Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
作者: Xinze Li, Zhenghao Liu, Haidong Xin, Yukun Yan, Shuo Wang, Zheni Zeng, Sen Mei, Ge Yu, Maosong Sun
分类: cs.CL
发布日期: 2026-01-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出PAGER框架,通过上下文页面结构化知识表示增强检索增强生成效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 知识表示 大型语言模型 结构化知识 上下文学习
📋 核心要点
- 现有迭代式RAG方法缺乏连贯的组织结构,限制了知识表示的全面性和凝聚力。
- PAGER框架通过页面驱动的方式,首先构建结构化认知大纲,然后迭代检索和提炼相关文档填充槽位。
- 实验结果表明,PAGER在多个知识密集型基准上优于现有RAG基线,提升了知识表示的质量和信息密度。
📝 摘要(中文)
检索增强生成(RAG)通过整合外部知识来提升大型语言模型(LLM)的能力。最近,一些工作将迭代知识积累过程融入RAG模型,以逐步积累和提炼与查询相关的知识,从而构建更全面的知识表示。然而,这些迭代过程通常缺乏连贯的组织结构,限制了更全面和有凝聚力的知识表示的构建。为了解决这个问题,我们提出了PAGER,一个用于RAG的页面驱动的自主知识表示框架。PAGER首先提示LLM为一个给定的问题构建一个结构化的认知大纲,该大纲由多个代表不同知识方面的槽位组成。然后,PAGER迭代地检索和提炼相关文档来填充每个槽位,最终构建一个连贯的页面,作为指导答案生成的上下文输入。在多个知识密集型基准和骨干模型上的实验表明,PAGER始终优于所有RAG基线。进一步的分析表明,PAGER构建了更高质量和信息密集的知识表示,更好地缓解了知识冲突,并使LLM能够更有效地利用外部知识。所有代码可在https://github.com/OpenBMB/PAGER获取。
🔬 方法详解
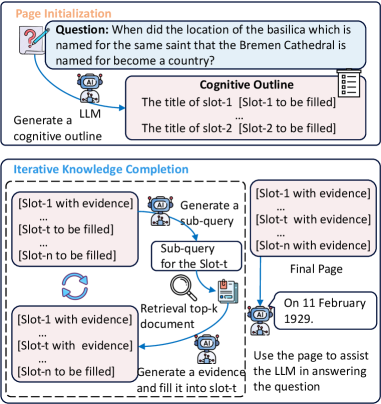
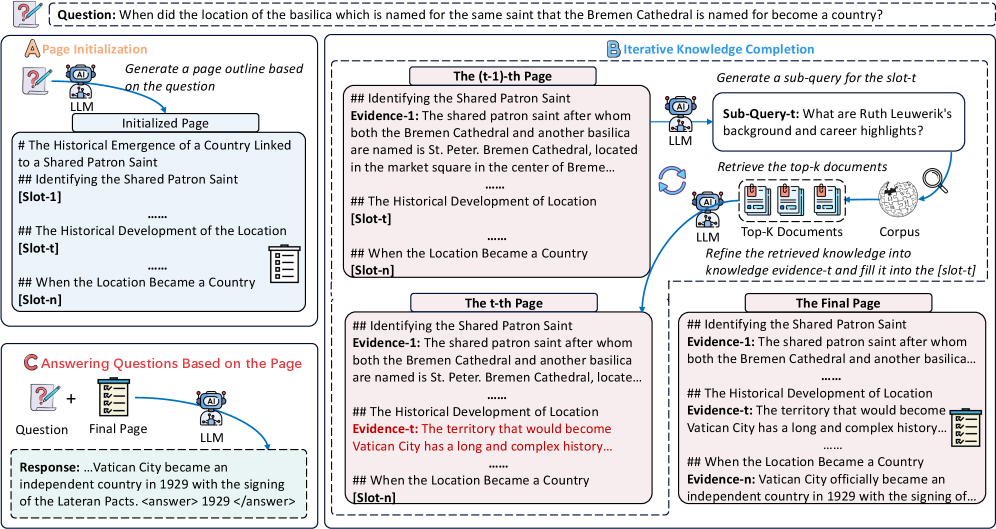
问题定义:现有迭代式检索增强生成(RAG)方法在知识积累过程中缺乏明确的结构化组织,导致构建的知识表示不够全面和连贯。这些方法难以有效管理和利用检索到的信息,尤其是在处理复杂问题时,容易出现信息冗余、冲突或遗漏等问题。
核心思路:PAGER的核心思路是引入“页面”的概念,将知识表示组织成结构化的上下文页面。每个页面包含多个槽位,每个槽位代表一个特定的知识方面。通过预先定义的认知大纲,引导LLM进行有针对性的知识检索和提炼,从而构建更全面、更连贯的知识表示。这种结构化的方法有助于更好地管理和利用外部知识,提高RAG模型的性能。
技术框架:PAGER框架主要包含以下几个阶段:1. 认知大纲构建:给定问题,利用LLM生成结构化的认知大纲,定义页面的槽位。2. 迭代检索与提炼:针对每个槽位,迭代地检索相关文档,并利用LLM进行提炼,将关键信息填充到槽位中。3. 页面构建:将填充好的槽位组合成完整的上下文页面,作为LLM生成答案的输入。4. 答案生成:利用LLM,基于构建的上下文页面生成最终答案。
关键创新:PAGER的关键创新在于引入了页面驱动的结构化知识表示方法。与传统的RAG方法相比,PAGER通过预定义的认知大纲和迭代的检索提炼过程,构建了更全面、更连贯的知识表示。这种结构化的方法有助于更好地管理和利用外部知识,提高RAG模型的性能。此外,PAGER还能够更好地缓解知识冲突,并使LLM能够更有效地利用外部知识。
关键设计:在认知大纲构建阶段,可以使用不同的LLM提示策略来生成高质量的认知大纲。在迭代检索与提炼阶段,可以采用不同的检索模型和提炼策略,例如使用BM25进行初始检索,然后使用LLM进行文档排序和信息抽取。在页面构建阶段,可以根据不同的任务需求,调整槽位的数量和内容。此外,还可以引入一些正则化项,例如鼓励槽位之间的信息互补性,以提高知识表示的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PAGER在多个知识密集型基准测试中始终优于所有RAG基线。例如,在某些数据集上,PAGER的性能提升超过10%。进一步的分析表明,PAGER能够构建更高质量和信息密集的知识表示,更好地缓解知识冲突,并使LLM能够更有效地利用外部知识。
🎯 应用场景
PAGER框架可应用于各种需要利用外部知识的自然语言处理任务,例如问答系统、知识图谱构建、文本摘要、报告生成等。该框架能够有效提升LLM在知识密集型任务中的性能,并可用于构建更智能、更可靠的AI系统。未来,PAGER有望在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.