Benchmarking Post-Training Quantization of Large Language Models under Microscaling Floating Point Formats
作者: Manyi Zhang, Ji-Fu Li, Zhongao Sun, Haoli Bai, Hui-Ling Zhen, Zhenhua Dong, Xianzhi Yu
分类: cs.CL, cs.AI
发布日期: 2026-01-14
💡 一句话要点
系统评估微缩浮点格式下大语言模型后训练量化方法,并提供实用指导。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 微缩浮点 大语言模型 低精度量化 模型压缩
📋 核心要点
- 现有PTQ算法主要针对整数量化,在微缩浮点格式下的表现和适用性研究不足。
- 系统性地研究了多种PTQ算法在MXFP格式下的性能,并分析了影响量化效果的关键因素。
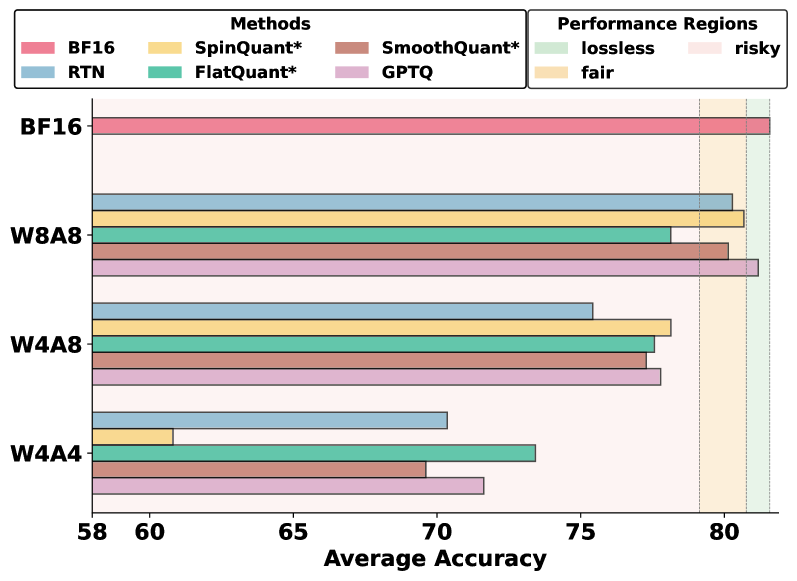
- 实验表明MXFP8能实现接近无损的性能,而MXFP4面临挑战,预缩放优化能有效提升MXFP4的性能。
📝 摘要(中文)
微缩浮点(MXFP)格式作为一种有前景的大语言模型(LLM)低精度格式正在兴起。尽管已经提出了各种后训练量化(PTQ)算法,但它们主要集中在整数量化上,而它们在MXFP格式下的适用性和行为在很大程度上仍未被探索。为了弥补这一差距,本文对MXFP格式下的PTQ进行了系统研究,涵盖了7种以上的PTQ算法、15个评估基准和3个LLM家族。主要发现包括:1)MXFP8始终实现接近无损的性能,而MXFP4引入了显著的精度下降,并且仍然具有挑战性;2)MXFP下的PTQ有效性在很大程度上取决于格式兼容性,某些算法范式始终比其他算法更有效;3)PTQ性能在模型家族和模态中表现出高度一致的趋势,特别是,量化敏感性主要由语言模型决定,而不是多模态LLM中的视觉编码器;4)量化的缩放因子是MXFP4中的一个关键误差源,一个简单的预缩放优化策略可以显著减轻其影响。总之,这些结果为将现有PTQ方法应用于MXFP量化提供了实用的指导。
🔬 方法详解
问题定义:论文旨在解决大语言模型在微缩浮点(MXFP)格式下进行后训练量化(PTQ)时,现有PTQ算法适用性不足的问题。现有PTQ算法主要针对整数量化设计,直接应用于MXFP格式时,性能表现未知,且可能存在精度损失。此外,不同MXFP格式(如MXFP4和MXFP8)的特性对PTQ算法的影响也缺乏深入研究。
核心思路:论文的核心思路是通过系统性的实验评估,分析不同PTQ算法在不同MXFP格式下的性能表现,并找出影响量化效果的关键因素。通过对比不同算法范式,识别出更适合MXFP格式的PTQ方法。同时,针对MXFP格式的特性,提出优化策略,以提升量化精度。
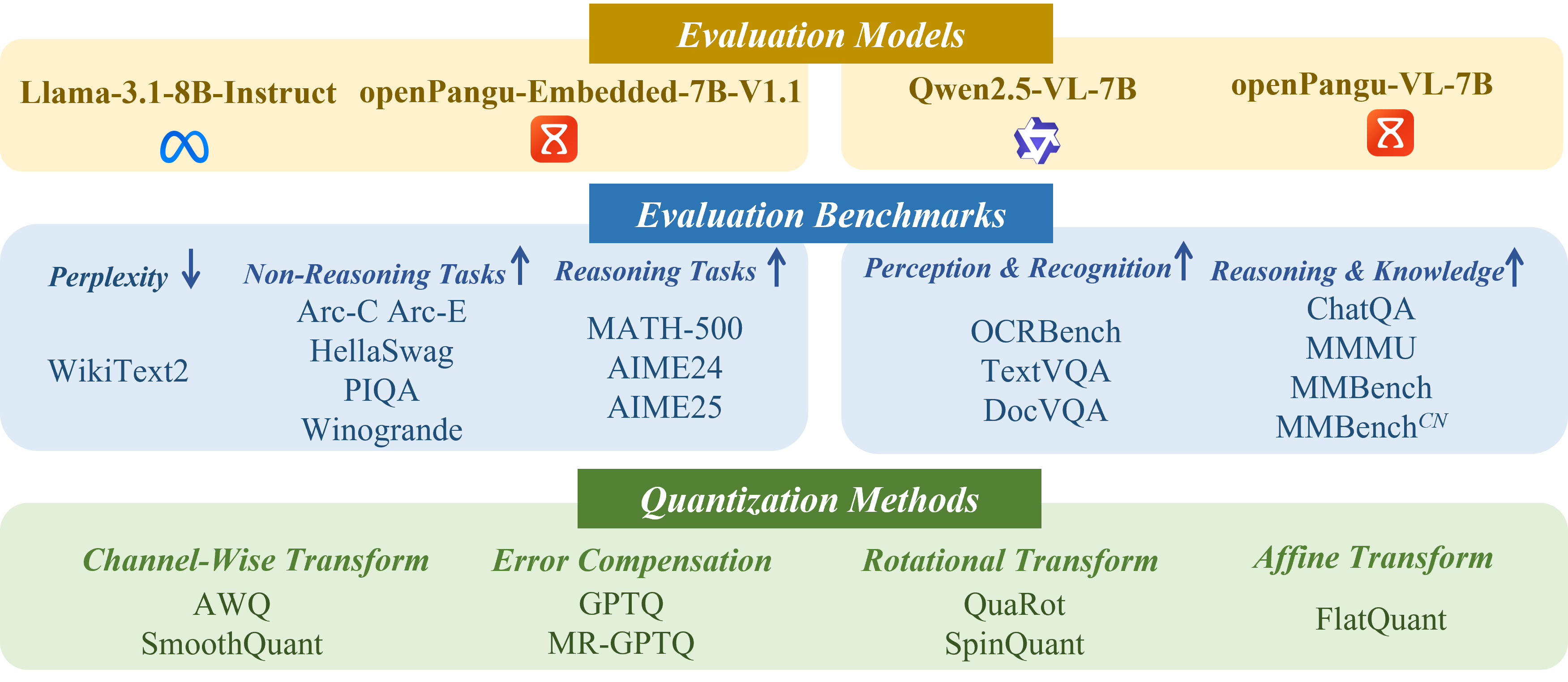
技术框架:论文的整体框架包括以下几个主要步骤:1)选择具有代表性的PTQ算法,包括但不限于Minimax、GPTQ等;2)选择不同的大语言模型家族,如LLaMA、OPT等;3)选择不同的MXFP格式,如MXFP4和MXFP8;4)在多个评估基准上进行实验,评估不同PTQ算法在不同MXFP格式下的性能表现;5)分析实验结果,找出影响量化效果的关键因素,如缩放因子;6)针对关键因素,提出优化策略,并验证其有效性。
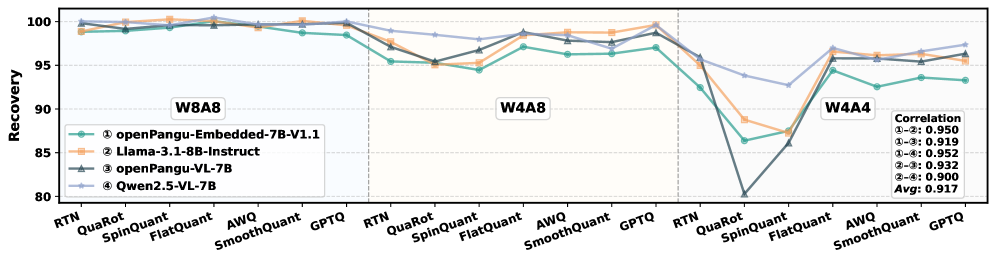
关键创新:论文的关键创新在于:1)首次对多种PTQ算法在MXFP格式下的性能进行了系统性的评估;2)揭示了MXFP格式下PTQ的有效性与格式兼容性密切相关;3)发现量化的缩放因子是MXFP4中的一个关键误差源,并提出了预缩放优化策略来缓解其影响。
关键设计:论文的关键设计包括:1)选择了具有代表性的PTQ算法和LLM家族,以保证实验结果的泛化性;2)使用了多个评估基准,以全面评估量化模型的性能;3)针对MXFP4的缩放因子问题,提出了简单的预缩放优化策略,即在量化前对权重进行预处理,以减小缩放因子的影响。具体的预处理方法未知,论文中可能未详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MXFP8格式下,PTQ算法能够实现接近无损的性能。而MXFP4格式下,精度损失较为明显。通过预缩放优化策略,可以显著提升MXFP4格式下的量化精度。研究还发现,量化敏感性主要由语言模型决定,而非视觉编码器,这为多模态大语言模型的量化提供了重要参考。
🎯 应用场景
该研究成果可应用于大语言模型的低精度部署,尤其是在资源受限的边缘设备上。通过选择合适的PTQ算法和MXFP格式,可以在保证模型性能的前提下,显著降低模型的大小和计算复杂度,从而实现更高效的模型推理。该研究也为未来开发更适合MXFP格式的PTQ算法提供了指导。
📄 摘要(原文)
Microscaling Floating-Point (MXFP) has emerged as a promising low-precision format for large language models (LLMs). Despite various post-training quantization (PTQ) algorithms being proposed, they mostly focus on integer quantization, while their applicability and behavior under MXFP formats remain largely unexplored. To address this gap, this work conducts a systematic investigation of PTQ under MXFP formats, encompassing over 7 PTQ algorithms, 15 evaluation benchmarks, and 3 LLM families. The key findings include: 1) MXFP8 consistently achieves near-lossless performance, while MXFP4 introduces substantial accuracy degradation and remains challenging; 2) PTQ effectiveness under MXFP depends strongly on format compatibility, with some algorithmic paradigms being consistently more effective than others; 3) PTQ performance exhibits highly consistent trends across model families and modalities, in particular, quantization sensitivity is dominated by the language model rather than the vision encoder in multimodal LLMs; 4) The scaling factor of quantization is a critical error source in MXFP4, and a simple pre-scale optimization strategy can significantly mitigate its impact. Together, these results provide practical guidance on adapting existing PTQ methods to MXFP quantization.