How Order-Sensitive Are LLMs? OrderProbe for Deterministic Structural Reconstruction
作者: Yingjie He, Zhaolu Kang, Kehan Jiang, Qianyuan Zhang, Jiachen Qian, Chunlei Meng, Yujie Feng, Yuan Wang, Jiabao Dou, Aming Wu, Leqi Zheng, Pengxiang Zhao, Jiaxin Liu, Zeyu Zhang, Lei Wang, Guansu Wang, Qishi Zhan, Xiaomin He, Meisheng Zhang, Jianyuan Ni
分类: cs.CL
发布日期: 2026-01-13
💡 一句话要点
提出OrderProbe基准,用于评估LLM在中文、日文、韩文四字表达式上的结构重构能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 结构重构 四字表达式 OrderProbe 基准测试 语义理解 鲁棒性 中文处理
📋 核心要点
- 现有方法难以准确评估LLM从乱序输入中恢复结构的能力,因为句子级别存在多种有效词序。
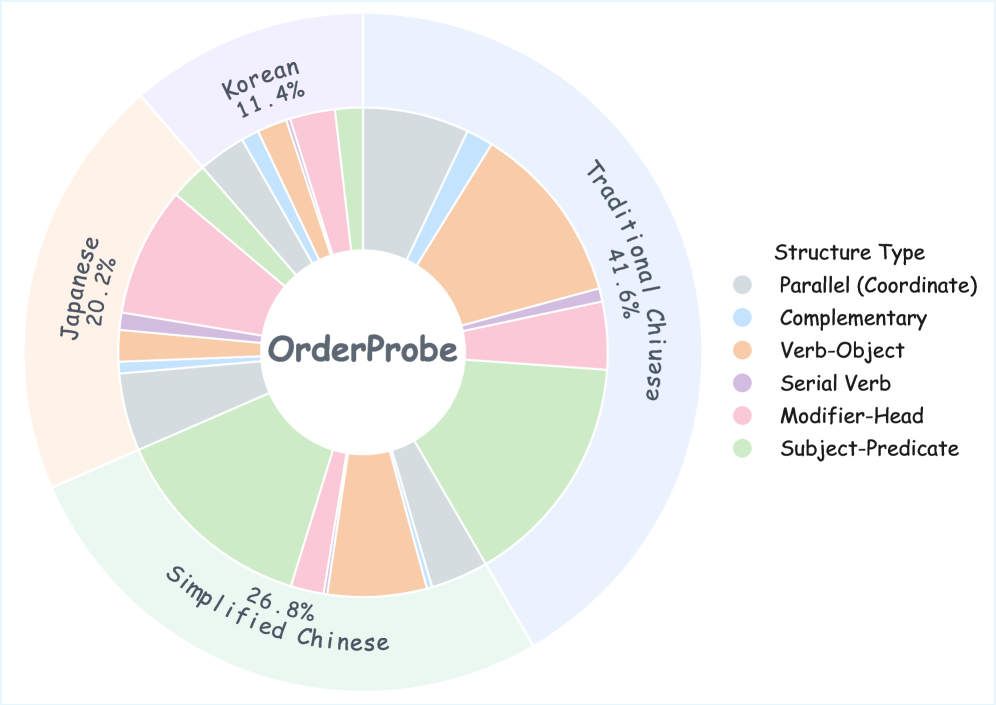
- OrderProbe基准利用中文、日文、韩文的四字表达式,这些表达式具有唯一的规范顺序,从而实现确定性的评估。
- 实验表明,即使是最先进的LLM在结构重构方面仍然面临挑战,且语义能力与结构鲁棒性之间存在脱节。
📝 摘要(中文)
大型语言模型(LLMs)在语义理解方面表现出色,但它们从乱序输入中重构内部结构的能力仍未得到充分探索。由于通常存在多个有效的词序,句子级别的恢复对于自动评估来说是不适定的。我们引入OrderProbe,这是一个确定性的基准,使用中文、日文和韩文中固定的四字表达式进行结构重构,这些表达式具有唯一的规范顺序,因此支持精确匹配评分。我们进一步提出了一个诊断框架,该框架评估模型超出恢复准确率,包括语义保真度、逻辑有效性、一致性、鲁棒性敏感性和信息密度。对十二个广泛使用的LLM的实验表明,即使对于前沿系统,结构重构仍然很困难:零样本恢复通常低于35%。我们还观察到语义回忆和结构规划之间存在一致的解离,这表明结构鲁棒性不是语义能力的自动副产品。
🔬 方法详解
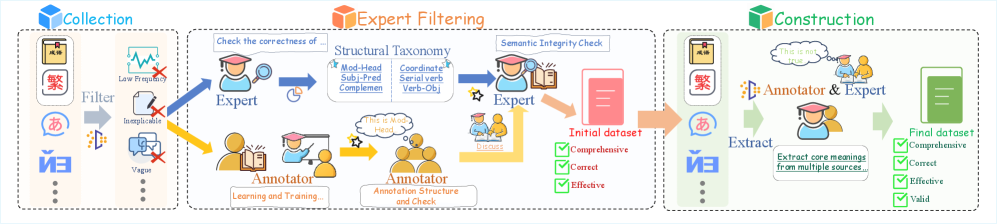
问题定义:论文旨在解决如何有效评估大型语言模型(LLMs)从乱序输入中恢复原始结构的能力。现有方法,特别是句子级别的恢复,由于存在多种可能的有效词序,导致自动评估变得困难且不准确。因此,需要一个确定性的、可精确评估的基准来衡量LLM的结构重构能力。
核心思路:论文的核心思路是利用中文、日文和韩文中广泛存在的四字表达式(成语、熟语等),这些表达式通常具有唯一且明确的规范顺序。通过将这些四字表达式打乱顺序输入LLM,然后评估LLM恢复原始顺序的准确性,从而实现对LLM结构重构能力的量化评估。这种方法避免了句子级别评估中多解性的问题,提供了一个确定性的评估标准。
技术框架:OrderProbe基准测试框架主要包含以下几个部分:1)数据集构建:收集并整理中文、日文和韩文的四字表达式,确保每个表达式都有明确的规范顺序。2)输入生成:将四字表达式随机打乱顺序,生成乱序的输入序列。3)模型预测:将乱序的输入序列输入到待评估的LLM中,让模型预测原始的规范顺序。4)评估指标:使用精确匹配(exact-match)作为主要评估指标,即只有当模型完全恢复原始顺序时才算正确。此外,还设计了一系列诊断指标,包括语义保真度、逻辑有效性、一致性、鲁棒性敏感性和信息密度,以更全面地评估模型的结构重构能力。
关键创新:该论文的关键创新在于提出了OrderProbe,这是一个确定性的结构重构基准,它利用四字表达式的唯一规范顺序,克服了传统句子级别评估的多解性问题。此外,论文还提出了一个全面的诊断框架,不仅评估模型的恢复准确率,还关注其语义保真度、逻辑有效性等多个维度,从而更深入地了解模型的结构重构能力。
关键设计:OrderProbe的关键设计包括:1)四字表达式的选择:选择具有明确规范顺序的四字表达式,避免歧义。2)乱序策略:采用随机打乱顺序的方式生成输入,保证评估的公平性。3)评估指标体系:除了精确匹配外,还设计了一系列诊断指标,以更全面地评估模型的结构重构能力。4)多语言支持:支持中文、日文和韩文,可以跨语言评估模型的结构重构能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的LLM在OrderProbe基准上的零样本恢复准确率通常低于35%,这表明结构重构仍然是一个具有挑战性的问题。此外,研究还发现语义回忆和结构规划之间存在一致的解离,这意味着仅仅具备强大的语义理解能力并不足以保证良好的结构重构能力。
🎯 应用场景
该研究成果可应用于提升LLM在信息抽取、机器翻译、文本摘要等任务中的性能。通过提高LLM对输入结构的处理能力,可以减少信息损失和语义偏差,从而提高下游任务的准确性和可靠性。此外,OrderProbe基准可以作为LLM结构理解能力的评估工具,指导模型设计和优化。
📄 摘要(原文)
Large language models (LLMs) excel at semantic understanding, yet their ability to reconstruct internal structure from scrambled inputs remains underexplored. Sentence-level restoration is ill-posed for automated evaluation because multiple valid word orders often exist. We introduce OrderProbe, a deterministic benchmark for structural reconstruction using fixed four-character expressions in Chinese, Japanese, and Korean, which have a unique canonical order and thus support exact-match scoring. We further propose a diagnostic framework that evaluates models beyond recovery accuracy, including semantic fidelity, logical validity, consistency, robustness sensitivity, and information density. Experiments on twelve widely used LLMs show that structural reconstruction remains difficult even for frontier systems: zero-shot recovery frequently falls below 35%. We also observe a consistent dissociation between semantic recall and structural planning, suggesting that structural robustness is not an automatic byproduct of semantic competence.