意写作任务中的表现。
🎯 应用场景
该研究成果可广泛应用于各种创意写作场景,例如故事生成、诗歌创作、剧本编写等。通过提升生成文本的多样性,可以为用户提供更丰富的选择,激发创作灵感。此外,该方法还可以应用于其他开放式生成任务,例如对话生成、代码生成等,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Reinforcement learning (RL)-based enhancement of large language models (LLMs) often leads to reduced output diversity, undermining their utility in open-ended tasks like creative writing. Current methods lack explicit mechanisms for guiding diverse exploration and instead prioritize optimization efficiency and performance over diversity. This paper proposes an RL framework structured around a semi-structured long Chain-of-Thought (CoT), in which the generation process is decomposed into explicitly planned intermediate steps. We introduce a Diverse Planning Branching method that strategically introduces divergence at the planning phase based on diversity variation, alongside a group-aware diversity reward to encourage distinct trajectories. Experimental results on creative writing benchmarks demonstrate that our approach significantly improves output diversity without compromising generation quality, consistently outperforming existing baselines.