The Imperfective Paradox in Large Language Models
作者: Bolei Ma, Yusuke Miyao
分类: cs.CL
发布日期: 2026-01-14
💡 一句话要点
提出ImperfectiveNLI数据集以解决LLMs的语义理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不完美悖论 语义理解 ImperfectiveNLI 逻辑推理 事件组合语义 提示干预
📋 核心要点
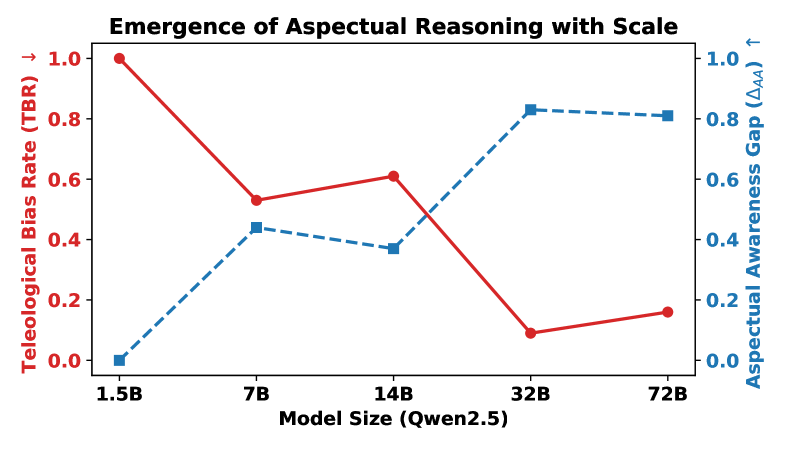
- 现有大型语言模型在理解事件的组合语义方面存在不足,特别是在处理不完美悖论时表现出系统性偏差。
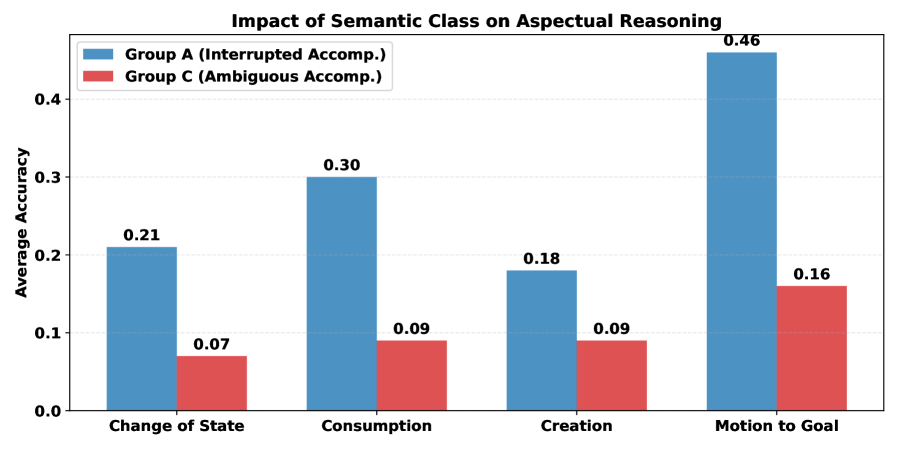
- 论文提出ImperfectiveNLI数据集,旨在通过对不同语义类别的探测,揭示LLMs在事件理解中的局限性。
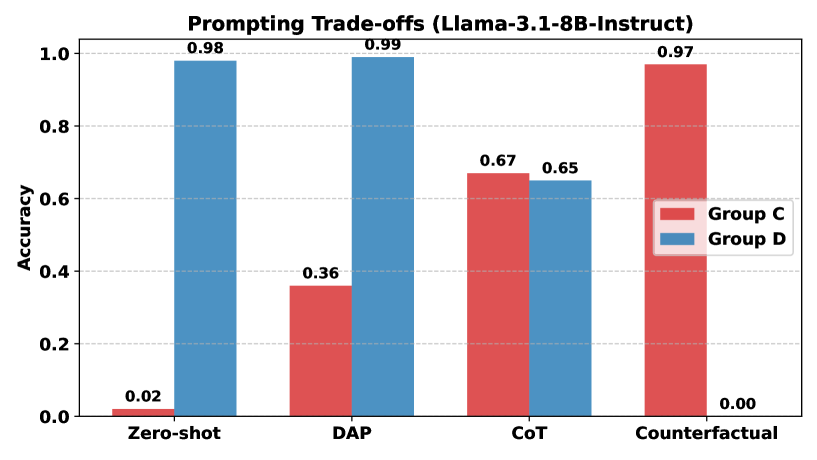
- 实验结果显示,虽然提示干预可以减少幻觉完成,但也导致对有效蕴涵的错误拒绝,表明LLMs的推理能力仍需提升。
📝 摘要(中文)
本文探讨大型语言模型(LLMs)是否真正理解事件的组合语义,还是仅依赖表面概率启发式。我们研究了不完美悖论,这是一种逻辑现象,过去进行时态对活动(如跑步)意味着事件实现,但对成就(如建造)则不然。为此,我们引入了ImperfectiveNLI,一个旨在探测不同语义类别之间区别的诊断数据集。通过对最先进的开放权重模型的评估,我们发现模型在目标导向事件上系统性地幻觉完成,常常覆盖明确的文本否定。我们的研究表明,当前的LLMs缺乏结构性时态意识,更多地作为预测叙事引擎而非忠实的逻辑推理者。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在理解事件组合语义时的局限性,特别是在不完美悖论的背景下,现有模型常常依赖表面概率而非深层逻辑推理。
核心思路:通过引入ImperfectiveNLI数据集,论文探讨了如何有效评估和揭示LLMs在处理不同语义类别时的表现差异,尤其是活动与成就之间的区分。
技术框架:研究采用了开放权重模型进行评估,分析了模型在不同语义任务上的表现,并通过提示干预方法进行实验,观察其对模型推理能力的影响。
关键创新:ImperfectiveNLI数据集的引入是本研究的核心创新,它为评估LLMs在时态理解上的能力提供了新的视角,揭示了模型在目标导向事件上的系统性幻觉。
关键设计:在实验中,采用了多种提示策略来干预模型的推理过程,设置了不同的参数以观察其对模型输出的影响,并分析了模型内部嵌入的表现。实验结果显示,尽管提示干预减少了幻觉完成,但也增加了对有效蕴涵的错误拒绝。
🖼️ 关键图片
📊 实验亮点
实验结果表明,当前的LLMs在处理目标导向事件时存在显著的幻觉完成现象,尤其是在明确的文本否定情况下。提示干预虽然减少了幻觉完成,但也导致了对有效蕴涵的错误拒绝,显示出模型推理能力的不足。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和智能助手等。通过提升大型语言模型在事件理解上的能力,可以增强其在实际应用中的表现,尤其是在需要准确推理和理解复杂语义的场景中。未来,该研究可能推动更具逻辑推理能力的语言模型的发展。
📄 摘要(原文)
Do Large Language Models (LLMs) genuinely grasp the compositional semantics of events, or do they rely on surface-level probabilistic heuristics? We investigate the Imperfective Paradox, a logical phenomenon where the past progressive aspect entails event realization for activities (e.g., running $\to$ ran) but not for accomplishments (e.g., building $\nrightarrow$ built). We introduce ImperfectiveNLI, a diagnostic dataset designed to probe this distinction across diverse semantic classes. Evaluating state-of-the-art open-weight models, we uncover a pervasive Teleological Bias: models systematically hallucinate completion for goal-oriented events, often overriding explicit textual negation. Representational analyses show that while internal embeddings often distinguish process from result, inference decisions are dominated by strong priors about goal attainment. We further find that prompting-based interventions reduce hallucinated completions but also increase incorrect rejections of valid entailments. Our findings suggest that current LLMs lack structural aspectual awareness, operating as predictive narrative engines rather than faithful logical reasoners.