Relation Extraction Capabilities of LLMs on Clinical Text: A Bilingual Evaluation for English and Turkish
作者: Aidana Aidynkyzy, Oğuz Dikenelli, Oylum Alatlı, Şebnem Bora
分类: cs.CL
发布日期: 2026-01-14
💡 一句话要点
提出Relation-Aware Retrieval,用于提升LLM在临床文本关系抽取中的性能,并构建了英土双语数据集。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关系抽取 大型语言模型 临床自然语言处理 上下文学习 对比学习
📋 核心要点
- 现有临床信息抽取方法在非英语语种上缺乏标注数据,限制了大型语言模型(LLM)的应用和评估。
- 提出Relation-Aware Retrieval (RAR)方法,利用对比学习捕获句子和关系层面的语义信息,提升上下文学习效果。
- 实验结果表明,基于提示的LLM方法优于微调模型,RAR方法在英土双语上均取得最佳性能,最高F1值达0.918。
📝 摘要(中文)
本研究针对非英语语言中临床信息抽取标注数据集稀缺的问题,提出了首个针对英语和土耳其语临床关系抽取(RE)任务的大型语言模型(LLM)双语评估。为了方便评估,我们构建了首个英-土平行临床RE数据集,该数据集源自并精心整理自2010 i2b2/VA关系分类语料库。我们系统地评估了一系列提示策略,包括多种上下文学习(ICL)和思维链(CoT)方法,并将它们的性能与微调基线(如PURE)进行比较。此外,我们提出了一种基于对比学习的新型上下文示例选择方法Relation-Aware Retrieval (RAR),专门用于捕获句子级和关系级语义。结果表明,基于提示的LLM方法始终优于传统的微调模型。而且,英语评估的表现优于所有评估的LLM和提示技术中的土耳其语评估。在ICL方法中,RAR实现了最高的性能,Gemini 1.5 Flash在英语中的micro-F1得分为0.906,在土耳其语中为0.888。当RAR与使用DeepSeek-V3模型的结构化推理提示相结合时,英语性能进一步提高到0.918 F1。这些发现强调了高质量演示检索的重要性,并强调了先进的检索和提示技术在弥合临床自然语言处理中的资源差距方面的潜力。
🔬 方法详解
问题定义:论文旨在解决临床文本关系抽取任务中,由于非英语语种标注数据稀缺,导致大型语言模型(LLM)在该领域应用受限的问题。现有方法,如传统的微调模型,在数据量不足的情况下表现不佳;而直接应用在英语语料上训练的LLM到其他语种,效果往往会大打折扣。因此,如何有效利用LLM的知识,在低资源场景下提升临床文本关系抽取性能,是本文要解决的核心问题。
核心思路:论文的核心思路是利用对比学习,学习句子和关系层面的语义表示,并基于此进行上下文示例检索,从而提升LLM的上下文学习能力。通过构建Relation-Aware Retrieval (RAR)方法,使得LLM能够更好地理解输入文本的关系,并选择相关的示例进行学习,从而提高关系抽取的准确率。这种方法避免了对LLM进行大规模的微调,降低了计算成本,同时也更适用于低资源场景。
技术框架:整体框架包括以下几个主要模块:1) 数据集构建:构建英-土平行临床RE数据集,用于模型的训练和评估。2) Relation-Aware Embedding:利用对比学习训练句子和关系层面的嵌入表示。3) Relation-Aware Retrieval (RAR):基于学习到的嵌入表示,检索与输入文本相关的上下文示例。4) Prompting:设计不同的提示策略,包括In-Context Learning (ICL)和Chain-of-Thought (CoT),引导LLM进行关系抽取。5) LLM Inference:使用不同的LLM(如Gemini 1.5 Flash, DeepSeek-V3)进行关系抽取,并评估其性能。
关键创新:论文的关键创新在于提出了Relation-Aware Retrieval (RAR)方法。与传统的上下文示例选择方法不同,RAR不仅考虑了句子层面的语义相似度,还考虑了关系层面的语义相似度。通过对比学习,RAR能够学习到更具区分性的句子和关系表示,从而更准确地检索到相关的上下文示例。这种方法能够有效提升LLM在低资源场景下的关系抽取性能。
关键设计:RAR的关键设计包括:1) 对比学习损失函数:用于训练句子和关系嵌入表示,目标是使相似的句子/关系在嵌入空间中更接近,不相似的句子/关系更远离。2) 上下文示例检索策略:基于学习到的嵌入表示,计算输入文本与候选示例之间的相似度,选择相似度最高的K个示例作为上下文。3) Prompting策略:设计不同的提示模板,引导LLM进行关系抽取,例如使用Chain-of-Thought (CoT)提示,引导LLM逐步推理。
🖼️ 关键图片
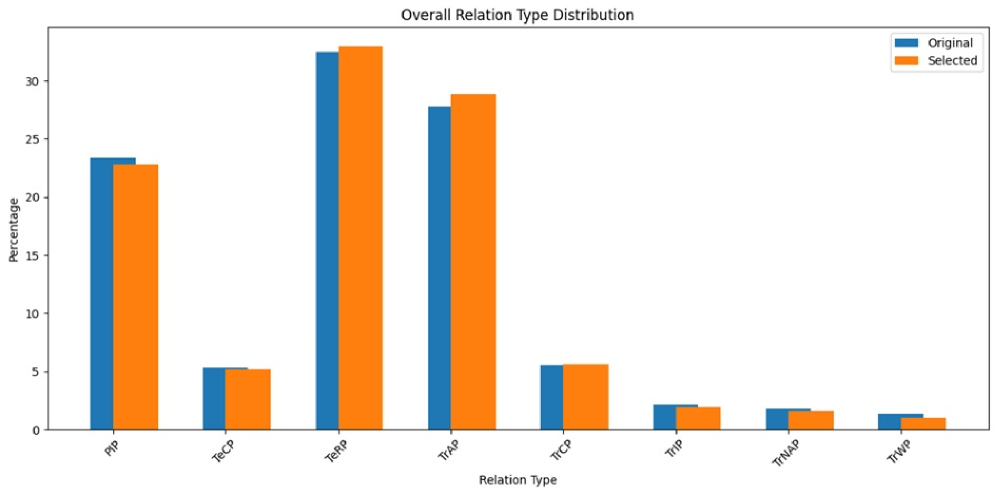
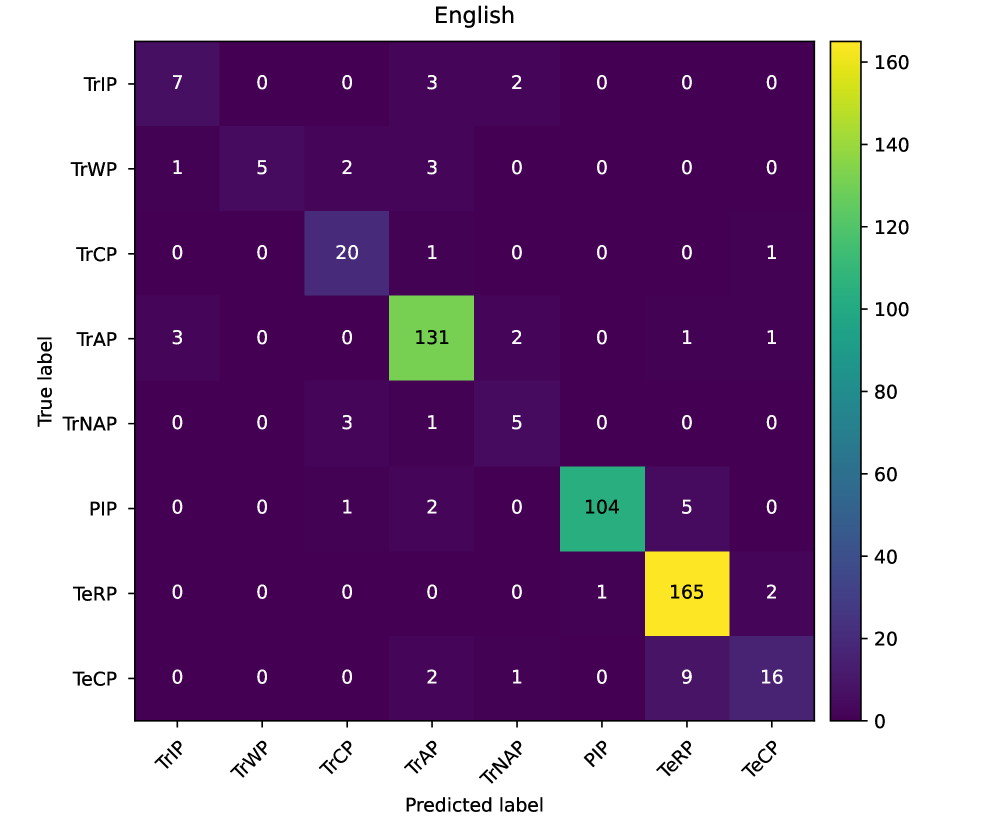
📊 实验亮点
实验结果表明,基于提示的LLM方法优于传统的微调模型。Relation-Aware Retrieval (RAR)方法在英土双语上均取得最佳性能,Gemini 1.5 Flash在英语中的micro-F1得分为0.906,在土耳其语中为0.888。当RAR与DeepSeek-V3模型的结构化推理提示相结合时,英语性能进一步提高到0.918 F1。这些结果表明,高质量的上下文示例检索和先进的提示技术能够有效提升LLM在临床文本关系抽取方面的性能。
🎯 应用场景
该研究成果可应用于临床自然语言处理领域,例如辅助医生进行病历分析、药物研发和临床决策支持。通过提升LLM在临床文本关系抽取方面的性能,可以更有效地从海量医疗数据中提取有价值的信息,从而提高医疗效率和质量。此外,该研究构建的英-土平行临床RE数据集,也有助于推动多语言临床自然语言处理的发展。
📄 摘要(原文)
The scarcity of annotated datasets for clinical information extraction in non-English languages hinders the evaluation of large language model (LLM)-based methods developed primarily in English. In this study, we present the first comprehensive bilingual evaluation of LLMs for the clinical Relation Extraction (RE) task in both English and Turkish. To facilitate this evaluation, we introduce the first English-Turkish parallel clinical RE dataset, derived and carefully curated from the 2010 i2b2/VA relation classification corpus. We systematically assess a diverse set of prompting strategies, including multiple in-context learning (ICL) and Chain-of-Thought (CoT) approaches, and compare their performance to fine-tuned baselines such as PURE. Furthermore, we propose Relation-Aware Retrieval (RAR), a novel in-context example selection method based on contrastive learning, that is specifically designed to capture both sentence-level and relation-level semantics. Our results show that prompting-based LLM approaches consistently outperform traditional fine-tuned models. Moreover, evaluations for English performed better than their Turkish counterparts across all evaluated LLMs and prompting techniques. Among ICL methods, RAR achieves the highest performance, with Gemini 1.5 Flash reaching a micro-F1 score of 0.906 in English and 0.888 in Turkish. Performance further improves to 0.918 F1 in English when RAR is combined with a structured reasoning prompt using the DeepSeek-V3 model. These findings highlight the importance of high-quality demonstration retrieval and underscore the potential of advanced retrieval and prompting techniques to bridge resource gaps in clinical natural language processing.