Modeling LLM Agent Reviewer Dynamics in Elo-Ranked Review System
作者: Hsiang-Wei Huang, Junbin Lu, Kuang-Ming Chen, Jenq-Neng Hwang
分类: cs.CL, cs.AI
发布日期: 2026-01-13
备注: In submission. The first two authors contributed equally
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于Elo评分的LLM审稿人动态模型以提升审稿决策准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Elo评分 大型语言模型 审稿系统 动态模型 决策支持 自适应策略
📋 核心要点
- 现有审稿系统在决策准确性和审稿人适应性方面存在不足,难以有效利用审稿人反馈。
- 论文提出了一种基于Elo评分的动态模型,通过多轮审稿互动提升审稿决策的准确性和效率。
- 实验结果表明,引入Elo评分显著提高了区域主席的决策准确性,并优化了审稿人的审稿策略。
📝 摘要(中文)
本研究探讨了在Elo评分审稿系统中,大型语言模型(LLM)审稿人的动态行为,基于真实的会议论文提交数据。多个具有不同个性的LLM审稿人参与多轮审稿互动,由区域主席进行调节。我们比较了基线设置与引入Elo评分和审稿人记忆的条件。模拟结果展示了几个有趣的发现,包括Elo评分如何提高区域主席的决策准确性,以及审稿人如何利用Elo系统进行自适应审稿策略,而无需增加审稿努力。我们的代码可在https://github.com/hsiangwei0903/EloReview获取。
🔬 方法详解
问题定义:本论文旨在解决现有审稿系统中决策准确性不足和审稿人反馈利用不充分的问题。现有方法未能有效整合审稿人记忆和评分机制,导致审稿过程效率低下。
核心思路:论文的核心思路是引入Elo评分机制,模拟多个LLM审稿人的动态行为,通过多轮审稿互动来提升审稿决策的准确性和审稿人适应性。设计此机制的原因在于Elo评分能够动态反映审稿人的能力变化,从而优化审稿过程。
技术框架:整体架构包括多个LLM审稿人、区域主席和Elo评分系统。审稿人根据Elo评分进行自适应审稿,区域主席根据审稿结果和评分进行最终决策。主要模块包括审稿人行为模拟、Elo评分计算和决策支持系统。
关键创新:最重要的技术创新点在于将Elo评分机制与LLM审稿人动态行为结合,形成了一种新的审稿人互动模型。这一方法与传统审稿系统的静态评分方式有本质区别,能够更好地反映审稿人的真实能力和适应性。
关键设计:在参数设置上,Elo评分的初始值和更新规则是关键设计因素。此外,审稿人记忆的引入和多轮互动的设计也对模型性能有显著影响。损失函数的设计考虑了审稿结果的准确性和审稿人反馈的有效性。
🖼️ 关键图片
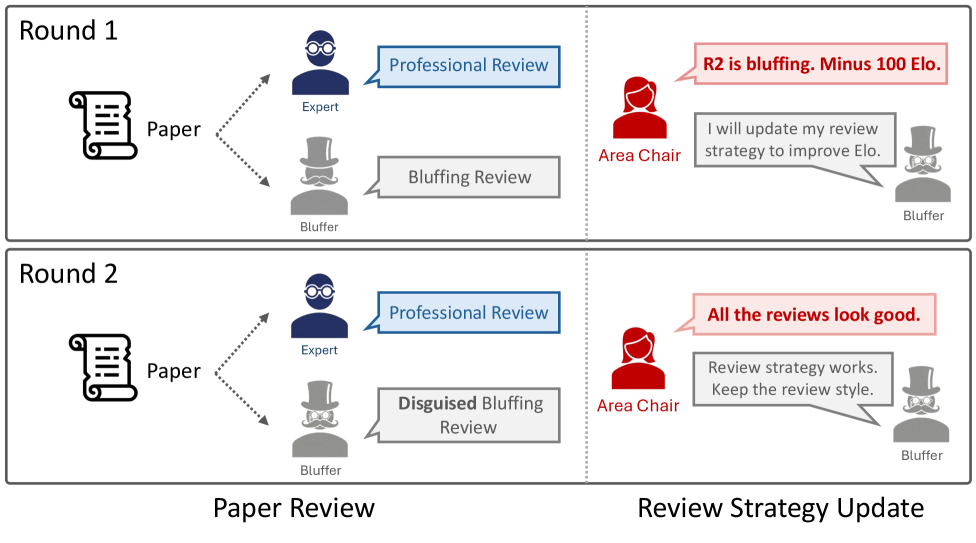

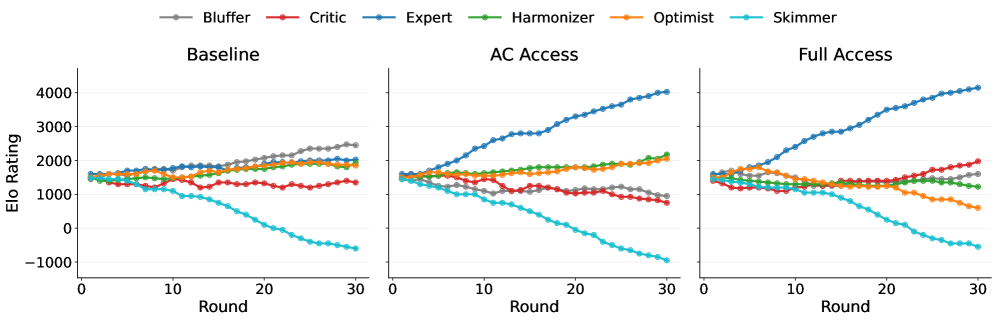
📊 实验亮点
实验结果显示,引入Elo评分机制后,区域主席的决策准确性显著提高,审稿人适应性增强。与基线设置相比,Elo评分系统使得审稿人能够在不增加审稿努力的情况下,优化其审稿策略,提升了整体审稿效率。
🎯 应用场景
该研究的潜在应用领域包括学术会议的论文审稿、期刊审稿流程优化以及其他需要多方反馈的评审系统。通过提升审稿决策的准确性和效率,能够有效提高学术交流的质量,促进研究成果的传播与应用。未来,该模型还可以扩展到其他领域的评估系统,如产品评价和服务反馈等。
📄 摘要(原文)
In this work, we explore the Large Language Model (LLM) agent reviewer dynamics in an Elo-ranked review system using real-world conference paper submissions. Multiple LLM agent reviewers with different personas are engage in multi round review interactions moderated by an Area Chair. We compare a baseline setting with conditions that incorporate Elo ratings and reviewer memory. Our simulation results showcase several interesting findings, including how incorporating Elo improves Area Chair decision accuracy, as well as reviewers' adaptive review strategy that exploits our Elo system without improving review effort. Our code is available at https://github.com/hsiangwei0903/EloReview.