UserLM-R1: Modeling Human Reasoning in User Language Models with Multi-Reward Reinforcement Learning
作者: Feng Zhang, Shijia Li, Chunmao Zhang, Zhanyu Ma, Jun Xu, Jiuchong Gao, Jinghua Hao, Renqing He, Jingwen Xu, Han Liu
分类: cs.CL
发布日期: 2026-01-14
💡 一句话要点
UserLM-R1:利用多奖励强化学习建模用户语言模型中的人类推理
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 用户模拟器 语言模型 强化学习 人类推理 对话系统 目标驱动 决策策略
📋 核心要点
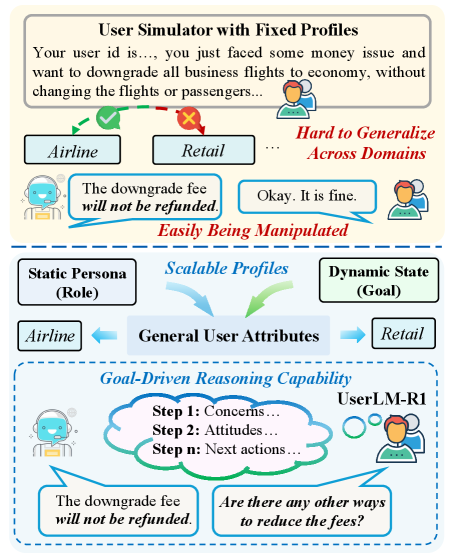
- 现有用户模拟器依赖静态配置文件,缺乏对上下文的感知,难以泛化到新领域,需要大量人工干预。
- UserLM-R1通过构建包含静态角色和动态目标的综合用户配置文件,并采用目标驱动的决策策略来模拟人类推理。
- 实验结果表明,UserLM-R1在用户模拟任务中优于现有基线方法,尤其在对抗性场景下表现更佳。
📝 摘要(中文)
用户模拟器是智能体后训练的关键交互环境,理想的用户模拟器应能跨领域泛化,并通过挑战或议价主动参与协商。然而,当前方法存在两个问题:它们依赖于静态且与上下文无关的配置文件,需要大量手动重新设计以适应新场景,从而限制了泛化能力;此外,它们忽略了人类的战略思维,导致容易受到智能体的操纵。为了解决这些问题,我们提出了UserLM-R1,一种具有推理能力的新型用户语言模型。具体来说,我们首先构建包含静态角色和动态场景特定目标的综合用户配置文件,以适应不同的场景。然后,我们提出了一种目标驱动的决策策略,在生成响应之前生成高质量的理由,并通过监督微调和多奖励强化学习进一步完善推理并提高战略能力。大量的实验结果表明,UserLM-R1优于竞争基线,尤其是在更具挑战性的对抗性数据集上。
🔬 方法详解
问题定义:现有用户模拟器主要存在两个痛点。一是泛化能力差,依赖静态和上下文无关的配置文件,需要针对不同场景进行大量手动调整。二是缺乏战略推理能力,容易被智能体利用,无法真实模拟人类用户的行为。
核心思路:UserLM-R1的核心思路是构建一个具有推理能力的用户语言模型,使其能够根据用户画像和场景目标,生成合理的决策过程和响应。通过引入推理链,模型能够更好地模拟人类的战略思维,从而提高用户模拟器的真实性和鲁棒性。
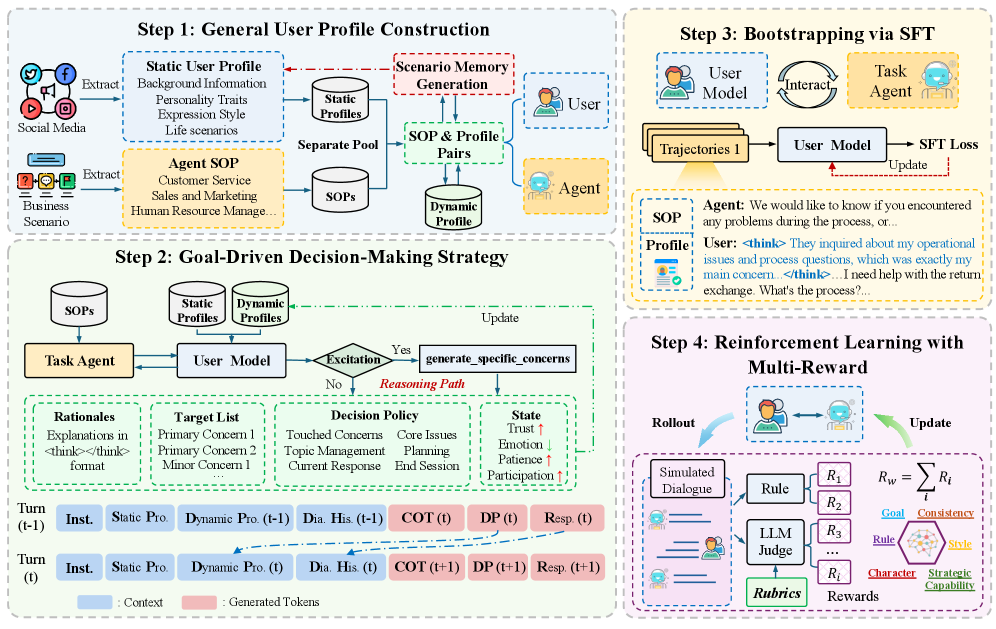
技术框架:UserLM-R1的整体框架包含以下几个主要模块:1) 用户画像构建模块,用于生成包含静态角色和动态场景特定目标的用户配置文件。2) 目标驱动的决策模块,用于根据用户画像和当前对话状态,生成推理链。3) 响应生成模块,用于根据推理链生成用户响应。4) 训练模块,使用监督微调和多奖励强化学习来优化模型的推理和战略能力。
关键创新:UserLM-R1的关键创新在于引入了目标驱动的决策策略,通过生成推理链来模拟人类的战略思维。与现有方法相比,UserLM-R1能够更好地理解用户的意图和目标,并生成更合理和更具挑战性的响应,从而提高用户模拟器的真实性和鲁棒性。
关键设计:在用户画像构建方面,论文结合了静态角色信息(如年龄、职业)和动态场景目标(如购买特定商品、达成特定协议)。在目标驱动的决策模块中,模型首先根据用户画像和对话状态生成一系列可能的推理步骤,然后选择最符合用户目标的推理链。在训练方面,论文采用了多奖励强化学习,结合了对话成功率、响应质量和推理合理性等多个奖励信号,以优化模型的整体性能。
🖼️ 关键图片
📊 实验亮点
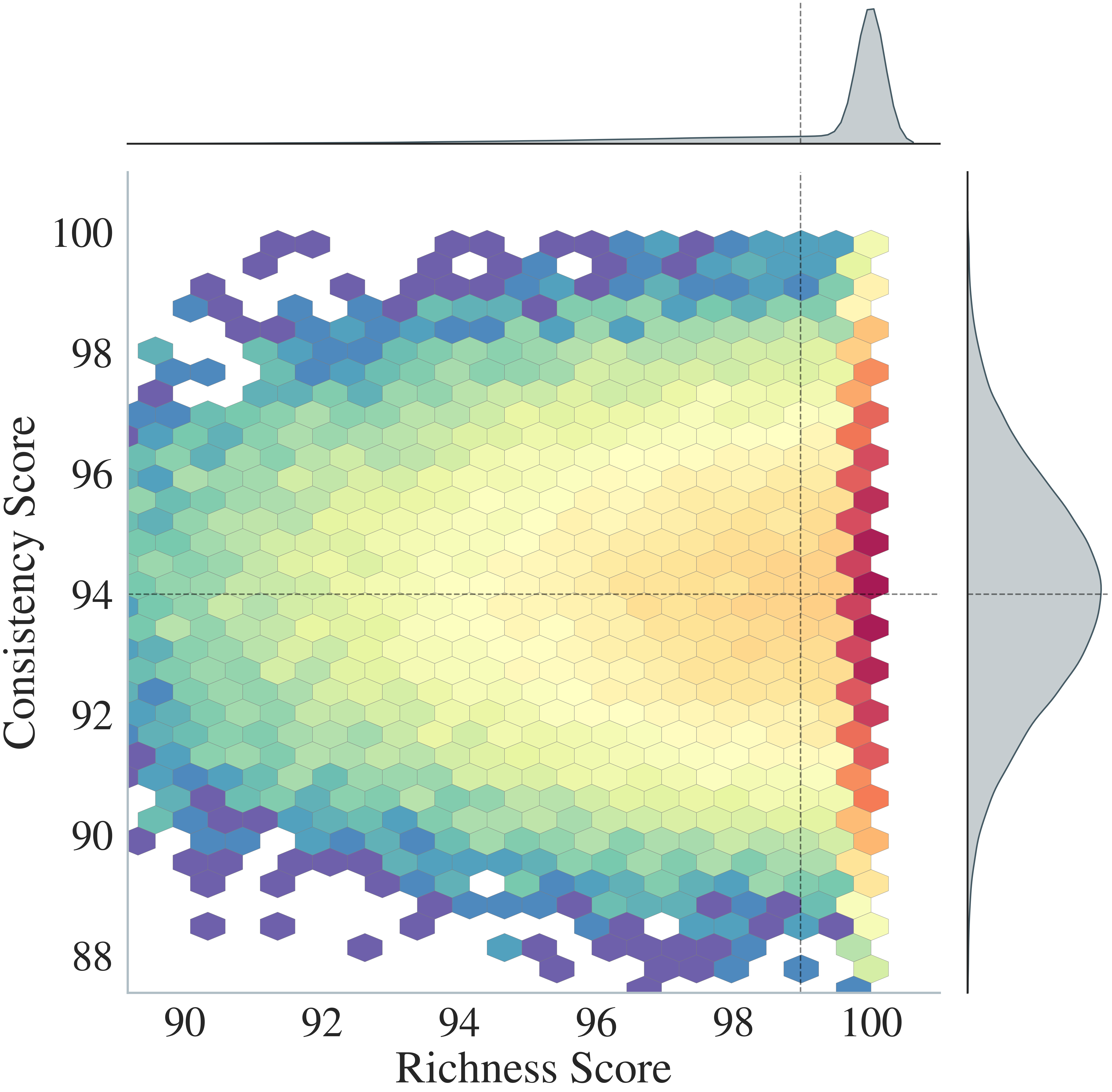
实验结果表明,UserLM-R1在用户模拟任务中显著优于现有基线方法。尤其是在对抗性数据集上,UserLM-R1的表现提升更为明显,表明其具有更强的战略推理能力和鲁棒性。具体性能提升数据未知,但强调了在更具挑战性的场景下的优势。
🎯 应用场景
UserLM-R1可应用于对话系统、谈判机器人、智能客服等领域,用于训练和评估智能体的性能。通过提供更真实和更具挑战性的用户模拟环境,UserLM-R1可以帮助智能体更好地学习人类的交互策略,提高其在实际应用中的鲁棒性和适应性。未来,该研究可以扩展到更复杂的场景,例如多方对话和跨领域对话。
📄 摘要(原文)
User simulators serve as the critical interactive environment for agent post-training, and an ideal user simulator generalizes across domains and proactively engages in negotiation by challenging or bargaining. However, current methods exhibit two issues. They rely on static and context-unaware profiles, necessitating extensive manual redesign for new scenarios, thus limiting generalizability. Moreover, they neglect human strategic thinking, leading to vulnerability to agent manipulation. To address these issues, we propose UserLM-R1, a novel user language model with reasoning capability. Specifically, we first construct comprehensive user profiles with both static roles and dynamic scenario-specific goals for adaptation to diverse scenarios. Then, we propose a goal-driven decision-making policy to generate high-quality rationales before producing responses, and further refine the reasoning and improve strategic capabilities with supervised fine-tuning and multi-reward reinforcement learning. Extensive experimental results demonstrate that UserLM-R1 outperforms competitive baselines, particularly on the more challenging adversarial set.