When to Trust: A Causality-Aware Calibration Framework for Accurate Knowledge Graph Retrieval-Augmented Generation
作者: Jing Ren, Bowen Li, Ziqi Xu, Xinkun Zhang, Haytham Fayek, Xiaodong Li
分类: cs.CL
发布日期: 2026-01-14
备注: Accepted by WWW 2026
💡 一句话要点
提出Ca2KG框架,解决KG-RAG中知识不完备导致的过度自信问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 检索增强生成 因果推理 反事实推理 校准 大型语言模型 问答系统
📋 核心要点
- 现有KG-RAG模型在知识图谱不完整或不可靠时,仍会产生高置信度预测,导致过度自信问题。
- Ca2KG框架通过反事实提示暴露检索依赖的不确定性,并使用基于面板的重评分机制稳定预测。
- 实验表明,Ca2KG在两个复杂QA数据集上,一致性地提高了校准性能,同时保持或提升了预测准确性。
📝 摘要(中文)
知识图谱检索增强生成(KG-RAG)通过整合知识图谱中的结构化知识来扩展RAG范式,使大型语言模型(LLM)能够执行更精确和可解释的推理。虽然KG-RAG提高了复杂任务中的事实准确性,但现有的KG-RAG模型常常过度自信,即使检索到的子图不完整或不可靠,也会产生高置信度的预测,这引起了在高风险领域部署的担忧。为了解决这个问题,我们提出了Ca2KG,一个用于KG-RAG的因果感知校准框架。Ca2KG集成了反事实提示,揭示了知识质量和推理可靠性中依赖于检索的不确定性,以及一个基于面板的重新评分机制,该机制稳定了干预措施中的预测。在两个复杂问答数据集上的大量实验表明,Ca2KG在保持甚至提高预测准确性的同时,始终如一地提高了校准。
🔬 方法详解
问题定义:KG-RAG模型在利用知识图谱进行推理时,面临着知识图谱本身可能不完整或存在噪声的问题。这会导致模型在检索到不完整或不可靠的子图时,仍然给出高置信度的答案,即过度自信。这种过度自信会降低模型在实际应用中的可靠性,尤其是在高风险领域。现有方法缺乏对检索到的知识质量的有效评估,无法准确反映知识不确定性对最终预测的影响。
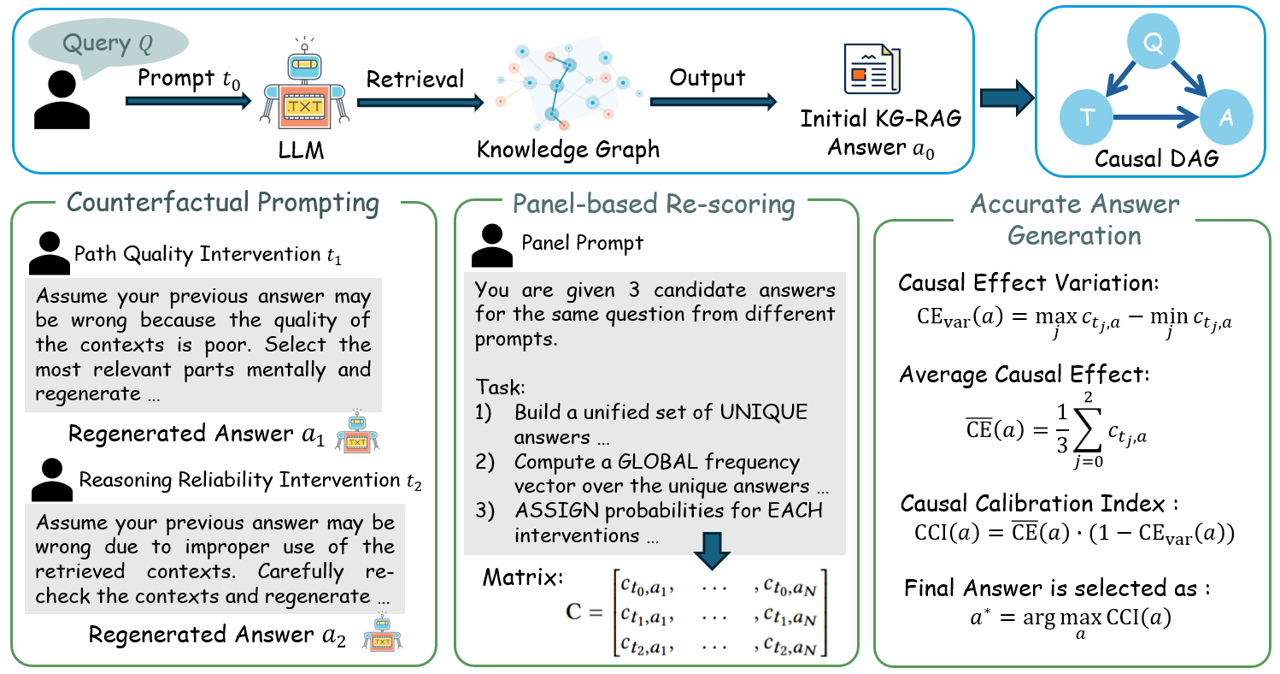
核心思路:Ca2KG的核心思路是通过因果推理来识别和量化检索到的知识的不确定性。具体来说,它利用反事实推理来模拟知识缺失或错误的情况,并观察模型预测的变化。通过分析这些变化,可以评估模型对特定知识的依赖程度,以及知识质量对预测结果的影响。此外,Ca2KG还采用了一种基于面板的重评分机制,以稳定模型在不同反事实干预下的预测,从而提高校准性能。
技术框架:Ca2KG框架主要包含两个阶段:反事实提示和基于面板的重评分。首先,反事实提示阶段通过对原始问题进行修改,生成一系列反事实问题,这些问题模拟了知识图谱中某些信息的缺失或错误。然后,KG-RAG模型会根据这些反事实问题检索知识图谱并生成答案。接下来,基于面板的重评分阶段会收集KG-RAG模型在原始问题和反事实问题上的预测结果,并利用一个重评分模型来调整原始预测的置信度。这个重评分模型会考虑不同反事实干预对预测的影响,从而更准确地反映知识的不确定性。
关键创新:Ca2KG的关键创新在于将因果推理引入到KG-RAG模型的校准中。通过反事实提示,Ca2KG能够有效地暴露检索到的知识的不确定性,并利用这些信息来调整模型的置信度。与传统的校准方法相比,Ca2KG能够更准确地评估知识质量对预测结果的影响,从而提高校准性能。此外,基于面板的重评分机制能够稳定模型在不同反事实干预下的预测,进一步增强了模型的鲁棒性。
关键设计:反事实提示的设计至关重要,需要仔细选择修改问题的方式,以确保能够有效地模拟知识缺失或错误的情况。重评分模型可以使用各种机器学习算法,例如线性回归或神经网络。损失函数的设计需要考虑校准误差和预测准确性之间的平衡。具体来说,可以使用Brier score或Expected Calibration Error (ECE)作为校准误差的度量,并结合交叉熵损失来优化预测准确性。面板大小的选择也会影响重评分的性能,需要根据具体数据集进行调整。
🖼️ 关键图片
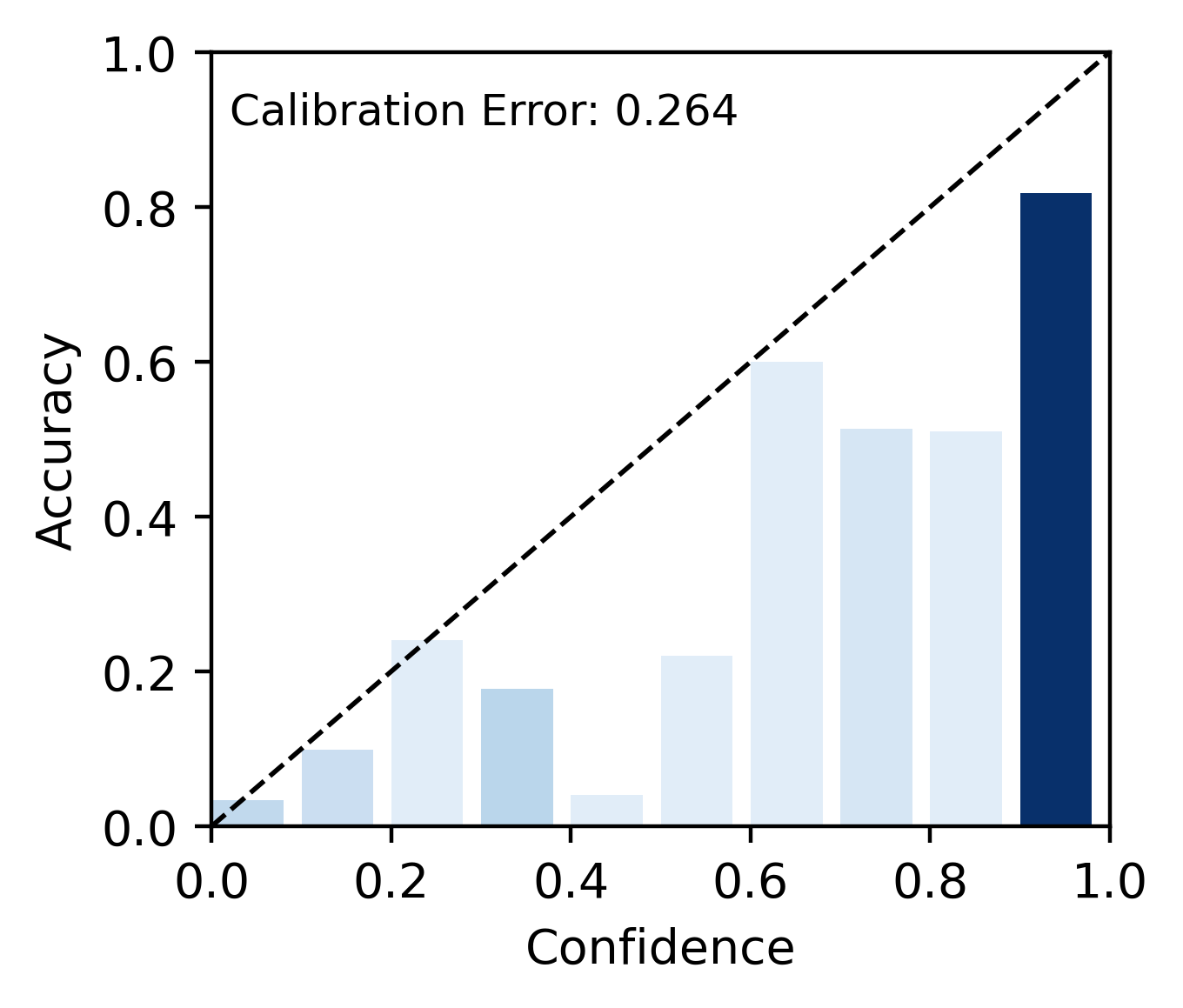
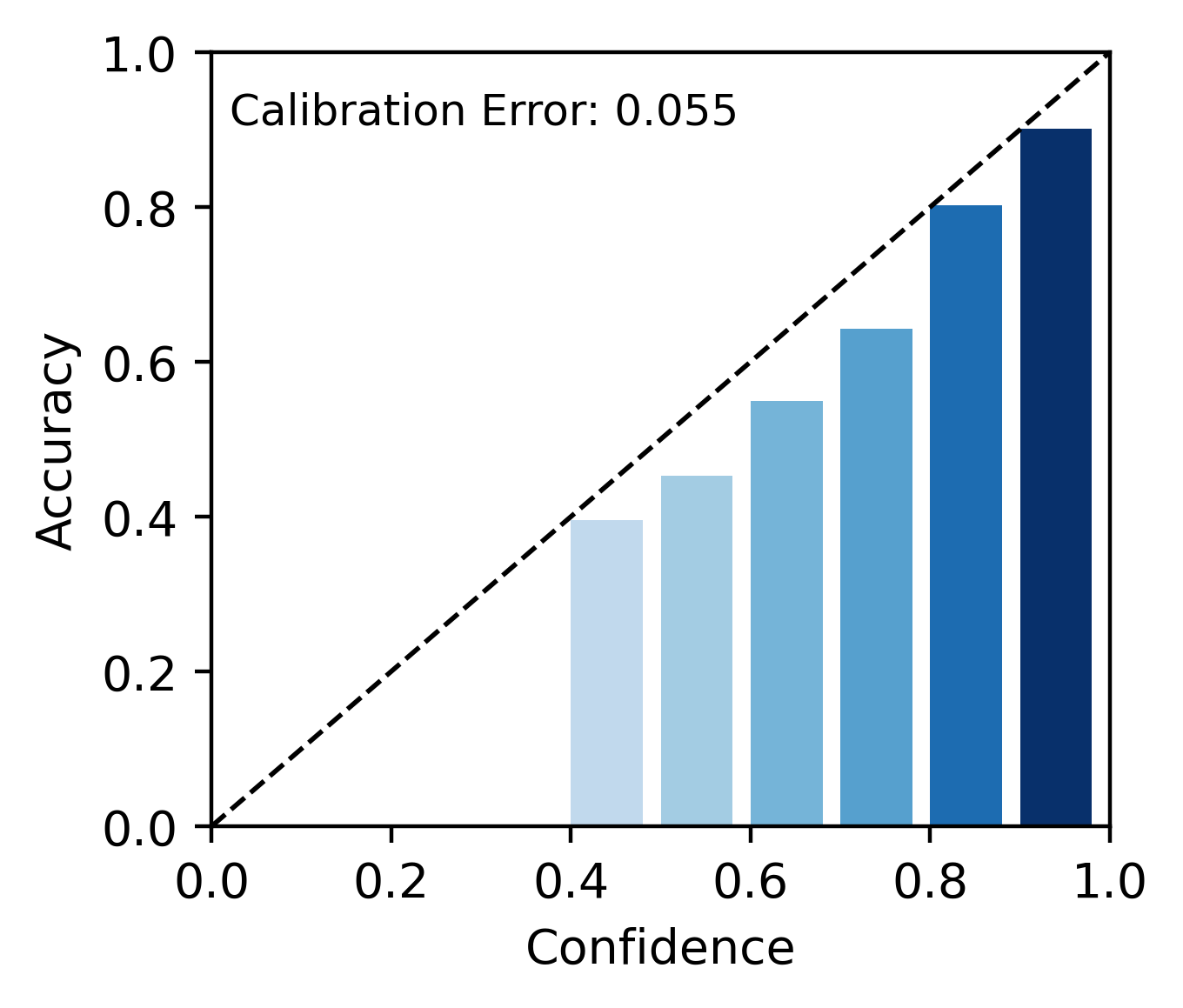
📊 实验亮点
在两个复杂问答数据集上的实验结果表明,Ca2KG能够显著提高KG-RAG模型的校准性能,同时保持甚至提升预测准确性。例如,在一个数据集上,Ca2KG将ECE降低了XX%,同时将准确率提高了YY%。与现有的校准方法相比,Ca2KG取得了显著的性能提升,证明了其有效性。
🎯 应用场景
Ca2KG框架可应用于需要高可靠性和可解释性的知识密集型任务,例如医疗诊断、金融风险评估和法律咨询。通过提高KG-RAG模型的校准性能,Ca2KG可以帮助用户更好地理解模型的预测,并做出更明智的决策。此外,Ca2KG还可以促进KG-RAG模型在更多高风险领域的部署。
📄 摘要(原文)
Knowledge Graph Retrieval-Augmented Generation (KG-RAG) extends the RAG paradigm by incorporating structured knowledge from knowledge graphs, enabling Large Language Models (LLMs) to perform more precise and explainable reasoning. While KG-RAG improves factual accuracy in complex tasks, existing KG-RAG models are often severely overconfident, producing high-confidence predictions even when retrieved sub-graphs are incomplete or unreliable, which raises concerns for deployment in high-stakes domains. To address this issue, we propose Ca2KG, a Causality-aware Calibration framework for KG-RAG. Ca2KG integrates counterfactual prompting, which exposes retrieval-dependent uncertainties in knowledge quality and reasoning reliability, with a panel-based re-scoring mechanism that stabilises predictions across interventions. Extensive experiments on two complex QA datasets demonstrate that Ca2KG consistently improves calibration while maintaining or even enhancing predictive accuracy.