QuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models
作者: Zhaolu Kang, Junhao Gong, Wenqing Hu, Shuo Yin, Kehan Jiang, Zhicheng Fang, Yingjie He, Chunlei Meng, Rong Fu, Dongyang Chen, Leqi Zheng, Eric Hanchen Jiang, Yunfei Feng, Yitong Leng, Junfan Zhu, Xiaoyou Chen, Xi Yang, Richeng Xuan
分类: cs.CL
发布日期: 2026-01-13
💡 一句话要点
QuantEval:用于评估大语言模型在金融量化任务中能力的基准测试
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融量化 大语言模型 基准测试 量化策略 回测框架
📋 核心要点
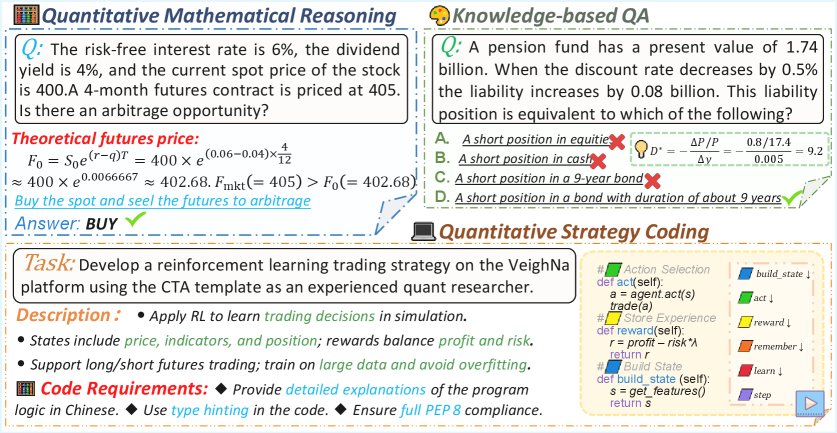
- 现有金融量化任务的LLM评估方法分散,主要集中于知识问答,缺乏对量化策略编码能力的有效评估。
- QuantEval构建了一个综合基准,包含知识问答、数学推理和策略编码三个维度,并引入CTA风格的回测框架。
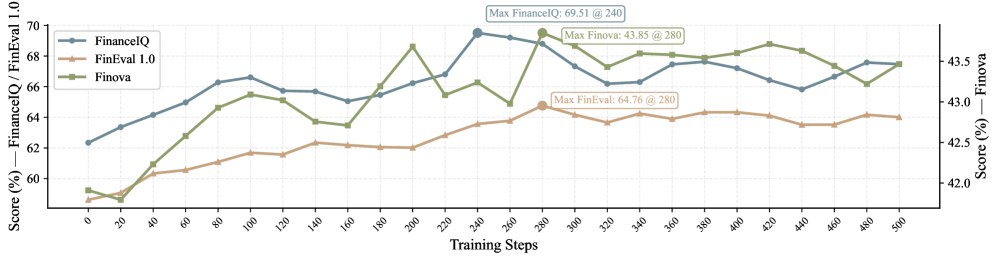
- 实验表明,现有LLM在推理和策略编码方面与人类专家存在差距,通过领域对齐的微调和强化学习可以显著提升性能。
📝 摘要(中文)
大型语言模型(LLM)在许多领域都表现出强大的能力,但它们在金融量化任务中的评估仍然分散,并且主要局限于以知识为中心的问题解答。我们推出了QuantEval,这是一个基准测试,用于评估LLM在量化金融的三个基本维度上的能力:基于知识的问答、定量数学推理和定量策略编码。与之前的金融基准不同,QuantEval集成了一个CTA风格的回测框架,该框架执行模型生成的策略,并使用金融绩效指标对其进行评估,从而能够更真实地评估量化编码能力。我们评估了一些最先进的开源和专有LLM,并观察到与人类专家相比存在显著差距,尤其是在推理和策略编码方面。最后,我们对领域对齐的数据进行了大规模的监督微调和强化学习实验,证明了一致的改进。我们希望QuantEval将促进LLM量化金融能力的研究,并加速其在实际交易工作流程中的实际应用。我们还发布了完整的确定性回测配置(资产范围、成本模型和指标定义),以确保严格的可重复性。
🔬 方法详解
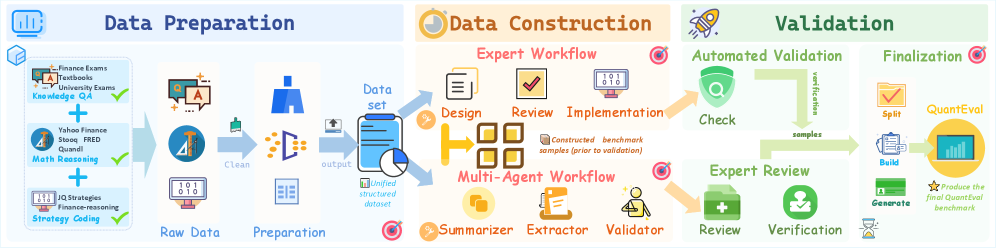
问题定义:现有的大语言模型在金融量化领域的评估主要集中在知识问答方面,缺乏对模型进行量化策略编码能力的全面评估。现有的金融基准测试无法真实地模拟实际交易环境,难以准确评估模型在实际应用中的表现。因此,需要一个更全面、更贴近实际的回测框架来评估LLM在金融量化任务中的能力。
核心思路:QuantEval的核心思路是构建一个包含知识问答、定量数学推理和定量策略编码三个维度的综合性基准测试,并引入CTA风格的回测框架,以更真实地评估LLM在金融量化任务中的能力。通过回测框架,可以执行模型生成的策略,并使用金融绩效指标对其进行评估,从而更准确地反映模型在实际交易环境中的表现。
技术框架:QuantEval的整体框架包含三个主要模块:知识问答模块、定量数学推理模块和定量策略编码模块。定量策略编码模块与CTA风格的回测框架集成,该框架包括资产范围定义、成本模型和指标定义。模型生成的策略在回测框架中执行,并根据预定义的金融绩效指标进行评估。
关键创新:QuantEval的关键创新在于集成了CTA风格的回测框架,这使得能够更真实地评估LLM在金融量化任务中的策略编码能力。与以往的金融基准测试相比,QuantEval的回测框架能够模拟实际交易环境,并使用金融绩效指标对模型生成的策略进行评估,从而更准确地反映模型在实际应用中的表现。
关键设计:QuantEval的回测框架包含以下关键设计:1) 资产范围定义:定义了回测中使用的资产集合;2) 成本模型:模拟交易成本,如交易手续费和滑点;3) 指标定义:定义了用于评估策略性能的金融指标,如收益率、夏普比率和最大回撤。此外,论文还进行了大规模的监督微调和强化学习实验,以提升LLM在金融量化任务中的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的开源和专有LLM在金融量化任务中与人类专家存在显著差距,尤其是在推理和策略编码方面。通过在领域对齐的数据上进行大规模的监督微调和强化学习实验,可以显著提升LLM在金融量化任务中的性能。具体提升幅度未知,原文未给出具体数值。
🎯 应用场景
QuantEval的研究成果可应用于金融量化交易策略的自动生成与评估,辅助量化研究员快速验证交易想法,降低策略开发成本。该基准测试也能促进LLM在金融领域的应用,例如智能投顾、风险管理等,提升金融服务的效率和智能化水平。未来,该研究或将推动AI在金融领域的更广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) have shown strong capabilities across many domains, yet their evaluation in financial quantitative tasks remains fragmented and mostly limited to knowledge-centric question answering. We introduce QuantEval, a benchmark that evaluates LLMs across three essential dimensions of quantitative finance: knowledge-based QA, quantitative mathematical reasoning, and quantitative strategy coding. Unlike prior financial benchmarks, QuantEval integrates a CTA-style backtesting framework that executes model-generated strategies and evaluates them using financial performance metrics, enabling a more realistic assessment of quantitative coding ability. We evaluate some state-of-the-art open-source and proprietary LLMs and observe substantial gaps to human experts, particularly in reasoning and strategy coding. Finally, we conduct large-scale supervised fine-tuning and reinforcement learning experiments on domain-aligned data, demonstrating consistent improvements. We hope QuantEval will facilitate research on LLMs' quantitative finance capabilities and accelerate their practical adoption in real-world trading workflows. We additionally release the full deterministic backtesting configuration (asset universe, cost model, and metric definitions) to ensure strict reproducibility.