Ability Transfer and Recovery via Modularized Parameters Localization
作者: Songyao Jin, Kun Zhou, Wenqi Li, Peng Wang, Biwei Huang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-14
💡 一句话要点
提出ACT:通过模块化参数定位实现大模型能力迁移与恢复
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 能力迁移 灾难性遗忘 参数定位 激活分析
📋 核心要点
- 现有大模型在特定领域微调后,往往会遗忘其他领域的知识,造成灾难性遗忘,这是核心问题。
- 论文提出ACT方法,通过分析模型激活,定位并迁移与特定能力相关的少量参数,实现能力迁移和恢复。
- 实验表明,ACT方法能够在多语言数学和科学推理任务中,恢复遗忘能力,同时保留原有技能。
📝 摘要(中文)
大型语言模型可以通过持续预训练或微调来提高在特定领域、语言或技能方面的性能,但这种专业化往往会降低其他能力,并可能导致灾难性遗忘。本文通过分析密切相关模型在领域和语言特定输入下的模块激活,研究了能力如何在LLM参数中分布。研究发现,跨层和模块的能力相关激活高度集中在一小部分通道中(通常<5%),并且这些通道在很大程度上是解耦的,具有良好的充分性和稳定性。基于这些观察,本文提出ACT(激活引导的通道级能力迁移),通过激活差异定位能力相关的通道,并选择性地仅迁移相应的参数,然后进行轻量级微调以实现兼容性。在多语言数学和科学推理上的实验表明,ACT可以恢复遗忘的能力,同时保留已掌握的技能。它还可以合并多个专门的模型,将多种能力集成到一个模型中,且干扰最小。代码和数据将公开发布。
🔬 方法详解
问题定义:大型语言模型在针对特定领域或任务进行微调时,往往会牺牲其在其他领域或任务上的表现,即出现“灾难性遗忘”现象。现有的解决方法要么需要大量的训练数据,要么会引入额外的模型参数,效率较低。因此,如何高效地将特定能力从一个模型迁移到另一个模型,同时避免灾难性遗忘,是一个亟待解决的问题。
核心思路:论文的核心思路是观察到模型的能力并非均匀分布在所有参数中,而是集中在少数特定的通道中。通过分析不同领域数据激活的通道,可以定位到与特定能力相关的参数。然后,只需要迁移这些关键参数,就可以实现能力的迁移和恢复,而无需修改整个模型。
技术框架:ACT方法主要包含以下几个步骤:1) 激活分析:使用特定领域的数据输入模型,记录每一层每个模块的激活值。2) 通道定位:计算不同领域数据激活值的差异,以此来定位与特定能力相关的通道。具体来说,选择激活差异最大的前K%的通道。3) 参数迁移:将定位到的通道对应的参数从源模型迁移到目标模型。4) 轻量级微调:为了使迁移的参数与目标模型更好地兼容,进行轻量级的微调。
关键创新:ACT方法的关键创新在于其激活引导的通道级参数选择性迁移策略。与传统的全参数迁移或微调方法不同,ACT只关注与特定能力相关的少量参数,从而大大提高了迁移效率,并降低了对其他能力的干扰。这种方法能够更精确地控制模型的行为,实现更细粒度的能力迁移。
关键设计:在通道定位阶段,论文使用了激活差异作为选择标准,并设置了一个阈值来控制选择的通道数量。在参数迁移阶段,直接将源模型的参数复制到目标模型中。在轻量级微调阶段,使用了较小的学习率和较少的训练轮数,以避免过度拟合。具体激活差异的计算方式和阈值的选择,以及微调的学习率和训练轮数等超参数,需要根据具体的任务和模型进行调整。
🖼️ 关键图片
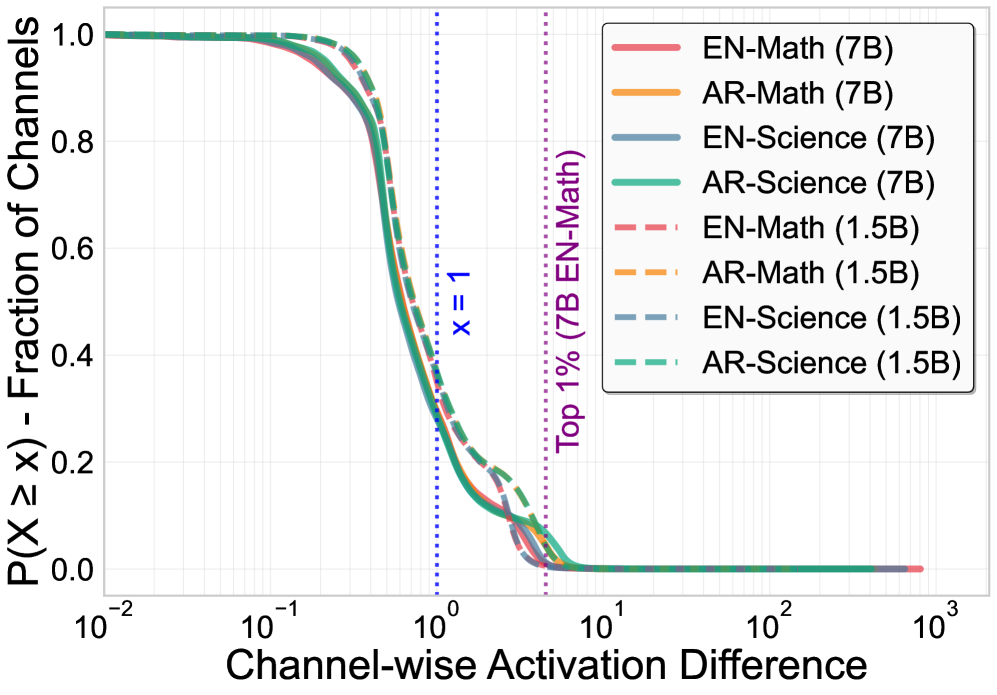
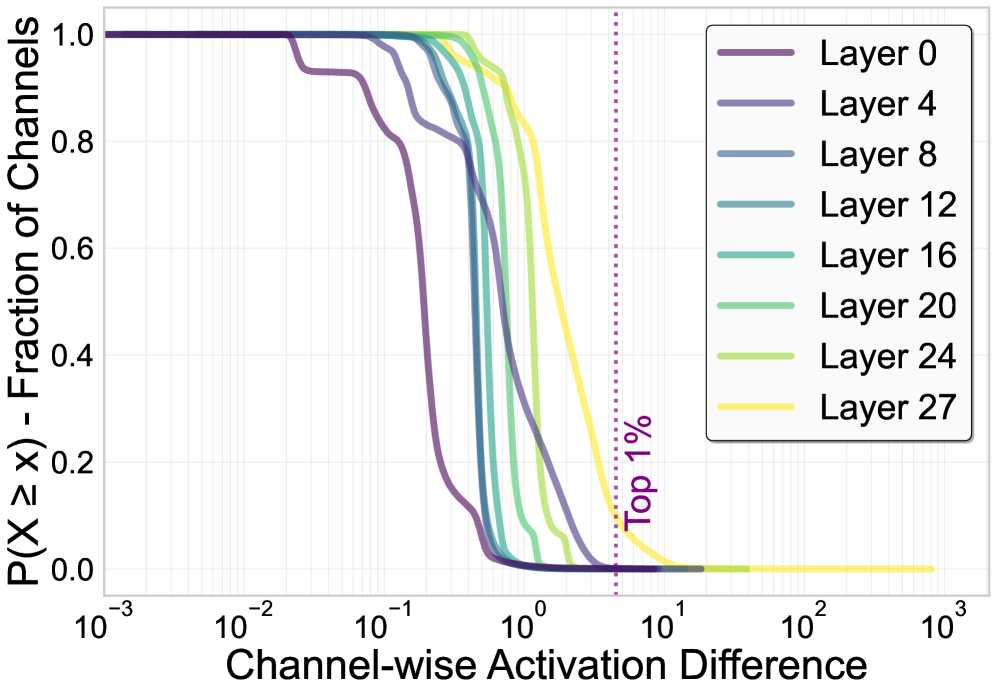
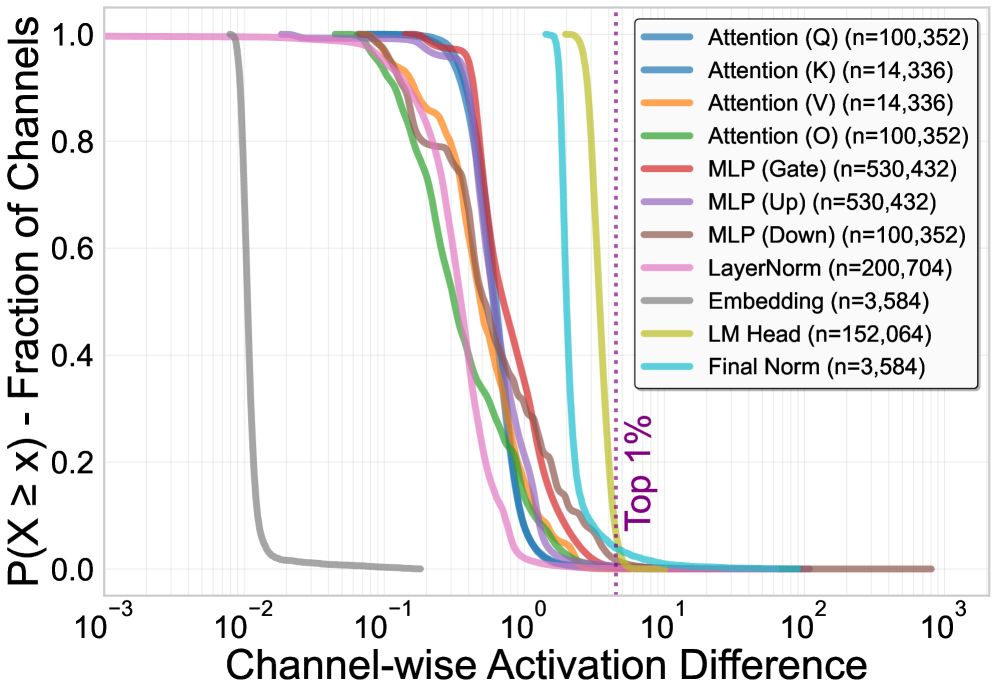
📊 实验亮点
实验结果表明,ACT方法在多语言数学和科学推理任务中,能够有效恢复遗忘的能力,同时保持原有技能。例如,在将一个擅长数学的模型迁移到科学领域后,使用ACT方法可以使其在数学任务上的性能损失最小化,同时在科学任务上取得显著提升。具体性能提升数据和对比基线将在论文中详细展示。
🎯 应用场景
ACT方法可应用于多语言模型的能力融合、领域知识迁移、以及模型修复等场景。例如,可以将一个擅长数学的模型和一个擅长科学的模型合并成一个同时具备两种能力的模型。此外,当模型出现性能下降时,可以通过迁移相关能力参数进行修复。该方法有助于构建更通用、更灵活的大型语言模型。
📄 摘要(原文)
Large language models can be continually pre-trained or fine-tuned to improve performance in specific domains, languages, or skills, but this specialization often degrades other capabilities and may cause catastrophic forgetting. We investigate how abilities are distributed within LLM parameters by analyzing module activations under domain- and language-specific inputs for closely related models. Across layers and modules, we find that ability-related activations are highly concentrated in a small set of channels (typically <5\%), and these channels are largely disentangled with good sufficiency and stability. Building on these observations, we propose ACT (Activation-Guided Channel-wise Ability Transfer), which localizes ability-relevant channels via activation differences and selectively transfers only the corresponding parameters, followed by lightweight fine-tuning for compatibility. Experiments on multilingual mathematical and scientific reasoning show that ACT can recover forgotten abilities while preserving retained skills. It can also merge multiple specialized models to integrate several abilities into a single model with minimal interference. Our code and data will be publicly released.