OrthoGeoLoRA: Geometric Parameter-Efficient Fine-Tuning for Structured Social Science Concept Retrieval on theWeb
作者: Zeqiang Wang, Xinyue Wu, Chenxi Li, Zixi Chen, Nishanth Sastry, Jon Johnson, Suparna De
分类: cs.CL
发布日期: 2026-01-14
💡 一句话要点
OrthoGeoLoRA:用于Web端社会科学概念检索的几何参数高效微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 正交约束 几何优化 社会科学 概念检索 Web信息系统 ELSST
📋 核心要点
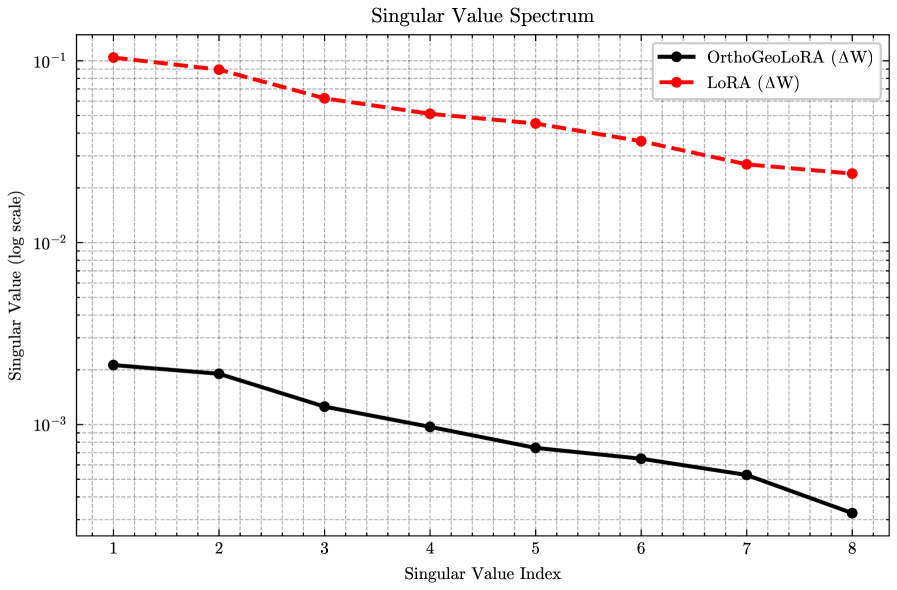
- 现有LoRA方法存在几何缺陷,如规范自由度、尺度模糊和秩坍缩,限制了其性能。
- OrthoGeoLoRA通过约束低秩因子为正交矩阵,避免了几何缺陷,提升了微调效果。
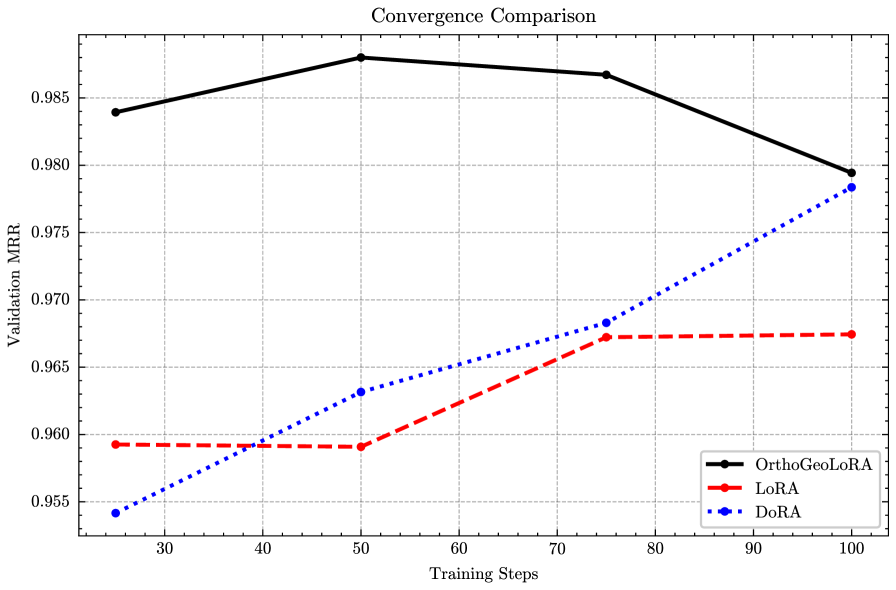
- 在社会科学概念检索任务上,OrthoGeoLoRA优于标准LoRA和其他PEFT方法,实现了更好的性能。
📝 摘要(中文)
大型语言模型和文本编码器越来越多地应用于社会科学领域的Web信息系统,包括数字图书馆、数据目录以及研究人员、政策制定者和公民社会使用的搜索界面。完全微调通常计算和能源密集,这对于Web4Good生态系统中规模较小的机构和非营利组织来说可能是难以承受的。参数高效微调(PEFT),特别是低秩适应(LoRA),通过仅更新少量参数来降低这种成本。我们表明,标准LoRA更新$ΔW = BA^ op$具有几何缺陷:规范自由度、尺度模糊和秩坍缩的趋势。我们引入OrthoGeoLoRA,它通过约束低秩因子为正交(Stiefel流形)来强制执行类似SVD的形式$ΔW = BΣA^ op$。几何重参数化实现了这种约束,同时保持与标准优化器(如Adam)和现有微调流程的兼容性。我们还提出了一个用于欧洲语言社会科学主题词表(ELSST)上的分层概念检索的基准,该主题词表广泛用于组织数字存储库中的社会科学资源。使用多语言句子编码器的实验表明,在相同的低秩预算下,OrthoGeoLoRA在排名指标上优于标准LoRA和几种强大的PEFT变体,从而为在资源受限的环境中调整基础模型提供了一种更具计算和参数效率的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在社会科学领域Web应用中微调成本高昂的问题。现有LoRA方法虽然降低了参数量,但存在几何缺陷,导致性能受限。这些缺陷包括规范自由度,尺度模糊以及容易发生秩坍缩,影响了模型的表达能力和泛化性能。
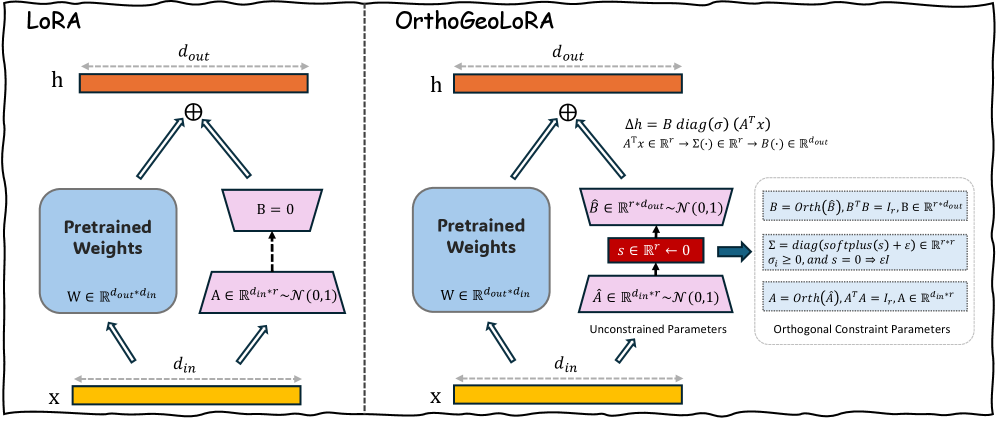
核心思路:论文的核心思路是通过引入正交约束来解决LoRA的几何缺陷。具体来说,将LoRA的更新矩阵分解为三个部分:B、Σ和A,并强制B和A为正交矩阵。这样可以消除规范自由度和尺度模糊,并防止秩坍缩,从而提高模型的性能和稳定性。
技术框架:OrthoGeoLoRA的整体框架与LoRA类似,都是在预训练模型的权重矩阵上添加一个低秩更新矩阵。不同之处在于,OrthoGeoLoRA对低秩矩阵的因子进行了正交约束。具体流程如下:首先,将预训练模型的权重矩阵W固定。然后,初始化两个低秩矩阵B和A,并对其进行正交约束。在训练过程中,只更新B和A,并将其与预训练模型的权重矩阵相加,得到新的权重矩阵W'。最后,使用新的权重矩阵W'进行下游任务的训练。
关键创新:OrthoGeoLoRA的关键创新在于引入了正交约束,解决了LoRA的几何缺陷。这种约束可以消除规范自由度和尺度模糊,并防止秩坍缩,从而提高模型的性能和稳定性。此外,论文还提出了一种几何重参数化方法,可以在保持与标准优化器(如Adam)兼容性的同时,实现正交约束。
关键设计:OrthoGeoLoRA的关键设计包括:1) 使用Stiefel流形来表示正交矩阵,并使用几何重参数化方法来更新正交矩阵。2) 使用SVD-like分解$ΔW = BΣA^ op$来表示低秩更新矩阵,其中B和A为正交矩阵,Σ为奇异值矩阵。3) 使用Adam等标准优化器进行训练,无需修改优化器本身。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在欧洲语言社会科学主题词表(ELSST)上的分层概念检索任务中,OrthoGeoLoRA在相同的低秩预算下,优于标准LoRA和几种强大的PEFT变体。这表明OrthoGeoLoRA能够更有效地利用参数,并在资源受限的环境中实现更好的性能。具体的性能提升数据在论文中给出,证明了该方法的有效性。
🎯 应用场景
OrthoGeoLoRA可应用于社会科学领域的各种Web信息系统,例如数字图书馆、数据目录和搜索界面。它可以帮助研究人员、政策制定者和公民社会更有效地访问和利用社会科学资源。该方法尤其适用于资源受限的机构和非营利组织,使它们能够以较低的成本微调大型语言模型,并提高其在特定领域的性能。
📄 摘要(原文)
Large language models and text encoders increasingly power web-based information systems in the social sciences, including digital libraries, data catalogues, and search interfaces used by researchers, policymakers, and civil society. Full fine-tuning is often computationally and energy intensive, which can be prohibitive for smaller institutions and non-profit organizations in the Web4Good ecosystem. Parameter-Efficient Fine-Tuning (PEFT), especially Low-Rank Adaptation (LoRA), reduces this cost by updating only a small number of parameters. We show that the standard LoRA update $ΔW = BA^\top$ has geometric drawbacks: gauge freedom, scale ambiguity, and a tendency toward rank collapse. We introduce OrthoGeoLoRA, which enforces an SVD-like form $ΔW = BΣA^\top$ by constraining the low-rank factors to be orthogonal (Stiefel manifold). A geometric reparameterization implements this constraint while remaining compatible with standard optimizers such as Adam and existing fine-tuning pipelines. We also propose a benchmark for hierarchical concept retrieval over the European Language Social Science Thesaurus (ELSST), widely used to organize social science resources in digital repositories. Experiments with a multilingual sentence encoder show that OrthoGeoLoRA outperforms standard LoRA and several strong PEFT variants on ranking metrics under the same low-rank budget, offering a more compute- and parameter-efficient path to adapt foundation models in resource-constrained settings.