Contrastive Bi-Encoder Models for Multi-Label Skill Extraction: Enhancing ESCO Ontology Matching with BERT and Attention Mechanisms
作者: Yongming Sun
分类: cs.CL, econ.GN
发布日期: 2026-01-14
💡 一句话要点
提出基于对比学习的双编码器模型,用于增强ESCO本体匹配的多标签技能抽取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 技能抽取 零样本学习 对比学习 双编码器 ESCO本体 招聘广告 自然语言处理
📋 核心要点
- 现有监督技能抽取方法受限于大规模、与分类对齐的标注数据的稀缺性和高成本,尤其是在非英语环境中。
- 利用大型语言模型合成训练数据,并引入分层约束多技能生成,训练对比双编码器对齐招聘广告和技能描述。
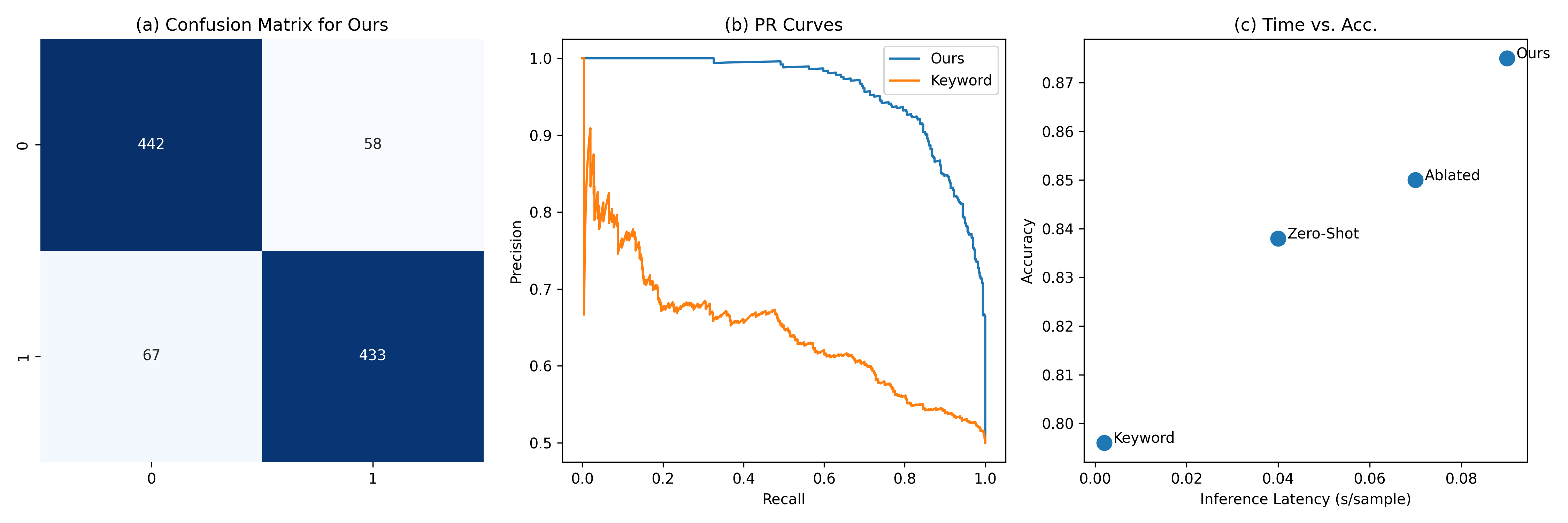
- 实验表明,该模型在中文招聘广告上实现了显著的零样本技能抽取性能,F1@5达到0.72,优于基线模型。
📝 摘要(中文)
本文提出了一种零样本技能抽取框架,旨在解决将非结构化招聘广告映射到标准化技能分类(如ESCO)的问题。该框架利用大型语言模型(LLM)从ESCO定义中合成训练实例,并引入基于ESCO Level-2类别的分层约束多技能生成,以提高多标签上下文中的语义一致性。在此基础上,训练一个对比双编码器,将招聘广告语句与ESCO技能描述对齐到共享嵌入空间。该编码器使用BERT作为骨干,并结合BiLSTM和注意力池化,以更好地建模长且信息密集的技能需求语句。一个基于RoBERTa的上游二元过滤器用于移除非技能语句,以提高端到端精度。实验表明,分层条件生成提高了流畅性和可区分性,并且该模型能够有效迁移到真实的中文招聘广告中,实现了强大的零样本检索性能(F1@5 = 0.72),优于TF-IDF和标准BERT基线。该流程为劳动力经济学和劳动力分析中的自动技能编码提供了一条可扩展、数据高效的途径。
🔬 方法详解
问题定义:论文旨在解决将非结构化的招聘广告文本映射到标准化的技能本体(如ESCO)上的多标签分类问题。现有方法依赖于大量人工标注数据,成本高昂且难以扩展,尤其是在非英语环境下,招聘广告的语言风格与正式的技能描述存在较大差异。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成合成训练数据,避免对真实标注数据的依赖,从而实现零样本技能抽取。通过对比学习,将招聘广告语句和技能描述映射到共享的嵌入空间,使得语义相似的语句在嵌入空间中距离更近。
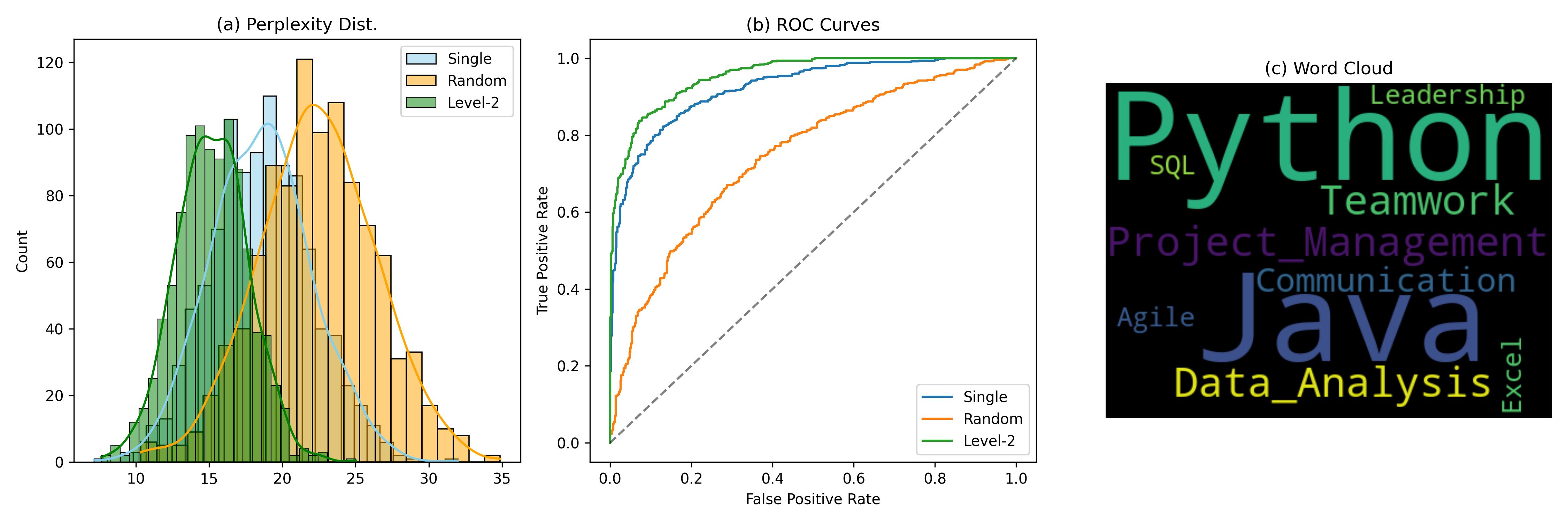
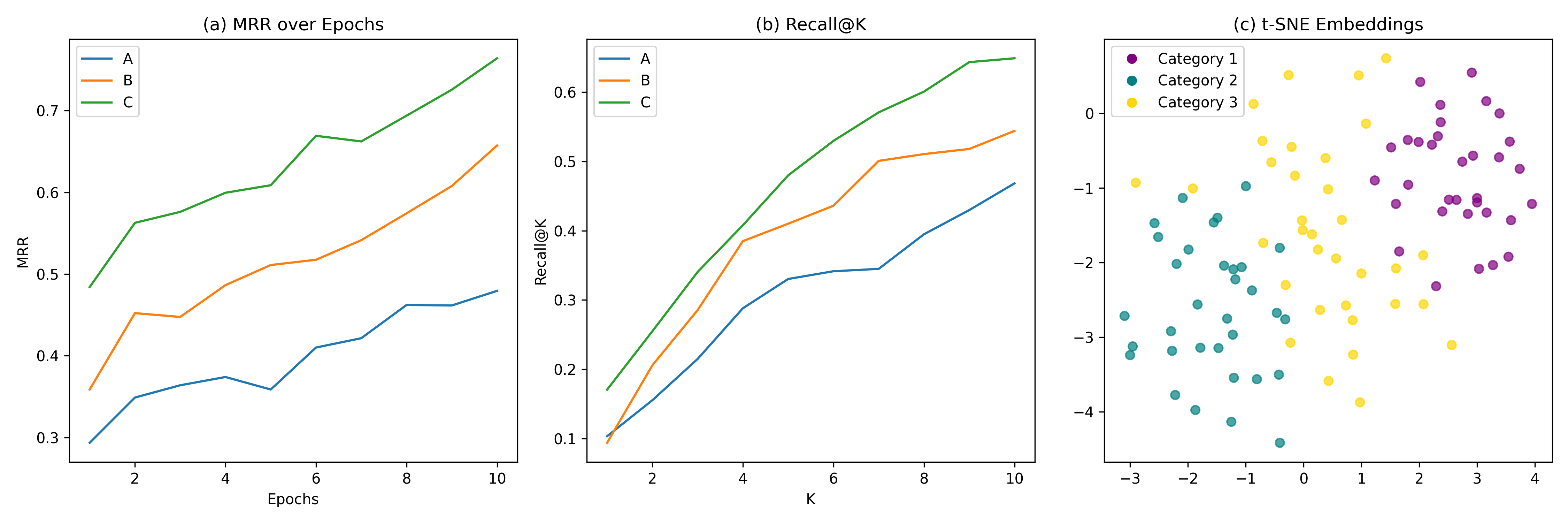
技术框架:整体框架包含三个主要模块:1) 基于LLM的合成数据生成器,根据ESCO技能定义生成训练样本;2) 对比双编码器,包含BERT骨干网络、BiLSTM和注意力池化层,用于编码招聘广告语句和技能描述;3) 基于RoBERTa的二元过滤器,用于过滤掉非技能相关的句子。训练时,通过对比损失函数优化双编码器,使得正样本对(招聘广告语句和对应的技能描述)的嵌入向量距离更近,负样本对距离更远。
关键创新:论文的关键创新在于:1) 提出了一种基于LLM的合成数据生成方法,有效解决了数据稀缺问题;2) 引入了分层约束多技能生成,利用ESCO的层级结构信息,提升了生成数据的语义一致性;3) 结合BiLSTM和注意力机制增强了BERT编码器对长文本的建模能力。
关键设计:在数据生成阶段,利用ESCO Level-2类别信息进行分层约束,保证生成的多标签技能在语义上更相关。对比损失函数采用InfoNCE loss,用于区分正样本对和负样本对。BiLSTM用于捕捉文本序列的上下文信息,注意力池化层用于关注重要的词语。RoBERTa二元过滤器采用标准二分类交叉熵损失进行训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该模型在真实的中文招聘广告数据集上取得了显著的零样本技能抽取性能,F1@5指标达到0.72,优于TF-IDF和标准BERT基线模型。分层约束多技能生成策略有效提升了生成数据的质量和模型的性能。该模型在数据效率和可扩展性方面具有显著优势。
🎯 应用场景
该研究成果可应用于劳动力市场分析、职业技能预测、人才招聘等领域。通过自动提取招聘广告中的技能需求,可以更准确地了解劳动力市场的需求变化,为求职者提供更精准的职业建议,并为企业提供更高效的人才匹配服务。该方法尤其适用于缺乏标注数据的非英语环境。
📄 摘要(原文)
Fine-grained labor market analysis increasingly relies on mapping unstructured job advertisements to standardized skill taxonomies such as ESCO. This mapping is naturally formulated as an Extreme Multi-Label Classification (XMLC) problem, but supervised solutions are constrained by the scarcity and cost of large-scale, taxonomy-aligned annotations--especially in non-English settings where job-ad language diverges substantially from formal skill definitions. We propose a zero-shot skill extraction framework that eliminates the need for manually labeled job-ad training data. The framework uses a Large Language Model (LLM) to synthesize training instances from ESCO definitions, and introduces hierarchically constrained multi-skill generation based on ESCO Level-2 categories to improve semantic coherence in multi-label contexts. On top of the synthetic corpus, we train a contrastive bi-encoder that aligns job-ad sentences with ESCO skill descriptions in a shared embedding space; the encoder augments a BERT backbone with BiLSTM and attention pooling to better model long, information-dense requirement statements. An upstream RoBERTa-based binary filter removes non-skill sentences to improve end-to-end precision. Experiments show that (i) hierarchy-conditioned generation improves both fluency and discriminability relative to unconstrained pairing, and (ii) the resulting multi-label model transfers effectively to real-world Chinese job advertisements, achieving strong zero-shot retrieval performance (F1@5 = 0.72) and outperforming TF--IDF and standard BERT baselines. Overall, the proposed pipeline provides a scalable, data-efficient pathway for automated skill coding in labor economics and workforce analytics.