MCGA: A Multi-task Classical Chinese Literary Genre Audio Corpus
作者: Yexing Du, Kaiyuan Liu, Bihe Zhang, Youcheng Pan, Bo Yang, Liangyu Huo, Xiyuan Zhang, Jian Xie, Daojing He, Yang Xiang, Ming Liu, Bin Qin
分类: cs.CL
发布日期: 2026-01-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出MCGA:一个面向多任务的古文音频语料库,促进多模态大模型在古文研究中的应用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 古文音频语料库 多模态大模型 语音识别 语音翻译 情感识别 口语问答 语音理解 语音推理
📋 核心要点
- 现有研究主要集中于文本和视觉模态,缺乏对古文领域音频数据的探索,限制了多模态大模型在该领域的应用。
- 构建包含多种古文体裁和任务的音频语料库MCGA,旨在促进多模态大模型在古文研究中对音频信息的理解和利用。
- 实验结果表明,现有模型在MCGA测试集上表现不佳,同时提出了针对语音情感描述任务的评估指标和一致性衡量指标。
📝 摘要(中文)
随着多模态大语言模型(MLLMs)的快速发展,它们在中国古典研究(CCS)中的潜力受到了广泛关注。然而,现有研究主要集中在文本和视觉模态,而该领域的音频语料库在很大程度上仍未被充分探索。为了弥补这一差距,我们提出了多任务古文音频语料库(MCGA)。它涵盖了六个任务中各种文学类型:自动语音识别(ASR)、语音到文本翻译(S2TT)、语音情感描述(SEC)、口语问答(SQA)、语音理解(SU)和语音推理(SR)。通过对十个MLLM的评估,我们的实验结果表明,当前的模型在MCGA测试集上处理时仍然面临着巨大的挑战。此外,我们还为SEC引入了一个评估指标,并提出了一个衡量MLLM语音和文本能力之间一致性的指标。我们将公开发布MCGA和我们的代码,以促进MLLM的开发,使其在CCS中具有更强大的多维音频能力。
🔬 方法详解
问题定义:论文旨在解决古文研究领域中缺乏高质量、多任务音频语料库的问题。现有方法主要集中于文本和视觉模态,忽略了音频信息,限制了多模态大模型在古文研究中的应用。因此,需要构建一个包含多种古文体裁和任务的音频语料库,以促进多模态大模型对音频信息的理解和利用。
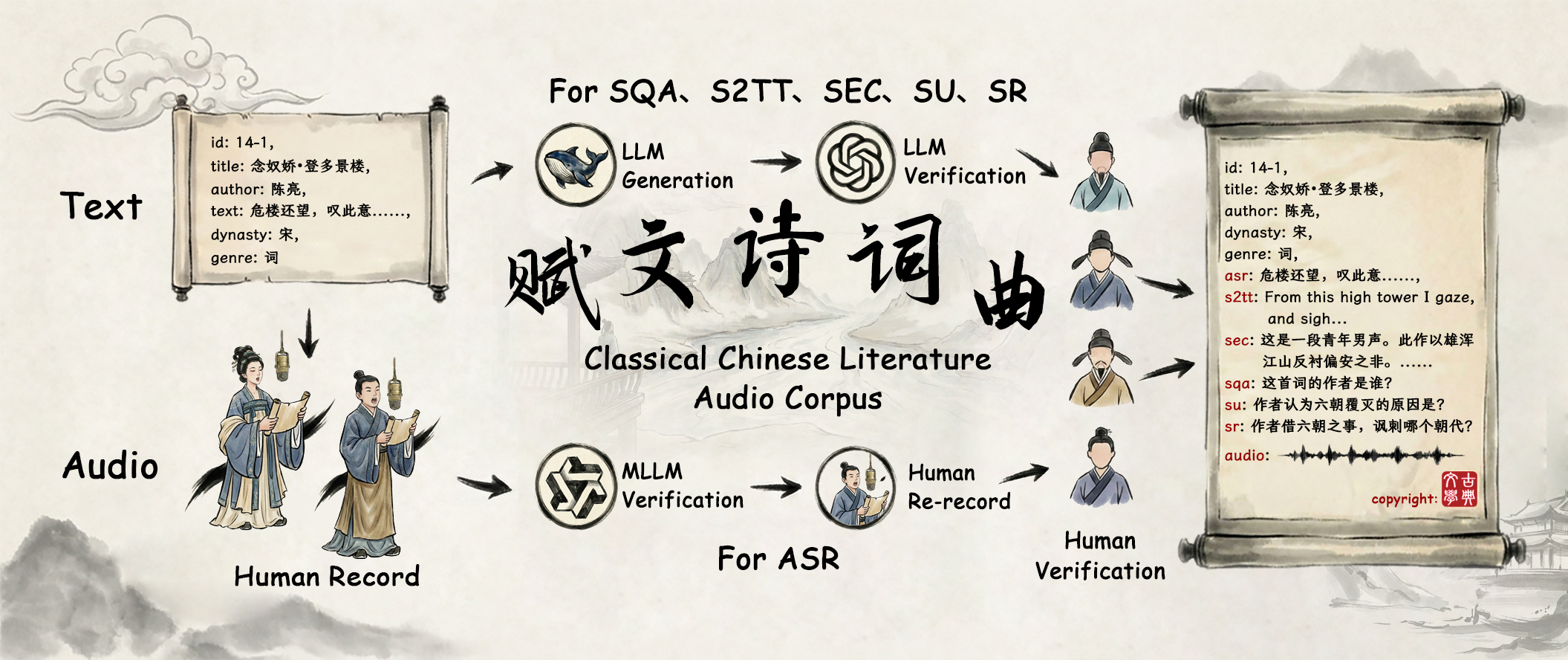
核心思路:论文的核心思路是构建一个多任务的古文音频语料库MCGA,该语料库涵盖了六个任务:自动语音识别(ASR)、语音到文本翻译(S2TT)、语音情感描述(SEC)、口语问答(SQA)、语音理解(SU)和语音推理(SR)。通过构建这样一个多任务的语料库,可以促进多模态大模型对古文音频信息的全面理解和利用。
技术框架:MCGA语料库的构建主要包括数据收集、数据清洗、数据标注和任务划分等步骤。数据收集主要从现有的古文音频资源中获取,数据清洗主要去除噪声和无关信息,数据标注主要对音频数据进行文本标注、情感标注等,任务划分主要将语料库划分为六个任务,每个任务包含不同的数据和评估指标。
关键创新:论文的关键创新在于构建了一个多任务的古文音频语料库MCGA,该语料库涵盖了六个任务,并且提出了针对语音情感描述任务的评估指标和一致性衡量指标。与现有方法相比,MCGA语料库更加全面和多样化,可以更好地促进多模态大模型对古文音频信息的理解和利用。
关键设计:MCGA语料库的关键设计包括任务划分、数据标注和评估指标。任务划分主要根据古文研究的实际需求进行,数据标注主要采用人工标注和自动标注相结合的方式,评估指标主要包括准确率、召回率、F1值等。此外,论文还提出了针对语音情感描述任务的评估指标和一致性衡量指标,以更好地评估多模态大模型在古文音频信息处理方面的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有模型在MCGA测试集上表现不佳,这表明古文音频处理对多模态大模型提出了新的挑战。同时,论文提出的针对语音情感描述任务的评估指标和一致性衡量指标,为评估多模态大模型在古文音频信息处理方面的性能提供了新的方法。
🎯 应用场景
该研究成果可应用于古文教育、古文研究、智能语音助手等领域。通过利用MCGA语料库,可以训练出更强大的多模态大模型,从而提高古文学习的效率和趣味性,促进古文研究的深入发展,并为智能语音助手提供更准确、更自然的古文语音交互能力。
📄 摘要(原文)
With the rapid advancement of Multimodal Large Language Models (MLLMs), their potential has garnered significant attention in Chinese Classical Studies (CCS). While existing research has primarily focused on text and visual modalities, the audio corpus within this domain remains largely underexplored. To bridge this gap, we propose the Multi-task Classical Chinese Literary Genre Audio Corpus (MCGA). It encompasses a diverse range of literary genres across six tasks: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Captioning (SEC), Spoken Question Answering (SQA), Speech Understanding (SU), and Speech Reasoning (SR). Through the evaluation of ten MLLMs, our experimental results demonstrate that current models still face substantial challenges when processed on the MCGA test set. Furthermore, we introduce an evaluation metric for SEC and a metric to measure the consistency between the speech and text capabilities of MLLMs. We release MCGA and our code to the public to facilitate the development of MLLMs with more robust multidimensional audio capabilities in CCS. MCGA Corpus: https://github.com/yxduir/MCGA