Nationality and Region Prediction from Names: A Comparative Study of Neural Models and Large Language Models
作者: Keito Inoshita
分类: cs.CL
发布日期: 2026-01-13
💡 一句话要点
比较神经模型与大语言模型在姓名预测国籍和区域任务上的性能差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 国籍预测 大型语言模型 神经模型 迁移学习 自然语言处理
📋 核心要点
- 现有神经模型在姓名预测国籍任务中,难以泛化到低频国籍,且难以区分同一区域内相似国籍。
- 本研究对比神经模型与大语言模型,利用LLM预训练的世界知识,提升国籍预测的准确性。
- 实验结果表明,LLM在不同粒度级别上均优于神经模型,但低频国籍预测上仍有退化现象。
📝 摘要(中文)
本研究探讨了从姓名预测国籍的问题,该问题在市场营销、人口研究和家谱研究中具有实际应用价值。传统的神经模型通过学习特定任务的训练数据中姓名和国籍之间的统计对应关系,但在泛化到低频国籍以及区分同一区域内相似国籍方面面临挑战。大型语言模型(LLM)则有潜力通过利用预训练期间获得的世界知识来解决这些挑战。本研究全面比较了神经模型和LLM在国籍预测方面的性能,评估了六种神经模型和六种LLM提示策略,涵盖了国籍、地区和大陆三个粒度级别,并进行了基于频率的分层分析和误差分析。结果表明,LLM在所有粒度级别上均优于神经模型,但随着粒度变粗,差距缩小。简单的机器学习方法表现出最高的频率鲁棒性,而预训练模型和LLM在低频国籍上的表现有所下降。误差分析表明,LLM倾向于产生“近失”错误,即在国籍不正确时预测正确的区域,而神经模型则表现出更多的跨区域错误和对高频类别的偏见。这些发现表明,LLM的优势源于世界知识,模型选择应考虑所需粒度,并且评估应考虑准确性之外的错误质量。
🔬 方法详解
问题定义:论文旨在解决从姓名预测国籍和区域的问题。现有神经模型依赖于特定任务的训练数据,学习姓名和国籍之间的统计关系,这导致两个主要问题:一是难以泛化到训练数据中出现频率较低的国籍;二是难以区分地理位置相近、文化背景相似的国籍。这些问题限制了神经模型在实际应用中的效果。
核心思路:论文的核心思路是利用大型语言模型(LLM)在预训练阶段学习到的世界知识来提升国籍预测的准确性和泛化能力。LLM通过海量文本数据的学习,能够捕捉到姓名、文化、地理位置等信息之间的复杂关联,从而更好地进行国籍推断。
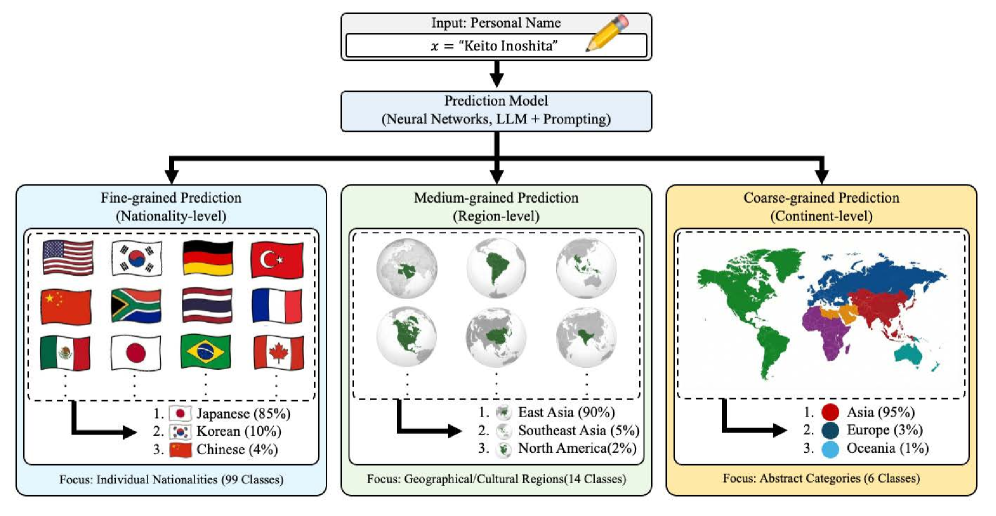
技术框架:研究采用了两种主要的模型类型:神经模型和大型语言模型。神经模型包括多种经典的机器学习和深度学习模型,用于建立姓名与国籍之间的直接映射。大型语言模型则通过不同的prompting策略,将国籍预测任务转化为语言模型擅长的文本生成或分类任务。研究在三个粒度级别(国籍、地区、大陆)上评估了这些模型的性能。
关键创新:本研究的关键创新在于对比了传统神经模型和大型语言模型在国籍预测任务上的性能差异,并深入分析了LLM在利用世界知识方面的优势。通过误差分析,揭示了LLM倾向于产生“近失”错误,而神经模型则更容易出现跨区域错误和对高频类别的偏见。
关键设计:研究中,神经模型采用了多种经典的机器学习和深度学习方法,包括朴素贝叶斯、支持向量机、循环神经网络等。对于大型语言模型,研究设计了多种prompting策略,例如zero-shot prompting、few-shot prompting等,以探索不同prompting方式对模型性能的影响。此外,研究还采用了基于频率的分层分析,以评估模型在不同频率国籍上的表现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,大型语言模型(LLM)在国籍预测任务中,在所有粒度级别上均优于神经模型。误差分析显示,LLM倾向于产生“近失”错误,即在国籍预测错误时,仍能正确预测区域,这表明LLM具备一定的世界知识。然而,LLM在低频国籍上的表现有所下降,表明其对罕见信息的处理能力仍有提升空间。
🎯 应用场景
该研究成果可应用于市场营销领域,帮助企业更准确地识别潜在客户的国籍和地区,从而进行精准营销。在人口研究中,可以辅助分析人口结构和迁移模式。在家谱研究中,可以帮助追溯祖先的国籍和迁徙路线。此外,该技术还可用于身份验证、反欺诈等领域。
📄 摘要(原文)
Predicting nationality from personal names has practical value in marketing, demographic research, and genealogical studies. Conventional neural models learn statistical correspondences between names and nationalities from task-specific training data, posing challenges in generalizing to low-frequency nationalities and distinguishing similar nationalities within the same region. Large language models (LLMs) have the potential to address these challenges by leveraging world knowledge acquired during pre-training. In this study, we comprehensively compare neural models and LLMs on nationality prediction, evaluating six neural models and six LLM prompting strategies across three granularity levels (nationality, region, and continent), with frequency-based stratified analysis and error analysis. Results show that LLMs outperform neural models at all granularity levels, with the gap narrowing as granularity becomes coarser. Simple machine learning methods exhibit the highest frequency robustness, while pre-trained models and LLMs show degradation for low-frequency nationalities. Error analysis reveals that LLMs tend to make ``near-miss'' errors, predicting the correct region even when nationality is incorrect, whereas neural models exhibit more cross-regional errors and bias toward high-frequency classes. These findings indicate that LLM superiority stems from world knowledge, model selection should consider required granularity, and evaluation should account for error quality beyond accuracy.