From Rows to Reasoning: A Retrieval-Augmented Multimodal Framework for Spreadsheet Understanding
作者: Anmol Gulati, Sahil Sen, Waqar Sarguroh, Kevin Paul
分类: cs.CL
发布日期: 2026-01-13
💡 一句话要点
提出FRTR框架,通过检索增强多模态方法提升电子表格理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电子表格理解 多模态学习 检索增强生成 大型语言模型 混合检索
📋 核心要点
- 现有电子表格推理方法在处理大型、多模态的企业级电子表格时,面临可扩展性和真实用户交互模拟的挑战。
- FRTR框架通过将电子表格分解为细粒度嵌入,并结合混合检索和多模态信息,实现了更有效的推理。
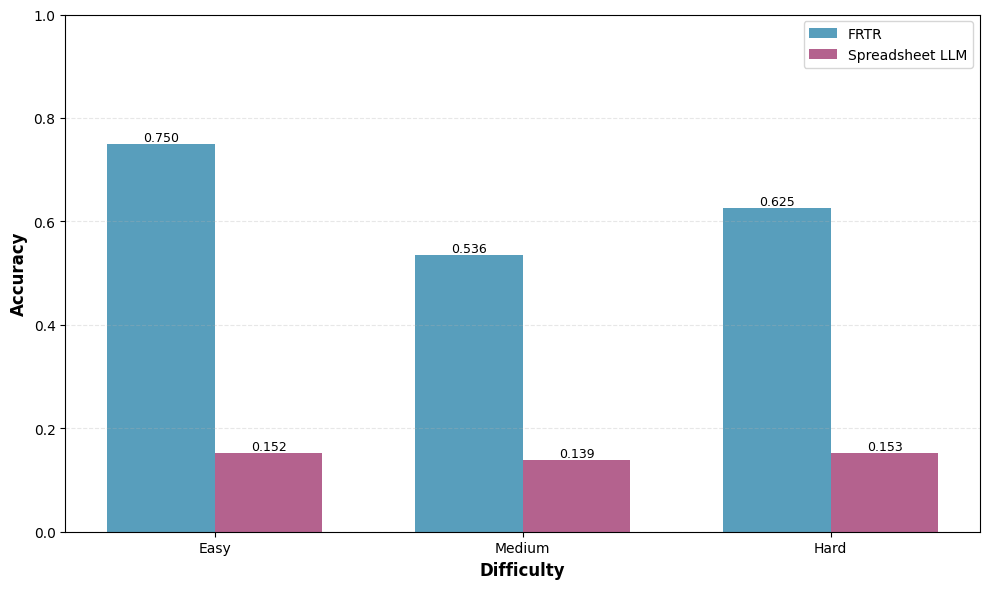
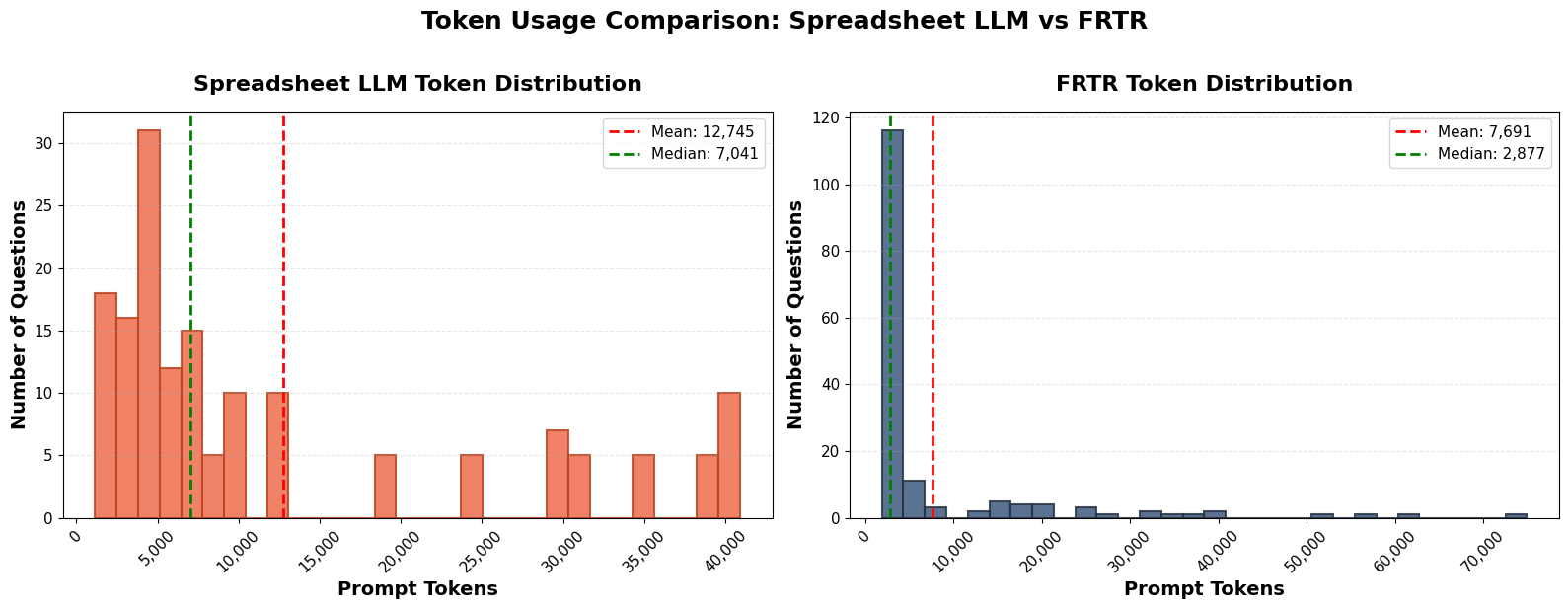
- 实验表明,FRTR在FRTR-Bench和SpreadsheetLLM基准测试中显著优于现有方法,并降低了token使用量。
📝 摘要(中文)
大型语言模型(LLMs)难以处理包含数千行数字、多个链接工作表以及嵌入式视觉内容(如图表和收据)的大型企业电子表格。现有的电子表格推理方法通常依赖于单表压缩或全文编码,限制了可扩展性,并且未能反映真实用户与复杂多模态工作簿的交互方式。本文提出了FRTR-Bench,这是第一个用于多模态电子表格推理的大规模基准,包含30个企业级Excel工作簿,涵盖近四百万个单元格和50多个嵌入图像。为了应对这些挑战,本文提出了一种先进的多模态检索增强生成框架FRTR,该框架将Excel工作簿分解为细粒度的行、列和块嵌入,采用具有倒数秩融合(RRF)的混合词汇-密集检索,并集成多模态嵌入以推理数字和视觉信息。在FRTR-Bench上,使用Claude Sonnet 4.5测试FRTR,实现了74%的答案准确率,与之前仅达到24%的最先进方法相比,有了显著的提高。在SpreadsheetLLM基准测试中,FRTR使用GPT-5实现了87%的准确率,同时比上下文压缩方法减少了大约50%的token使用量。
🔬 方法详解
问题定义:论文旨在解决大型企业级电子表格理解的难题,特别是当电子表格包含大量数据行、多个关联工作表以及嵌入的视觉内容时。现有方法,如单表压缩或全文编码,无法有效处理这种复杂性,导致可扩展性差,并且不能很好地模拟用户与电子表格的交互方式。
核心思路:论文的核心思路是采用检索增强生成(Retrieval-Augmented Generation, RAG)框架,将电子表格分解为更小的、可管理的单元(行、列、块),并利用混合检索方法找到与问题相关的单元,然后结合多模态信息进行推理。这种方法模仿了人类用户在处理大型电子表格时,通常会选择性地查看和分析相关部分的行为。
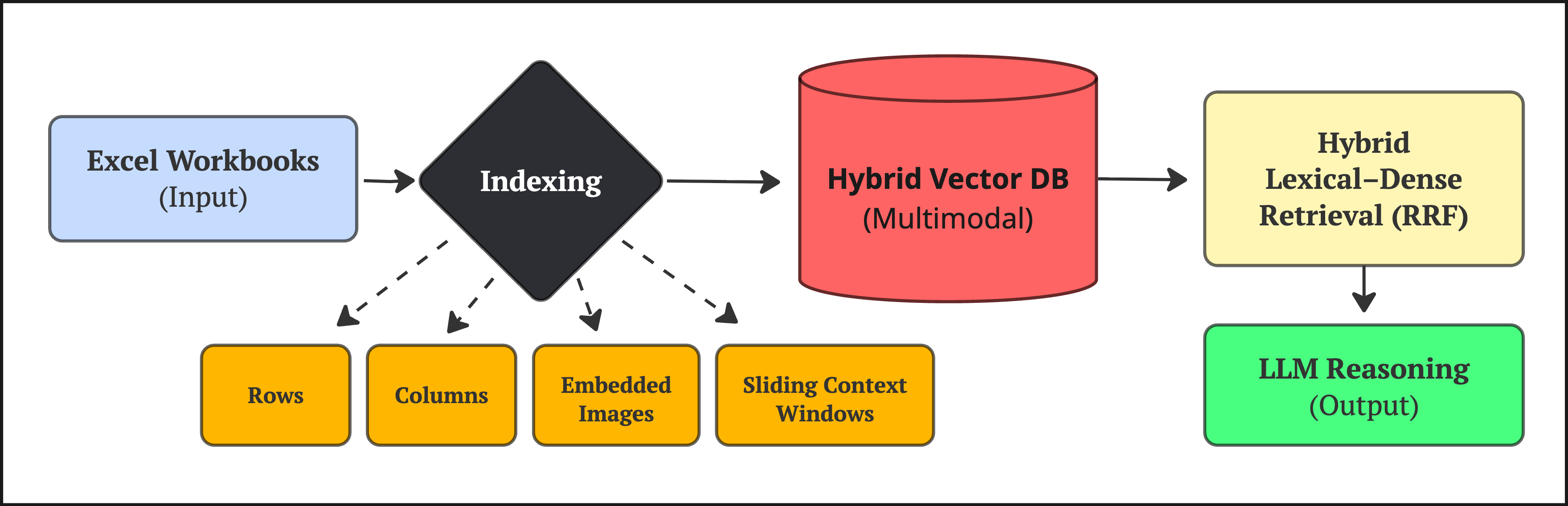
技术框架:FRTR框架包含以下主要模块:1) 嵌入模块:将Excel工作簿分解为行、列和块,并生成相应的嵌入向量。这些嵌入向量既包含文本信息,也包含数值信息和视觉信息(如果存在)。2) 检索模块:使用混合检索方法(词汇检索和密集向量检索)结合倒数秩融合(Reciprocal Rank Fusion, RRF)来检索与问题相关的单元。3) 推理模块:将检索到的单元和问题一起输入到大型语言模型(LLM)中,由LLM进行推理并生成答案。
关键创新:FRTR的关键创新在于其多模态检索增强方法,它能够同时处理电子表格中的数值、文本和视觉信息。此外,FRTR采用混合检索和RRF,能够更准确地找到与问题相关的单元。另一个创新点是FRTR-Bench,这是一个新的大规模多模态电子表格推理基准。
关键设计:在嵌入模块中,论文可能使用了预训练的语言模型(如BERT或其变体)来生成文本嵌入,并使用一些方法(例如简单的数值编码或更复杂的图神经网络)来生成数值和视觉嵌入。在检索模块中,词汇检索可能使用TF-IDF或BM25等方法,而密集向量检索可能使用余弦相似度。RRF用于将两种检索结果进行融合。在推理模块中,选择合适的LLM(如GPT-3/4或Claude)至关重要,并且可能需要进行微调以适应电子表格推理任务。
🖼️ 关键图片
📊 实验亮点
FRTR在FRTR-Bench基准测试中,使用Claude Sonnet 4.5实现了74%的答案准确率,显著优于之前最先进方法的24%。在SpreadsheetLLM基准测试中,FRTR使用GPT-5实现了87%的准确率,同时比上下文压缩方法减少了大约50%的token使用量。这些结果表明,FRTR在电子表格理解方面具有显著的性能优势。
🎯 应用场景
该研究成果可应用于企业数据分析、财务报表解读、自动化报告生成等领域。通过提升电子表格理解能力,可以帮助用户更高效地从大量数据中提取关键信息,辅助决策,并减少人工错误。未来,该技术有望集成到办公软件和数据分析平台中,实现更智能化的数据处理和分析。
📄 摘要(原文)
Large Language Models (LLMs) struggle to reason over large-scale enterprise spreadsheets containing thousands of numeric rows, multiple linked sheets, and embedded visual content such as charts and receipts. Prior state-of-the-art spreadsheet reasoning approaches typically rely on single-sheet compression or full-context encoding, which limits scalability and fails to reflect how real users interact with complex, multimodal workbooks. We introduce FRTR-Bench, the first large-scale benchmark for multimodal spreadsheet reasoning, comprising 30 enterprise-grade Excel workbooks spanning nearly four million cells and more than 50 embedded images. To address these challenges, we present From Rows to Reasoning (FRTR), an advanced, multimodal retrieval-augmented generation framework that decomposes Excel workbooks into granular row, column, and block embeddings, employs hybrid lexical-dense retrieval with Reciprocal Rank Fusion (RRF), and integrates multimodal embeddings to reason over both numerical and visual information. We tested FRTR on six LLMs, achieving 74% answer accuracy on FRTR-Bench with Claude Sonnet 4.5, a substantial improvement over prior state-of-the-art approaches that reached only 24%. On the SpreadsheetLLM benchmark, FRTR achieved 87% accuracy with GPT-5 while reducing token usage by roughly 50% compared to context-compression methods.