Dissecting Judicial Reasoning in U.S. Copyright Damage Awards
作者: Pei-Chi Lo, Thomas Y. Lu
分类: cs.IR, cs.CL
发布日期: 2026-01-14
备注: Presented in SIGKDD'25 SciSoc LLM Workshop: Large Language Models for Scientific and Societal Advances
💡 一句话要点
提出一种基于篇章结构的LLM方法,用于解析美国版权损害赔偿判决中的司法推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算法律分析 大型语言模型 修辞结构理论 版权法 司法推理
📋 核心要点
- 现有方法难以有效解析美国版权法判决中复杂的司法推理过程,导致法律实践中存在不确定性。
- 该研究提出一种基于篇章结构的LLM方法,结合修辞结构理论,从判决文本中提取并量化司法推理模式。
- 实验表明,该方法优于传统方法,能够揭示不同法院在判决因素权重上的差异,为法律实践提供更深入的见解。
📝 摘要(中文)
美国版权损害赔偿判决中的司法推理对计算法律分析提出了核心挑战。尽管联邦法院遵循1976年《版权法》,但其解释和因素权重在不同司法管辖区差异很大。这种不一致性给诉讼当事人带来了不确定性,并模糊了法律决策的经验基础。本研究引入了一种新颖的基于篇章的大型语言模型(LLM)方法,该方法将修辞结构理论(RST)与代理工作流相结合,以提取和量化先前不透明的司法意见中的推理模式。我们的框架通过将意见解析为分层篇章结构,并使用三阶段流程(即数据集构建、篇章分析和代理特征提取)来解决经验法律学术研究中的一个主要差距。在分析版权损害裁决时,我们表明,篇章增强的LLM分析优于传统方法,同时揭示了不同巡回法院在因素权重方面未量化的差异。这些发现为计算法律分析提供了方法论上的进步,并为司法推理提供了实践见解,对寻求预测工具的法律从业者、研究法律原则应用的学者以及面临版权法不一致的政策制定者具有重要意义。
🔬 方法详解
问题定义:本研究旨在解决美国版权法损害赔偿判决中司法推理过程难以理解和量化的问题。现有方法,如简单的关键词提取或统计分析,无法捕捉判决文本中复杂的论证结构和推理模式,导致法律从业者难以预测判决结果,学者难以研究法律原则的应用,政策制定者也难以发现法律实践中的不一致性。
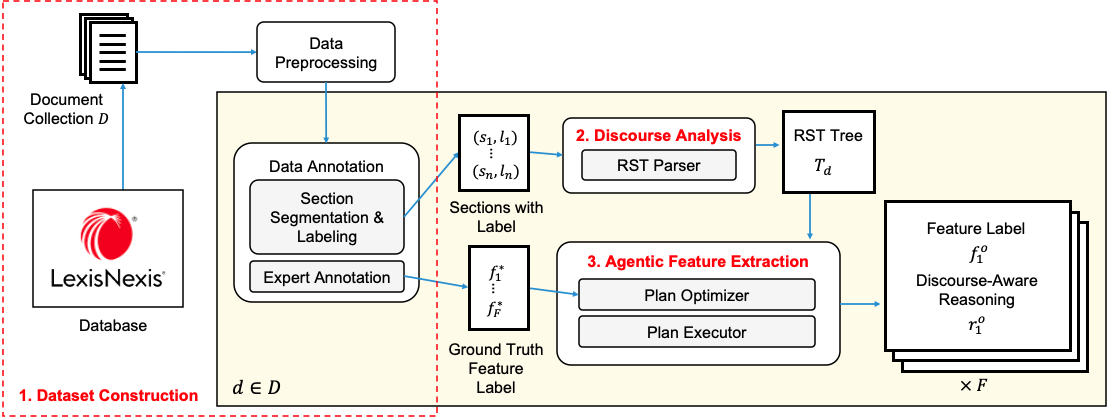
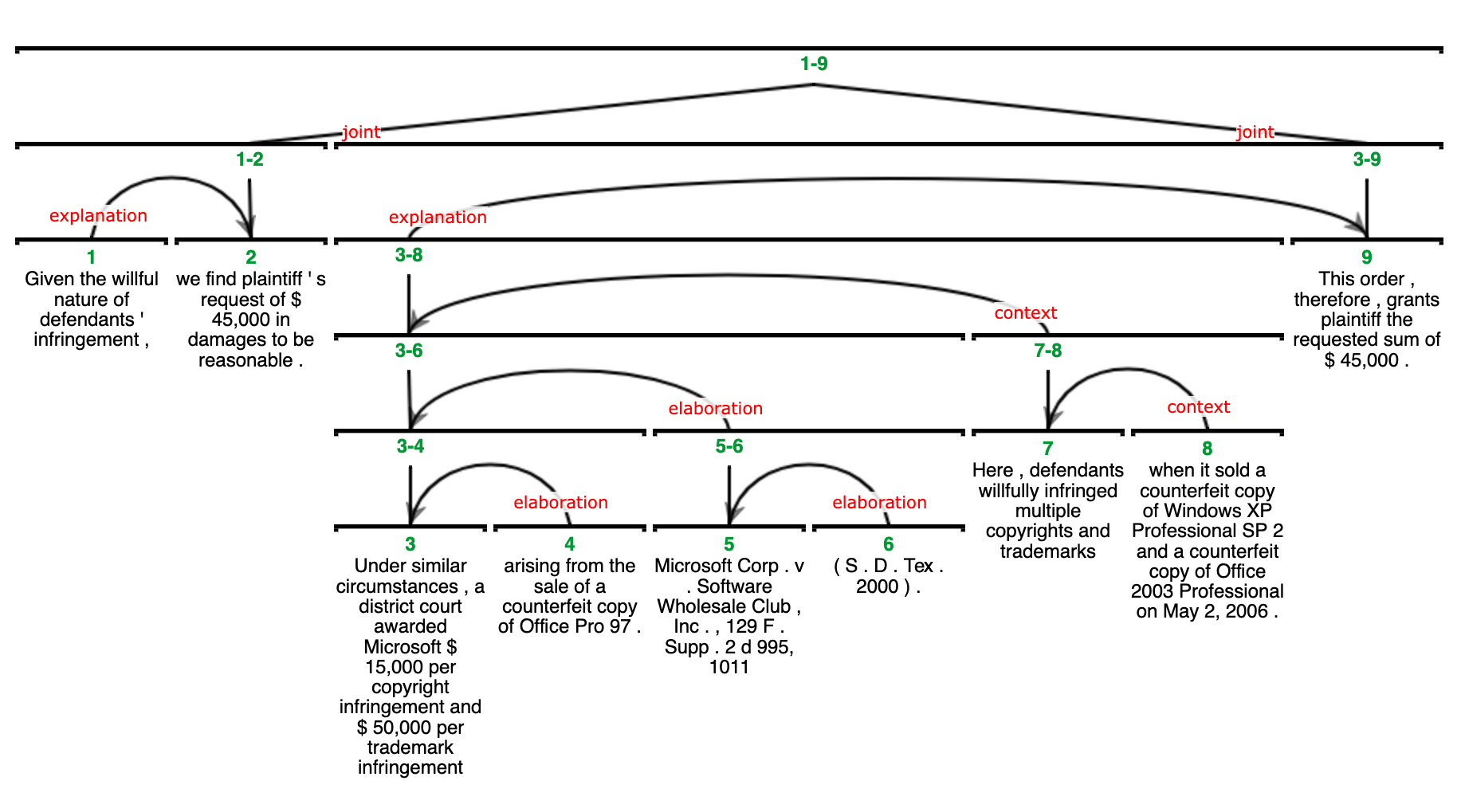
核心思路:论文的核心思路是将判决文本视为一种篇章,利用修辞结构理论(RST)分析文本的层次结构,并结合大型语言模型(LLM)提取与司法推理相关的特征。通过将文本分解为更小的、具有语义关系的单元,并利用LLM的强大语义理解能力,可以更准确地识别和量化判决中的推理模式。
技术框架:该方法包含三个主要阶段:1) 数据集构建:收集美国版权法损害赔偿判决文本,并进行预处理。2) 篇章分析:利用RST将判决文本解析为分层的篇章结构,识别文本中的核心论点和支撑论据。3) 代理特征提取:设计一个代理工作流,利用LLM从篇章结构中提取与司法推理相关的特征,例如判决因素的权重、论证方式等。
关键创新:该方法最重要的创新点在于将篇章结构分析与LLM相结合,从而能够更深入地理解判决文本中的司法推理过程。与传统方法相比,该方法能够捕捉到判决文本中更细粒度的语义信息和论证结构,从而更准确地量化司法推理模式。
关键设计:RST分析的具体实现方式(例如,使用的RST解析器)、LLM模型的选择(例如,使用的预训练模型和微调策略)、代理工作流的设计(例如,如何利用LLM提取特征、如何处理长文本)以及特征工程的具体方法(例如,如何量化判决因素的权重)等技术细节在论文中进行了详细描述,但具体参数设置和网络结构等信息未知。
🖼️ 关键图片
📊 实验亮点
研究表明,基于篇章结构的LLM方法在分析版权损害赔偿判决方面优于传统方法。具体性能数据未知,但该方法能够揭示不同巡回法院在判决因素权重方面存在的未量化的差异,为法律从业者和学者提供了更深入的见解。该方法在特征提取和司法推理模式识别方面表现出显著优势。
🎯 应用场景
该研究成果可应用于多个领域。法律从业者可以使用该方法构建预测工具,预测版权损害赔偿判决结果。学者可以利用该方法研究法律原则在实践中的应用,揭示法律实践中的不一致性。政策制定者可以利用该方法评估版权法的实施效果,并制定更合理的法律政策。此外,该方法还可以推广到其他法律领域,例如合同法、侵权法等。
📄 摘要(原文)
Judicial reasoning in copyright damage awards poses a core challenge for computational legal analysis. Although federal courts follow the 1976 Copyright Act, their interpretations and factor weightings vary widely across jurisdictions. This inconsistency creates unpredictability for litigants and obscures the empirical basis of legal decisions. This research introduces a novel discourse-based Large Language Model (LLM) methodology that integrates Rhetorical Structure Theory (RST) with an agentic workflow to extract and quantify previously opaque reasoning patterns from judicial opinions. Our framework addresses a major gap in empirical legal scholarship by parsing opinions into hierarchical discourse structures and using a three-stage pipeline, i.e., Dataset Construction, Discourse Analysis, and Agentic Feature Extraction. This pipeline identifies reasoning components and extract feature labels with corresponding discourse subtrees. In analyzing copyright damage rulings, we show that discourse-augmented LLM analysis outperforms traditional methods while uncovering unquantified variations in factor weighting across circuits. These findings offer both methodological advances in computational legal analysis and practical insights into judicial reasoning, with implications for legal practitioners seeking predictive tools, scholars studying legal principle application, and policymakers confronting inconsistencies in copyright law.