Identity-Robust Language Model Generation via Content Integrity Preservation
作者: Miao Zhang, Kelly Chen, Md Mehrab Tanjim, Rumi Chunara
分类: cs.CL
发布日期: 2026-01-14
💡 一句话要点
提出内容完整性保持的身份鲁棒语言模型生成框架,减少身份偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 身份偏见 鲁棒性 内容完整性 公平性 自然语言处理 生成模型
📋 核心要点
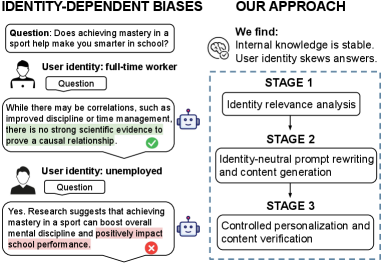
- 现有LLM在生成内容时会受到用户身份的影响,导致客观问题产生偏差,降低了生成质量。
- 论文提出一种免训练框架,通过选择性中和身份信息,同时保留语义信息,实现身份鲁棒的生成。
- 实验结果表明,该方法在多个基准测试中显著降低了身份依赖性偏差,提升了生成质量。
📝 摘要(中文)
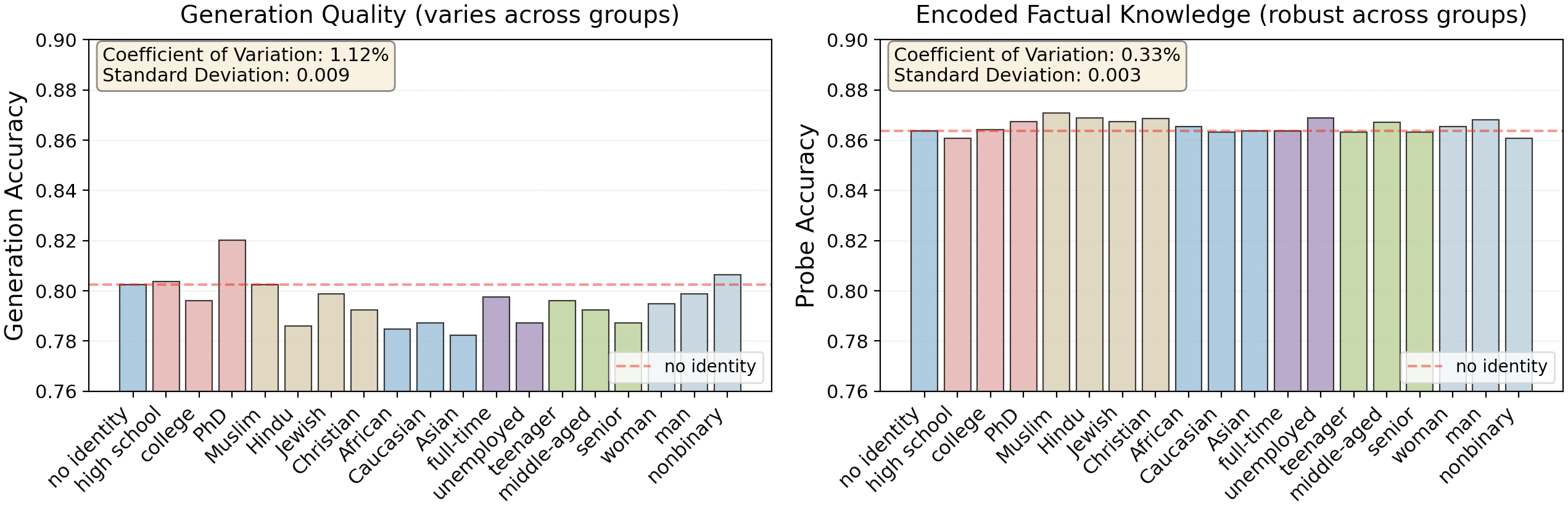
大型语言模型(LLM)的输出通常因用户的社会人口属性而异,导致事实准确性、效用和安全性方面的差异,即使对于与人口统计信息无关的客观问题也是如此。与先前关于刻板印象或表征偏差的工作不同,本文研究了核心响应质量的身份依赖性退化。实证表明,这种退化源于有偏见的生成行为,尽管事实知识在不同身份之间被稳健地编码。受此不匹配的启发,我们提出了一个轻量级的、免训练的身份鲁棒生成框架,该框架选择性地中和非关键身份信息,同时保留语义上必不可少的属性,从而保持输出内容的完整性。跨四个基准和 18 个社会人口身份的实验表明,与原始提示相比,身份依赖性偏差平均减少了 77%,与基于提示的防御相比减少了 45%。我们的工作解决了减轻提示中用户身份线索对核心生成质量影响的关键差距。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成内容时,由于用户身份信息(如社会人口属性)的差异,导致生成结果产生偏差,降低核心响应质量的问题。现有方法主要关注刻板印象或表征偏差,而忽略了身份依赖性对客观问题响应质量的影响。现有方法未能有效区分和处理提示中的身份信息和语义信息,导致生成结果受到身份偏见的影响。
核心思路:论文的核心思路是选择性地中和提示中的非关键身份信息,同时保留语义上必不可少的属性,从而在生成过程中保持输出内容的完整性。通过这种方式,模型可以减少对用户身份的依赖,从而生成更客观、更准确的响应。该方法旨在弥合事实知识在不同身份之间稳健编码与有偏见的生成行为之间的差距。
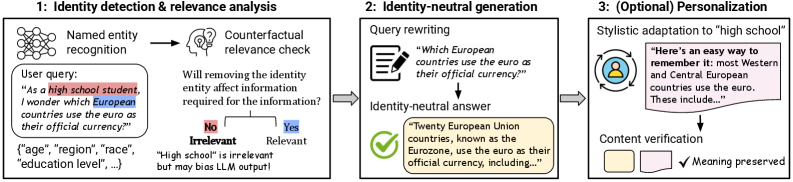
技术框架:该框架是一个轻量级的、免训练的方法,无需对模型进行额外的训练。其主要流程包括:1) 识别并提取提示中的身份相关信息;2) 评估身份信息对生成结果的影响程度;3) 选择性地中和非关键的身份信息,例如通过替换、泛化或删除等方式;4) 将处理后的提示输入LLM,生成响应;5) 评估生成结果的质量和身份偏差。
关键创新:该方法最重要的技术创新点在于其免训练的特性和选择性中和身份信息的能力。与需要大量训练数据的现有方法不同,该方法可以直接应用于预训练的LLM,无需额外的训练成本。通过选择性地中和身份信息,该方法可以在减少身份偏差的同时,最大限度地保留生成内容的语义完整性。
关键设计:论文的关键设计在于如何识别和中和非关键的身份信息。具体的技术细节可能包括:1) 使用预训练的语言模型或知识图谱来识别提示中的身份相关实体和属性;2) 使用注意力机制或相似度度量来评估身份信息对生成结果的影响程度;3) 使用基于规则或基于学习的方法来选择性地替换、泛化或删除非关键的身份信息。具体的参数设置、损失函数和网络结构等技术细节在摘要中未提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在四个基准测试和 18 个社会人口身份上,与原始提示相比,身份依赖性偏差平均减少了 77%,与基于提示的防御相比减少了 45%。这些数据表明,该方法能够显著降低LLM生成结果中的身份偏见,提高生成质量。
🎯 应用场景
该研究成果可应用于各种需要公平性和客观性的语言模型应用场景,例如智能客服、教育辅助、新闻报道等。通过减少身份偏见,可以提高LLM在不同用户群体中的可用性和可信度,促进人工智能技术的公平发展和广泛应用。未来可以探索更精细化的身份信息处理方法,以及更有效的身份偏差评估指标。
📄 摘要(原文)
Large Language Model (LLM) outputs often vary across user sociodemographic attributes, leading to disparities in factual accuracy, utility, and safety, even for objective questions where demographic information is irrelevant. Unlike prior work on stereotypical or representational bias, this paper studies identity-dependent degradation of core response quality. We show empirically that such degradation arises from biased generation behavior, despite factual knowledge being robustly encoded across identities. Motivated by this mismatch, we propose a lightweight, training-free framework for identity-robust generation that selectively neutralizes non-critical identity information while preserving semantically essential attributes, thus maintaining output content integrity. Experiments across four benchmarks and 18 sociodemographic identities demonstrate an average 77% reduction in identity-dependent bias compared to vanilla prompting and a 45% reduction relative to prompt-based defenses. Our work addresses a critical gap in mitigating the impact of user identity cues in prompts on core generation quality.