Mi:dm 2.0 Korea-centric Bilingual Language Models
作者: Donghoon Shin, Sejung Lee, Soonmin Bae, Hwijung Ryu, Changwon Ok, Hoyoun Jung, Hyesung Ji, Jeehyun Lim, Jehoon Lee, Ji-Eun Han, Jisoo Baik, Mihyeon Kim, Riwoo Chung, Seongmin Lee, Wonjae Park, Yoonseok Heo, Youngkyung Seo, Seyoun Won, Boeun Kim, Cheolhun Heo, Eunkyeong Lee, Honghee Lee, Hyeongju Ju, Hyeontae Seo, Jeongyong Shim, Jisoo Lee, Junseok Koh, Junwoo Kim, Minho Lee, Minji Kang, Minju Kim, Sangha Nam, Seongheum Park, Taehyeong Kim, Euijai Ahn, Hong Seok Jeung, Jisu Shin, Jiyeon Kim, Seonyeong Song, Seung Hyun Kong, Sukjin Hong, Taeyang Yun, Yu-Seon Kim, A-Hyun Lee, Chae-Jeong Lee, Hye-Won Yu, Ji-Hyun Ahn, Song-Yeon Kim, Sun-Woo Jung, Eunju Kim, Eunji Ha, Jinwoo Baek, Yun-ji Lee, Wanjin Park, Jeong Yeop Kim, Eun Mi Kim, Hyoung Jun Park, Jung Won Yoon, Min Sung Noh, Myung Gyo Oh, Wongyoung Lee, Yun Jin Park, Young S. Kwon, Hyun Keun Kim, Jieun Lee, YeoJoo Park
分类: cs.CL, cs.AI
发布日期: 2026-01-14
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
Mi:dm 2.0:面向韩国的双语大语言模型,提升文化理解和性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 韩国文化 双语模型 数据清洗 分词器优化
📋 核心要点
- 现有LLM在处理韩语数据时面临数据量不足、质量不高以及文化理解不足的挑战,导致模型在韩国特定场景下表现不佳。
- Mi:dm 2.0通过高质量数据管道、文化对齐的数据混合以及韩语优化的分词器,构建更懂韩国文化和语言的大语言模型。
- Mi:dm 2.0在韩国特定基准测试中取得了领先的零样本性能,并在语言、人文和社会科学任务中表现出色。
📝 摘要(中文)
本文介绍了Mi:dm 2.0,一个专为提升韩国中心人工智能而设计的双语大型语言模型(LLM)。该模型超越了简单的韩语文本处理,集成了韩国社会固有的价值观、推理模式和常识知识,从而能够细致地理解文化背景、情感微妙之处和真实场景,进而生成可靠且符合文化背景的响应。为了解决现有LLM的局限性,这些局限性通常是由韩语数据不足或质量不高以及缺乏文化对齐造成的,Mi:dm 2.0通过一个全面的流程来强调强大的数据质量,该流程包括专有的数据清理、高质量的合成数据生成、使用课程学习的战略数据混合以及定制的韩语优化分词器,以提高效率和覆盖率。为了实现这一愿景,我们提供了两种互补的配置:Mi:dm 2.0 Base(115亿参数),采用深度向上扩展策略构建,用于通用目的;以及Mi:dm 2.0 Mini(23亿参数),针对资源受限的环境和专门任务进行了优化。Mi:dm 2.0在韩国特定基准测试中实现了最先进的性能,在KMMLU上获得了顶级的零样本结果,并在语言、人文和社会科学任务中获得了强大的内部评估结果。Mi:dm 2.0系列在MIT许可下发布,以支持广泛的研究和商业用途。通过提供可访问且高性能的韩国中心LLM,KT旨在加速人工智能在韩国工业、公共服务和教育领域的应用,加强韩国人工智能开发者社区,并为更广泛的K-智能愿景奠定基础。我们的模型可在https://huggingface.co/K-intelligence上找到。如有技术咨询,请联系midm-llm@kt.com。
🔬 方法详解
问题定义:现有的大型语言模型在处理韩语任务时,由于训练数据中韩语数据量不足、质量不高,以及缺乏对韩国文化和价值观的理解,导致模型在韩国特定场景下的表现不佳,无法生成符合韩国文化背景的响应。
核心思路:Mi:dm 2.0的核心思路是通过构建一个以韩国文化为中心的双语大型语言模型,该模型不仅能够处理韩语文本,还能够理解韩国社会的价值观、推理模式和常识知识。通过高质量的数据处理流程和针对韩语优化的分词器,提升模型在韩国特定任务上的性能。
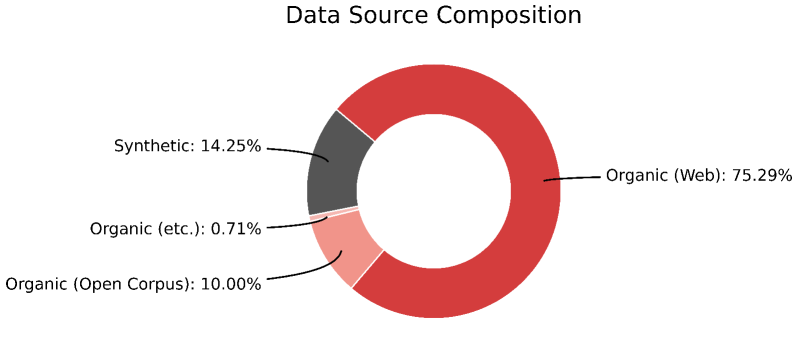
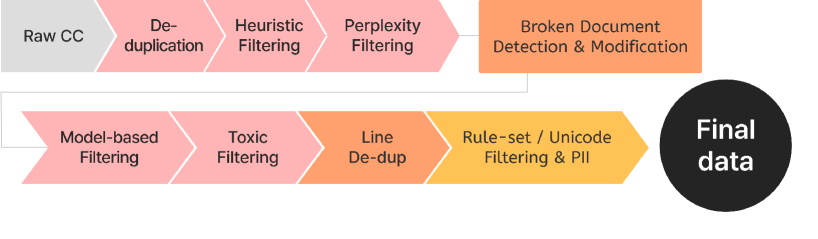
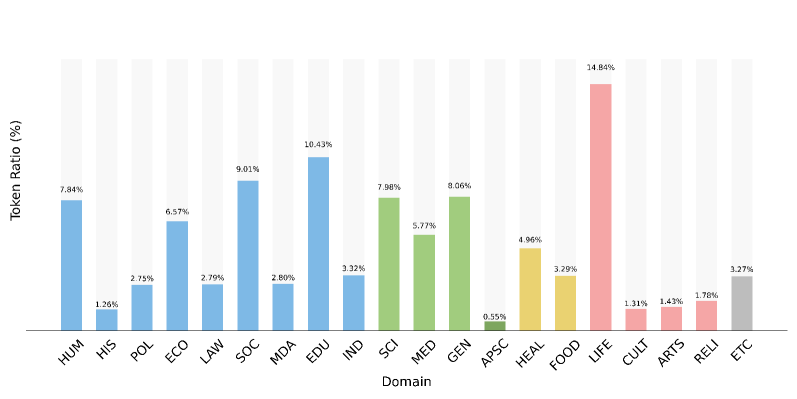
技术框架:Mi:dm 2.0的技术框架主要包括以下几个阶段:1) 数据收集与清洗:收集大量的韩语和英语数据,并进行专有的数据清洗,去除低质量和噪声数据。2) 合成数据生成:生成高质量的合成数据,以扩充训练数据集,并提升模型的泛化能力。3) 数据混合与课程学习:采用战略性的数据混合方法,并结合课程学习,逐步提升模型的学习能力。4) 韩语优化分词器:定制一个针对韩语优化的分词器,以提高效率和覆盖率。5) 模型训练与评估:使用收集到的数据训练模型,并在韩国特定基准测试中进行评估。
关键创新:Mi:dm 2.0的关键创新在于其以韩国文化为中心的设计理念,以及针对韩语数据特点进行优化的数据处理流程和分词器。与现有的通用大型语言模型相比,Mi:dm 2.0更加注重对韩国文化和价值观的理解,从而能够生成更加符合韩国文化背景的响应。
关键设计:Mi:dm 2.0提供了两种配置:Mi:dm 2.0 Base (11.5B参数) 和 Mi:dm 2.0 Mini (2.3B参数)。Mi:dm 2.0 Base采用深度向上扩展策略,适用于通用目的;Mi:dm 2.0 Mini针对资源受限的环境和专门任务进行了优化。模型使用Transformer架构,并针对韩语数据特点进行了参数调整。具体的技术细节,如损失函数、网络结构等,论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
Mi:dm 2.0 在韩国特定基准测试 KMMLU 上取得了顶级的零样本结果,并在语言、人文和社会科学任务中获得了强大的内部评估结果。这些结果表明,Mi:dm 2.0 在理解和生成韩语文本方面具有显著的优势,并且能够更好地理解韩国文化和价值观。
🎯 应用场景
Mi:dm 2.0 可广泛应用于韩国的各个领域,包括但不限于:智能客服、内容创作、教育辅导、法律咨询、医疗诊断等。通过提供更准确、更符合韩国文化背景的AI服务,Mi:dm 2.0 有助于加速人工智能在韩国的普及和应用,并提升相关服务的用户体验。
📄 摘要(原文)
We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.