Improving Symbolic Translation of Language Models for Logical Reasoning
作者: Ramya Keerthy Thatikonda, Jiuzhou Han, Wray Buntine, Ehsan Shareghi
分类: cs.CL, cs.AI
发布日期: 2026-01-14
备注: The Third workshop of NeusymBridge @AAAI 2026 (Bridging Neurons and Symbols for NLP and Knowledge Graph Reasoning)
💡 一句话要点
针对逻辑推理,提出改进语言模型符号翻译的方法,提升小模型的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 符号推理 语言模型 一阶逻辑 自然语言处理 增量推理
📋 核心要点
- 现有方法依赖模型自我迭代纠错,但小模型能力不足,难以有效纠正自然语言到一阶逻辑的翻译错误。
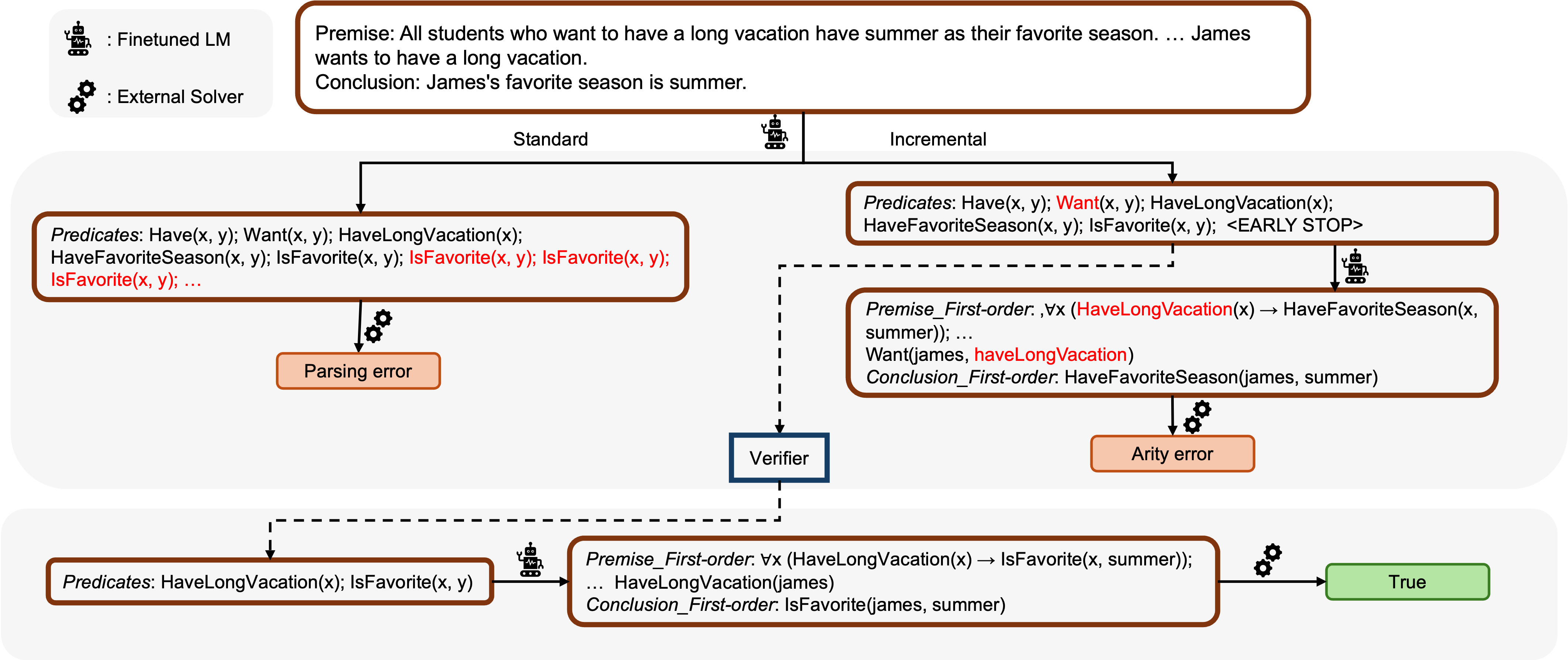
- 提出增量推理,将翻译过程分解为谓词生成和FOL翻译两阶段,并引入验证模块纠正谓词错误。
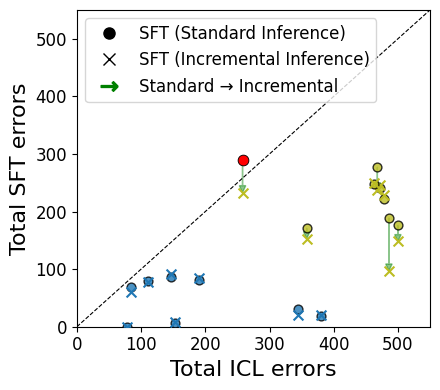
- 通过微调、增量推理和验证模块,显著降低了错误率,增加了谓词覆盖率,提升了小模型的推理性能。
📝 摘要(中文)
本文旨在提升语言模型(LM)在演绎逻辑推理中符号翻译的性能。将自然语言(NL)翻译成一阶逻辑(FOL),并利用外部求解器,可以构建可验证且可靠的推理系统。然而,较小的LM通常难以胜任此翻译任务,由于格式和翻译错误,经常产生不正确的符号输出。现有方法通常依赖于自我迭代来纠正这些错误,但此类方法严重依赖于底层模型的能力。为了解决这个问题,我们首先对常见错误进行分类,并使用大型语言模型合成的数据对较小的LM进行微调。评估是使用定义的错误类别进行的。我们引入了增量推理,将推理分为两个阶段:谓词生成和FOL翻译,从而更好地控制模型行为并提高生成质量(通过谓词指标衡量)。这种分解框架还支持使用针对谓词-arity错误的验证模块,以进一步提高性能。我们的研究评估了跨四个逻辑推理数据集的三个模型系列。全面的微调、增量推理和验证模块降低了错误率,增加了谓词覆盖率,并提高了较小LM的推理性能,使我们更接近于开发可靠且易于访问的符号推理系统。
🔬 方法详解
问题定义:论文旨在解决小规模语言模型在将自然语言翻译为一阶逻辑(FOL)进行逻辑推理时,由于格式和翻译错误导致推理性能不佳的问题。现有方法,如自我迭代纠错,依赖于模型自身的能力,对于小模型效果有限。因此,如何提升小模型在此任务上的准确性和可靠性是核心问题。
核心思路:论文的核心思路是将复杂的翻译任务分解为更易于管理的子任务,并针对性地进行优化。通过将翻译过程分解为谓词生成和FOL翻译两个阶段,可以更好地控制模型行为,并引入验证模块来纠正特定类型的错误。这种分解和验证的策略旨在提高翻译的准确性和鲁棒性。
技术框架:整体框架包含三个主要组成部分:1) 使用大型语言模型合成数据对小模型进行微调;2) 增量推理,将翻译任务分解为谓词生成和FOL翻译两个阶段;3) 验证模块,用于检测和纠正谓词-arity错误。首先,使用合成数据提升模型的初始翻译能力。然后,增量推理允许更精细的控制和优化。最后,验证模块进一步提高翻译的准确性。
关键创新:论文的关键创新在于增量推理和验证模块的结合使用。增量推理通过分解任务降低了复杂性,使得模型更容易学习和优化。验证模块则针对特定类型的错误进行纠正,进一步提高了翻译的准确性。这种分解和验证的策略与现有方法中依赖模型自身纠错的方式有本质区别。
关键设计:论文中,数据合成使用了大型语言模型生成高质量的训练数据,用于微调小模型。增量推理的具体实现方式(例如,如何定义谓词生成和FOL翻译的接口)以及验证模块的实现细节(例如,如何检测和纠正谓词-arity错误)在论文中应该有更详细的描述,但摘要中未明确提及。损失函数和网络结构的选择也未在摘要中提及,这些都属于需要进一步研究的细节。
🖼️ 关键图片

📊 实验亮点
论文通过综合微调、增量推理和验证模块,有效降低了错误率,增加了谓词覆盖率,并提高了小模型的推理性能。虽然摘要中没有给出具体的性能数据和对比基线,但强调了这些方法的有效性,表明该研究在提升小规模语言模型的逻辑推理能力方面取得了显著进展。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱构建、自动定理证明等领域。通过提升小规模语言模型的逻辑推理能力,可以降低部署成本,扩展应用范围,并为开发更可靠、更易于访问的符号推理系统奠定基础。未来可应用于教育、法律等需要严谨逻辑推理的场景。
📄 摘要(原文)
The use of formal language for deductive logical reasoning aligns well with language models (LMs), where translating natural language (NL) into first-order logic (FOL) and employing an external solver results in a verifiable and therefore reliable reasoning system. However, smaller LMs often struggle with this translation task, frequently producing incorrect symbolic outputs due to formatting and translation errors. Existing approaches typically rely on self-iteration to correct these errors, but such methods depend heavily on the capabilities of the underlying model. To address this, we first categorize common errors and fine-tune smaller LMs using data synthesized by large language models. The evaluation is performed using the defined error categories. We introduce incremental inference, which divides inference into two stages, predicate generation and FOL translation, providing greater control over model behavior and enhancing generation quality as measured by predicate metrics. This decomposition framework also enables the use of a verification module that targets predicate-arity errors to further improve performance. Our study evaluates three families of models across four logical-reasoning datasets. The comprehensive fine-tuning, incremental inference, and verification modules reduce error rates, increase predicate coverage, and improve reasoning performance for smaller LMs, moving us closer to developing reliable and accessible symbolic-reasoning systems.