It's All About the Confidence: An Unsupervised Approach for Multilingual Historical Entity Linking using Large Language Models
作者: Cristian Santini, Marieke Van Erp, Mehwish Alam
分类: cs.CL
发布日期: 2026-01-13
💡 一句话要点
提出MHEL-LLaMo,一种基于置信度的无监督多语言历史实体链接方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实体链接 历史文本 多语言 无监督学习 大语言模型 置信度评估 低资源学习
📋 核心要点
- 历史文本实体链接面临语言变异、噪声和语义演变等挑战,现有方法依赖大量数据或领域规则,缺乏可扩展性。
- MHEL-LLaMo利用SLM的置信度区分难易样本,仅对困难样本使用LLM,降低计算成本并避免LLM在简单情况下的幻觉。
- 在六种语言的四个基准测试中,MHEL-LLaMo无需微调即可超越现有技术,为低资源历史实体链接提供可扩展方案。
📝 摘要(中文)
本文提出MHEL-LLaMo(基于大语言模型的多语言历史实体链接),一种结合小型语言模型(SLM)和大语言模型(LLM)的无监督集成方法。针对历史文本中由于语言变异、噪声输入和语义惯例演变而导致的实体链接(EL)难题,MHEL-LLaMo利用多语言双编码器(BELA)进行候选检索,并使用指令调优的LLM通过提示链进行NIL预测和候选选择。该系统利用SLM的置信度分数来区分简单和困难样本,仅对困难情况应用LLM。这种策略降低了计算成本,同时防止了在简单情况下的幻觉。在六种欧洲语言(英语、芬兰语、法语、德语、意大利语和瑞典语)的四个既定基准上,对MHEL-LLaMo进行了评估,结果表明,MHEL-LLaMo优于最先进的模型,且无需微调,为低资源历史EL提供了一种可扩展的解决方案。MHEL-LLaMo的实现已在Github上提供。
🔬 方法详解
问题定义:论文旨在解决历史文本中的多语言实体链接问题。历史文本的特殊性在于其语言变异性大、噪声多,且语义随着时间演变,这使得传统的实体链接方法难以有效应用。现有方法通常需要大量的标注数据进行训练,或者依赖于特定领域的规则,这限制了它们在不同历史时期和语言之间的可扩展性。
核心思路:论文的核心思路是利用小型语言模型(SLM)的效率和大语言模型(LLM)的强大推理能力,并结合置信度评估来优化计算资源的使用。通过SLM快速处理简单样本,仅将困难样本交给LLM处理,从而在保证性能的同时降低计算成本,并减少LLM产生幻觉的风险。
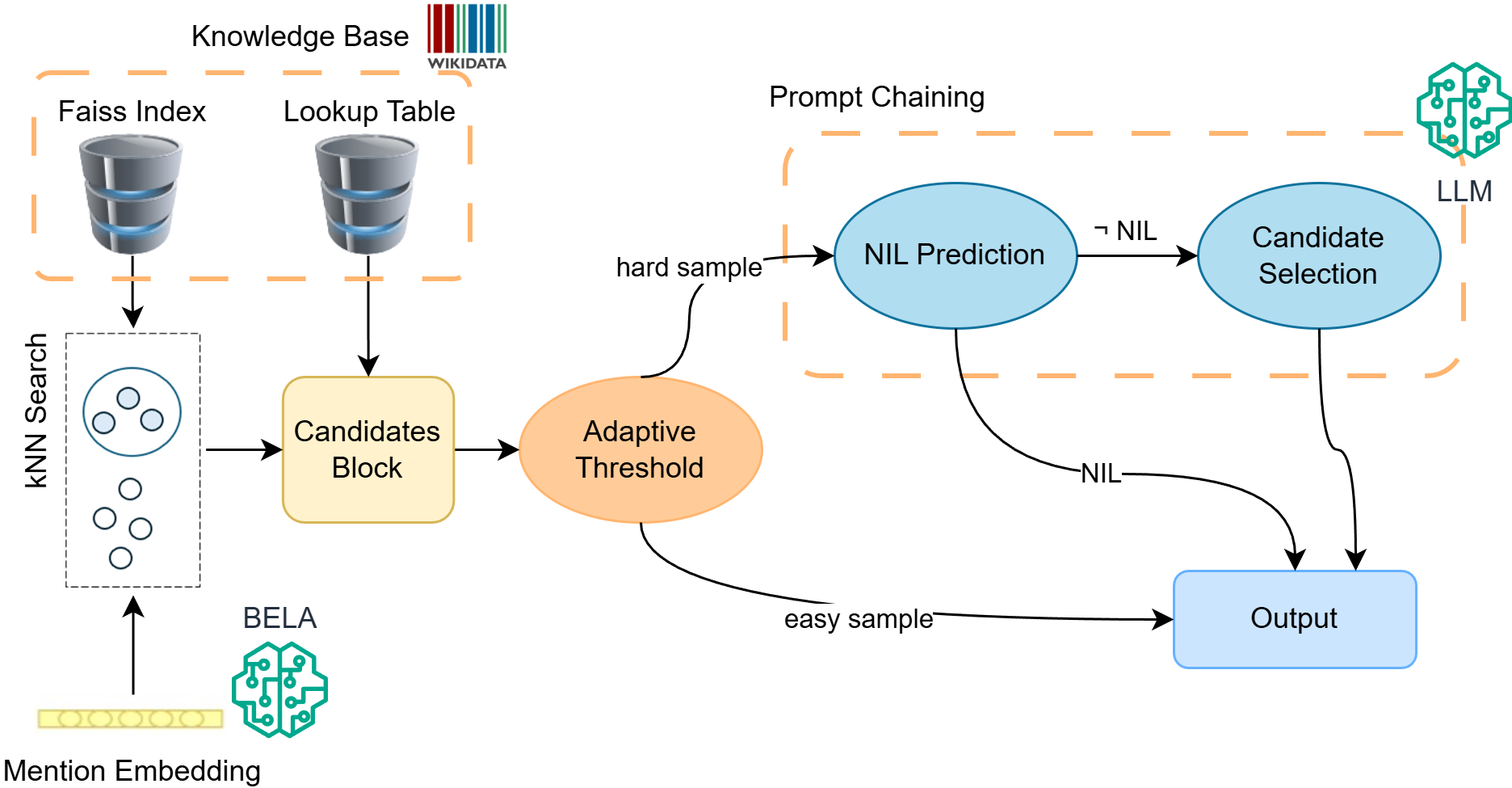
技术框架:MHEL-LLaMo系统包含以下主要模块:1) 候选检索:使用多语言双编码器(BELA)从知识库中检索候选实体。2) 置信度评估:SLM对候选实体的链接进行预测,并输出置信度分数。3) 难易样本区分:根据SLM的置信度分数,将样本分为简单和困难两类。4) LLM处理:对于困难样本,使用指令调优的LLM通过提示链进行NIL预测和候选选择。5) 结果集成:将SLM和LLM的结果进行集成,得到最终的实体链接结果。
关键创新:MHEL-LLaMo的关键创新在于其基于置信度的样本选择策略。通过SLM的置信度分数来动态地决定是否使用LLM,避免了对所有样本都使用LLM带来的高计算成本和潜在的幻觉问题。这种策略使得系统能够在保证性能的同时,实现更高的效率和鲁棒性。
关键设计:论文中关键的设计包括:1) 使用多语言双编码器BELA进行候选检索,以支持多种语言的历史文本。2) 使用指令调优的LLM,并通过提示链来引导LLM进行NIL预测和候选选择。3) 通过实验确定合适的置信度阈值,以区分简单和困难样本。具体的损失函数和网络结构细节在论文中未详细描述,属于BELA和所使用的LLM的固有属性。
🖼️ 关键图片
📊 实验亮点
MHEL-LLaMo在六种语言的四个历史文本实体链接基准测试中,无需微调即可超越现有技术水平。该方法通过置信度评估选择性地使用LLM,在保证性能的同时降低了计算成本,并减少了LLM产生幻觉的风险,为低资源历史实体链接提供了一种有效的解决方案。
🎯 应用场景
MHEL-LLaMo可应用于历史研究、数字人文、知识图谱构建等领域。它能够帮助研究人员从大量的历史文本中自动提取和链接实体,从而更好地理解历史事件、人物和关系。该方法无需大量标注数据,具有良好的可扩展性,可以应用于不同语言和历史时期的文本,为历史研究提供更高效的工具。
📄 摘要(原文)
Despite the recent advancements in NLP with the advent of Large Language Models (LLMs), Entity Linking (EL) for historical texts remains challenging due to linguistic variation, noisy inputs, and evolving semantic conventions. Existing solutions either require substantial training data or rely on domain-specific rules that limit scalability. In this paper, we present MHEL-LLaMo (Multilingual Historical Entity Linking with Large Language MOdels), an unsupervised ensemble approach combining a Small Language Model (SLM) and an LLM. MHEL-LLaMo leverages a multilingual bi-encoder (BELA) for candidate retrieval and an instruction-tuned LLM for NIL prediction and candidate selection via prompt chaining. Our system uses SLM's confidence scores to discriminate between easy and hard samples, applying an LLM only for hard cases. This strategy reduces computational costs while preventing hallucinations on straightforward cases. We evaluate MHEL-LLaMo on four established benchmarks in six European languages (English, Finnish, French, German, Italian and Swedish) from the 19th and 20th centuries. Results demonstrate that MHEL-LLaMo outperforms state-of-the-art models without requiring fine-tuning, offering a scalable solution for low-resource historical EL. The implementation of MHEL-LLaMo is available on Github.