SLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
作者: Ziyang Ma, Guanrou Yang, Wenxi Chen, Zhifu Gao, Yexing Du, Xiquan Li, Zhisheng Zheng, Haina Zhu, Jianheng Zhuo, Zheshu Song, Ruiyang Xu, Tiranrui Wang, Yifan Yang, Yanqiao Zhu, Zhikang Niu, Liumeng Xue, Yinghao Ma, Ruibin Yuan, Shiliang Zhang, Kai Yu, Eng Siong Chng, Xie Chen
分类: cs.SD, cs.CL, cs.MM
发布日期: 2026-01-14
备注: Published in IEEE Journal of Selected Topics in Signal Processing (JSTSP)
DOI: 10.1109/JSTSP.2026.3653157
💡 一句话要点
SLAM-LLM:一个模块化、开源的多模态大语言模型框架,专注于语音、语言、音频和音乐处理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 语音处理 音频处理 音乐处理 开源框架 深度学习 自动语音识别 自动音频字幕
📋 核心要点
- 现有MLLM框架对语音、音频和音乐等模态的支持不足,限制了音频-语言模型的发展,且开发成本高昂。
- SLAM-LLM框架提供模块化配置,支持定制化的MLLM训练,专注于语音、语言、音频和音乐处理任务。
- SLAM-LLM包含主流任务的训练和推理方案,以及高性能的检查点,部分任务已达到或接近最先进水平。
📝 摘要(中文)
随着开源多模态大语言模型(MLLM)框架(如LLaVA)的兴起,人工智能开发者和研究人员可以更便捷地开展工作。然而,大多数MLLM框架主要以视觉作为输入模态,对语音、音频和音乐模态的深入支持有限。这种情况阻碍了音频-语言模型的发展,并迫使研究人员花费大量精力在代码编写和超参数调整上。我们提出了SLAM-LLM,一个开源深度学习框架,旨在训练定制化的MLLM,专注于语音、语言、音频和音乐处理。SLAM-LLM提供了不同编码器、投影器、LLM和参数高效微调插件的模块化配置。SLAM-LLM还包括主流任务的详细训练和推理方案,以及高性能的检查点,如基于LLM的自动语音识别(ASR)、自动音频字幕(AAC)和音乐字幕(MC)。其中一些方案已经达到或接近最先进的性能,并且一些相关技术已被学术论文接受。我们希望SLAM-LLM能够加速研究人员的迭代、开发、数据工程和模型训练。我们致力于通过这个开源框架不断推进基于音频的MLLM,并呼吁社区为基于LLM的语音、音频和音乐处理做出贡献。
🔬 方法详解
问题定义:现有的大部分多模态大语言模型框架主要关注视觉模态,对语音、音频和音乐等模态的支持不足,导致研究人员在开发音频相关的多模态模型时需要投入大量的时间和精力进行代码编写和超参数调整。这阻碍了音频-语言模型的发展,并且缺乏一个统一、高效的开发平台。
核心思路:SLAM-LLM的核心思路是提供一个模块化、可配置的开源框架,允许研究人员灵活地选择和组合不同的编码器、投影器、大语言模型和参数高效微调插件,从而快速构建和训练定制化的多模态大语言模型,专注于语音、语言、音频和音乐处理任务。通过提供详细的训练和推理方案以及高性能的检查点,降低了开发门槛,加速了研究进程。
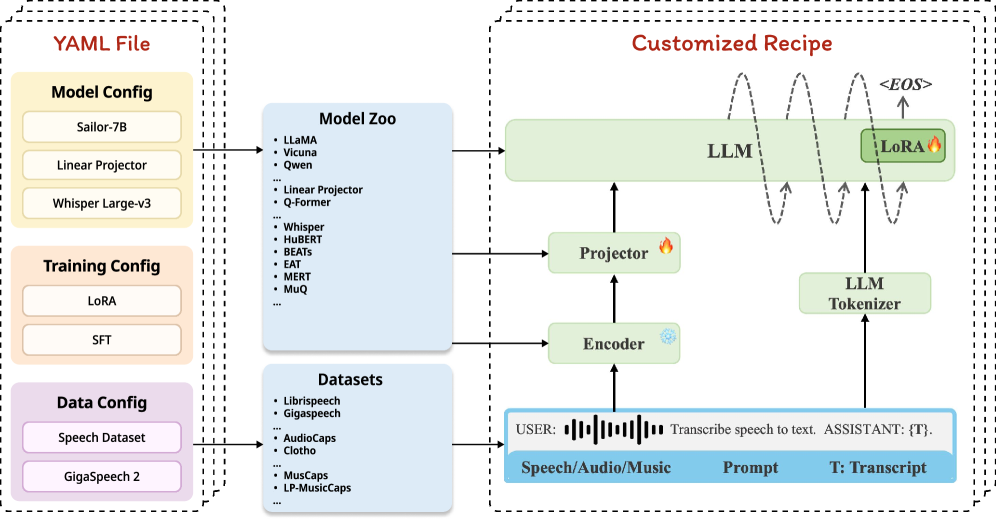
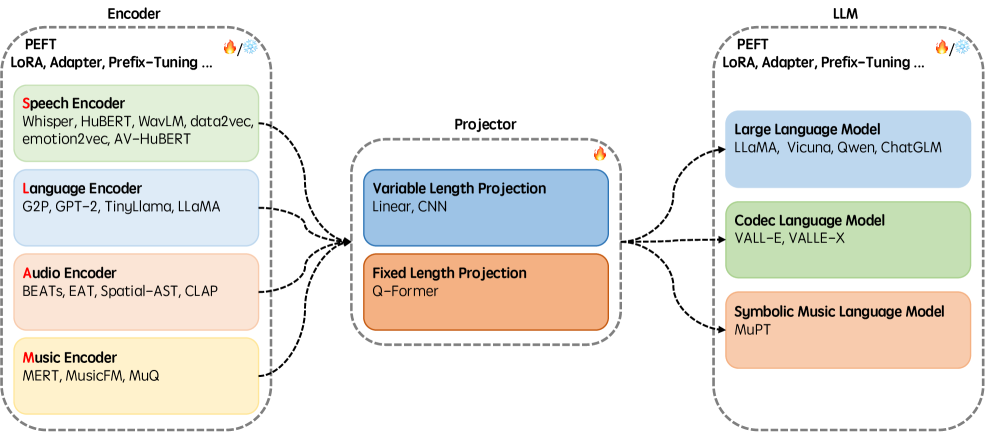
技术框架:SLAM-LLM的整体架构包括以下几个主要模块:1) 音频/语音/音乐编码器:用于提取音频、语音或音乐的特征表示。2) 投影器:将音频特征映射到与大语言模型兼容的嵌入空间。3) 大语言模型(LLM):用于处理和生成文本。4) 参数高效微调插件:用于在预训练的LLM上进行微调,以适应特定的任务。框架支持模块化的配置,允许用户根据需求选择不同的模块进行组合。
关键创新:SLAM-LLM的关键创新在于其模块化的设计和对语音、音频和音乐模态的专注。与现有的MLLM框架相比,SLAM-LLM提供了更丰富的音频编码器选择,并针对音频任务进行了优化。此外,框架还提供了详细的训练和推理方案,以及高性能的检查点,降低了开发难度。
关键设计:SLAM-LLM的关键设计包括:1) 模块化的架构,允许灵活组合不同的组件。2) 针对音频任务优化的编码器,例如用于语音识别的Conformer、用于音频分类的AST等。3) 参数高效微调策略,例如LoRA、Adapter等,以减少训练成本。4) 详细的训练和推理方案,包括数据预处理、超参数设置等。
🖼️ 关键图片
📊 实验亮点
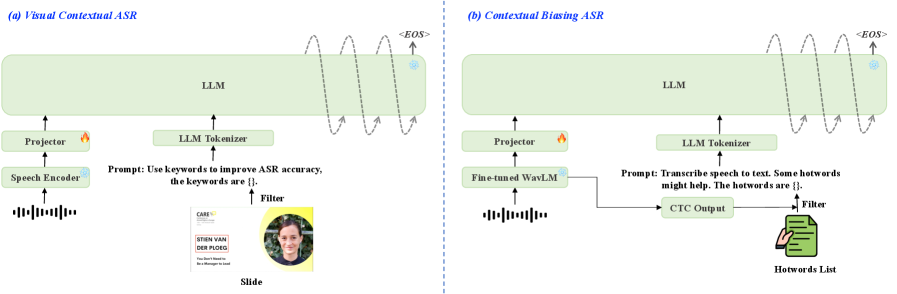
SLAM-LLM框架在多个音频处理任务上取得了显著成果。例如,在LLM-based自动语音识别(ASR)任务中,该框架的性能接近最先进水平。此外,在自动音频字幕(AAC)和音乐字幕(MC)任务中,SLAM-LLM也提供了高性能的检查点。这些实验结果表明,SLAM-LLM是一个有效且有竞争力的音频多模态大语言模型框架。
🎯 应用场景
SLAM-LLM框架可应用于多种场景,如自动语音识别、自动音频字幕、音乐字幕生成等。它能够帮助开发者快速构建和训练定制化的音频-语言模型,提升相关任务的性能。该框架的开源特性将促进社区合作,推动音频领域多模态大语言模型的发展,并可能催生新的应用场景,例如智能音乐创作、语音助手等。
📄 摘要(原文)
The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.