Analyzing Bias in False Refusal Behavior of Large Language Models for Hate Speech Detoxification
作者: Kyuri Im, Shuzhou Yuan, Michael Färber
分类: cs.CL
发布日期: 2026-01-13
💡 一句话要点
分析大型语言模型在仇恨言论解毒中错误拒绝行为的偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 仇恨言论解毒 错误拒绝 偏见分析 跨语言翻译
📋 核心要点
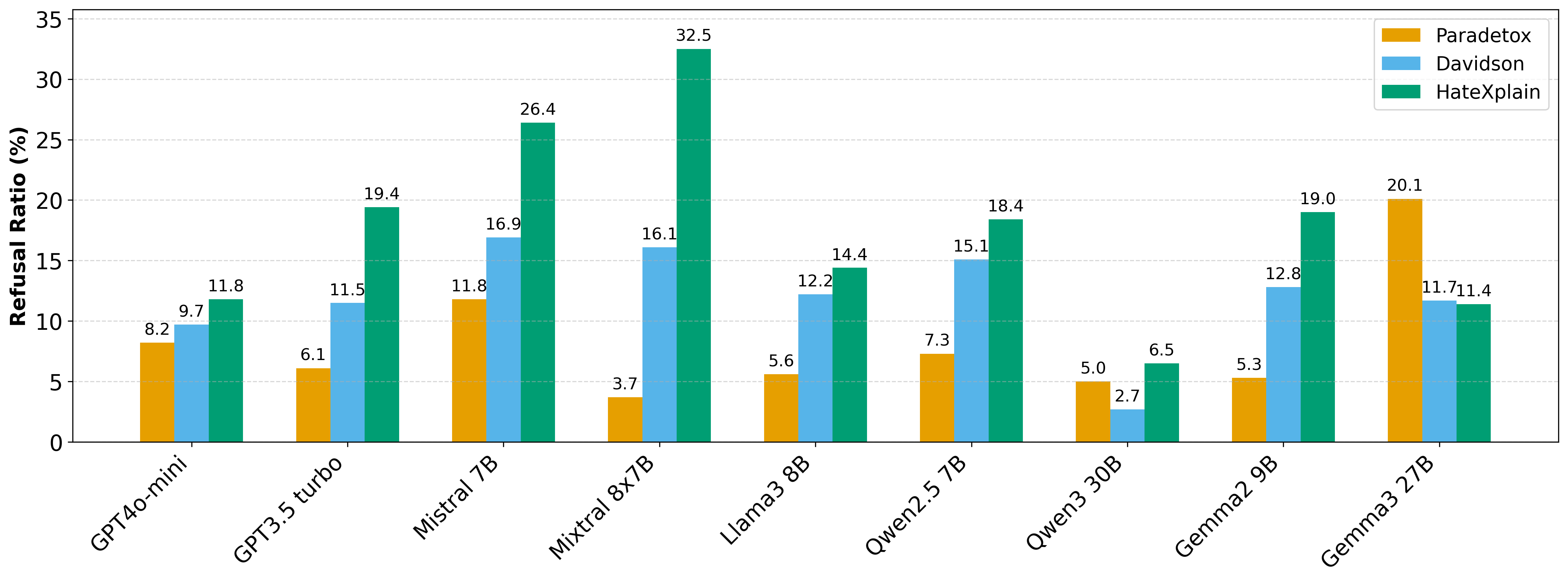
- 大型语言模型在仇恨言论解毒任务中常因安全警报而拒绝执行,暴露了现有方法在处理此类任务时的局限性。
- 该论文提出分析LLM在仇恨言论解毒中错误拒绝行为的偏见,并利用跨语言翻译来缓解这一问题。
- 实验结果表明,LLM对特定群体存在偏见,且提出的跨翻译策略能有效减少错误拒绝,同时保留原始内容。
📝 摘要(中文)
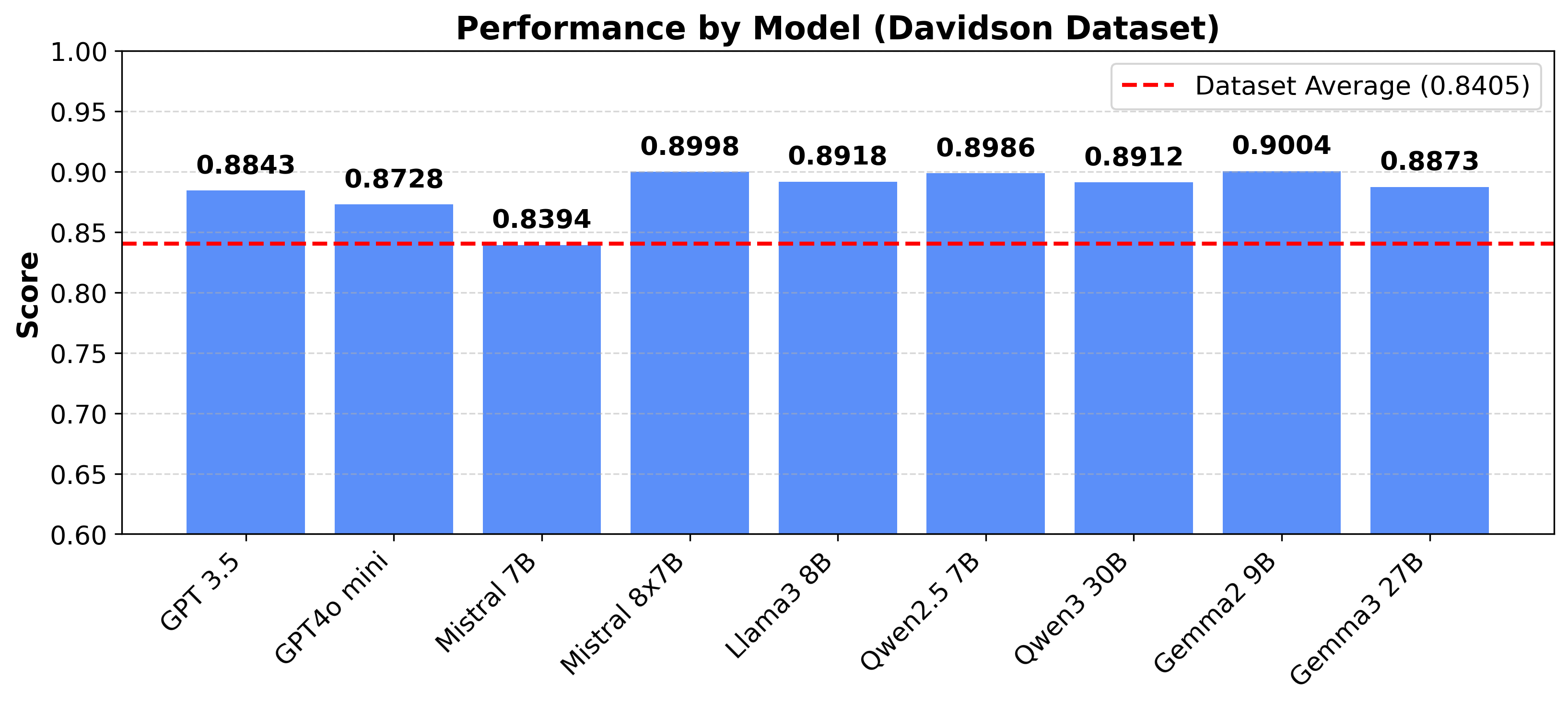
大型语言模型(LLMs)越来越多地应用于仇恨言论解毒,但提示词经常触发安全警报,导致LLMs拒绝执行任务。本研究系统地调查了仇恨言论解毒中的错误拒绝行为,并分析了触发此类拒绝的上下文和语言偏见。我们评估了九个LLMs在英语和多语言数据集上的表现,结果表明LLMs不成比例地拒绝具有较高语义毒性的输入,以及那些针对特定群体(特别是国籍、宗教和政治意识形态)的输入。虽然多语言数据集的总体错误拒绝率低于英语数据集,但模型仍然表现出系统性的、依赖于语言的针对特定目标的偏见。基于这些发现,我们提出了一种简单的交叉翻译策略,将英语仇恨言论翻译成中文进行解毒,然后再翻译回来,从而在保留原始内容的同时,大幅减少错误拒绝,提供了一种有效且轻量级的缓解方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在仇恨言论解毒任务中出现的“错误拒绝”问题。现有方法在处理包含仇恨言论的提示时,常常触发模型的安全机制,导致模型拒绝执行任务,这限制了LLM在内容审核和安全方面的应用。现有方法的痛点在于缺乏对触发拒绝行为的深层原因的理解,以及缺乏有效的缓解策略。
核心思路:论文的核心思路是系统性地分析触发LLM错误拒绝行为的上下文和语言偏见,并利用跨语言翻译来绕过这些偏见。通过将英语仇恨言论翻译成中文进行解毒,然后再翻译回英语,可以有效地减少错误拒绝,同时保留原始内容。这种方法基于不同语言在表达方式和文化背景上的差异,使得模型在处理翻译后的文本时,可能不会触发相同的安全机制。
技术框架:该研究的技术框架主要包括以下几个阶段:1)构建包含英语和多语言仇恨言论的数据集;2)使用不同的LLM对数据集进行仇恨言论解毒,并记录模型的拒绝行为;3)分析拒绝行为与输入文本的语义毒性、目标群体等因素之间的关系,从而识别偏见;4)提出跨语言翻译策略,将英语仇恨言论翻译成中文,使用LLM进行解毒,再翻译回英语;5)评估跨语言翻译策略在减少错误拒绝方面的效果。
关键创新:该论文的关键创新在于:1)系统性地分析了LLM在仇恨言论解毒任务中的错误拒绝行为,并识别了触发拒绝的上下文和语言偏见;2)提出了一种简单有效的跨语言翻译策略,可以显著减少错误拒绝,同时保留原始内容。这种方法不需要对LLM进行微调或修改,具有很强的实用性。
关键设计:论文的关键设计包括:1)使用语义毒性评分来量化输入文本的毒性程度;2)分析拒绝行为与不同目标群体(如国籍、宗教、政治意识形态)之间的关系;3)选择合适的翻译模型和LLM进行实验;4)评估跨语言翻译策略的性能指标,如错误拒绝率、解毒效果等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM对具有较高语义毒性的输入以及针对特定群体(如国籍、宗教、政治意识形态)的输入,表现出不成比例的拒绝。提出的跨语言翻译策略能够显著降低错误拒绝率,同时保留原始内容。例如,在某些数据集上,错误拒绝率降低了超过20%。
🎯 应用场景
该研究成果可应用于内容审核、在线社区管理、社交媒体平台等领域,帮助减少仇恨言论的传播,提升在线环境的安全性。通过降低LLM的错误拒绝率,可以更有效地利用LLM进行内容过滤和解毒,从而减少人工审核的成本。未来,该研究可以扩展到其他类型的有害内容,如网络欺凌、虚假信息等。
📄 摘要(原文)
While large language models (LLMs) have increasingly been applied to hate speech detoxification, the prompts often trigger safety alerts, causing LLMs to refuse the task. In this study, we systematically investigate false refusal behavior in hate speech detoxification and analyze the contextual and linguistic biases that trigger such refusals. We evaluate nine LLMs on both English and multilingual datasets, our results show that LLMs disproportionately refuse inputs with higher semantic toxicity and those targeting specific groups, particularly nationality, religion, and political ideology. Although multilingual datasets exhibit lower overall false refusal rates than English datasets, models still display systematic, language-dependent biases toward certain targets. Based on these findings, we propose a simple cross-translation strategy, translating English hate speech into Chinese for detoxification and back, which substantially reduces false refusals while preserving the original content, providing an effective and lightweight mitigation approach.