BenchOverflow: Measuring Overflow in Large Language Models via Plain-Text Prompts
作者: Erin Feiglin, Nir Hutnik, Raz Lapid
分类: cs.CL, cs.AI
发布日期: 2026-01-13
备注: Accepted at TMLR 2026
💡 一句话要点
BenchOverflow:通过纯文本提示测量大型语言模型中的过度输出问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 过度输出 溢出问题 基准测试 长度控制 资源效率 可靠性 可持续性
📋 核心要点
- 大型语言模型存在过度输出问题,导致资源浪费和性能下降,但缺乏系统性的评估和缓解方法。
- 提出BenchOverflow基准,通过设计九种纯文本提示策略来诱导模型产生过长输出,从而评估模型的溢出风险。
- 实验结果表明,溢出问题普遍存在于各种模型中,并且可以通过简单的简洁性提醒来有效缓解。
📝 摘要(中文)
本文研究了大型语言模型(LLM)的一种失效模式,即纯文本提示引发过度输出的现象,我们称之为溢出(Overflow)。与越狱或提示注入不同,溢出发生在普通的交互设置下,并可能导致服务成本、延迟和跨用户性能下降,尤其是在大规模请求的情况下。除了可用性之外,其影响还涉及经济和环境:不必要的token会增加每次请求的成本和能源消耗,从而导致大量的运营支出和碳足迹。此外,溢出代表了一种在共享环境中进行计算放大和服务降级的实际途径。我们引入了BenchOverflow,这是一个与模型无关的基准,包含九种纯文本提示策略,可以在没有对抗性后缀或规避策略的情况下放大输出量。我们使用一个标准的协议,固定预算为5000个新token,评估了九个开源和闭源模型,并观察到长度分布中明显的右移和重尾现象。上限饱和率(CSR@1k/3k/5k)和经验累积分布函数(ECDF)量化了尾部风险;提示内的方差和跨模型相关性表明,溢出在很大程度上是可重现的,但在不同系列和攻击向量中是异构的。一种轻量级的缓解措施——固定的简洁性提醒——可以减弱右尾并降低大多数模型中所有策略的CSR。我们的发现将长度控制定位为一种可衡量的可靠性、成本和可持续性问题,而不是一种风格上的怪癖。通过实现跨模型长度控制鲁棒性的标准化比较,BenchOverflow为选择最小化资源浪费和运营费用的部署,以及评估在不损害任务性能的情况下抑制计算放大的防御措施,提供了实际基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在普通交互设置下产生的过度输出问题,即“溢出(Overflow)”。现有方法缺乏对这种现象的系统性评估和有效控制,导致资源浪费、服务延迟和潜在的性能下降。现有的prompt工程主要关注于提升模型性能,而忽略了模型输出长度控制的重要性。
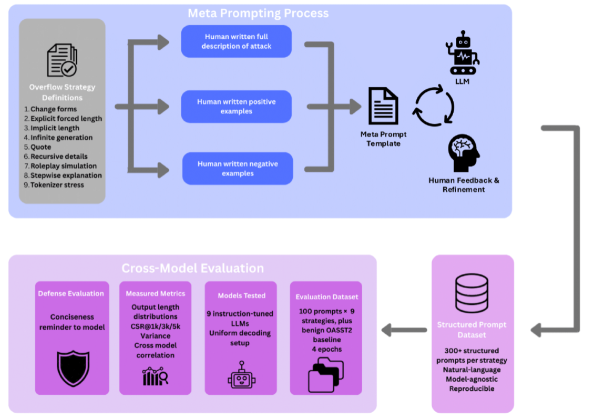
核心思路:论文的核心思路是通过设计一系列纯文本提示策略,诱导LLM产生过长的输出,从而量化和评估模型的溢出风险。通过标准化评估流程,可以比较不同模型在长度控制方面的鲁棒性,并探索有效的缓解措施。这种方法不依赖于对抗性攻击或策略规避,更贴近实际应用场景。
技术框架:BenchOverflow基准测试框架包含以下主要组成部分:1) 提示策略设计:设计九种不同的纯文本提示策略,旨在放大输出量,例如重复请求、开放式问题等。2) 模型评估:使用标准化的协议,固定5000个新token的预算,评估开源和闭源模型。3) 指标计算:计算上限饱和率(CSR@1k/3k/5k)和经验累积分布函数(ECDF),量化尾部风险。4) 缓解措施:探索轻量级的缓解措施,例如在提示中添加简洁性提醒。
关键创新:该论文的关键创新在于:1) 首次明确提出了LLM的“溢出”问题,并将其定义为一种重要的可靠性、成本和可持续性问题。2) 设计了BenchOverflow基准,提供了一种与模型无关的标准化评估方法,用于量化和比较不同模型的溢出风险。3) 提出了一种轻量级的缓解措施,可以有效降低模型的输出长度。
关键设计:在提示策略设计方面,论文考虑了多种可能导致过度输出的场景,例如开放式问题、重复请求、指令模糊等。在评估指标方面,CSR和ECDF能够有效地捕捉模型输出长度分布的尾部特征,从而量化溢出风险。在缓解措施方面,简洁性提醒的设计简单有效,可以在不影响任务性能的情况下降低输出长度。
🖼️ 关键图片
📊 实验亮点
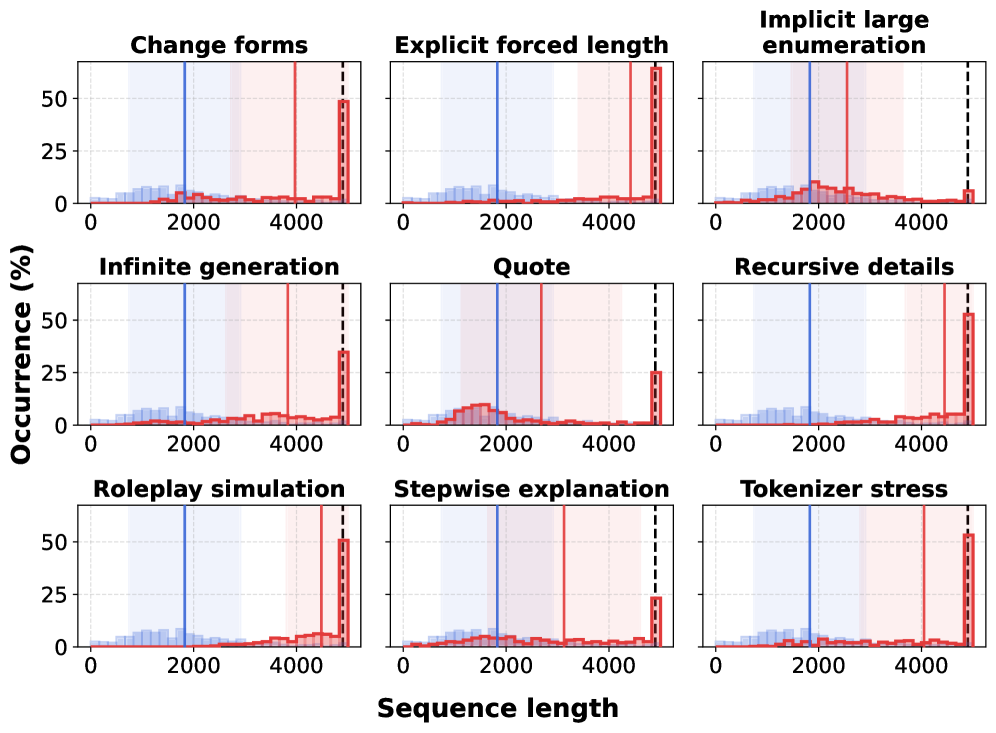
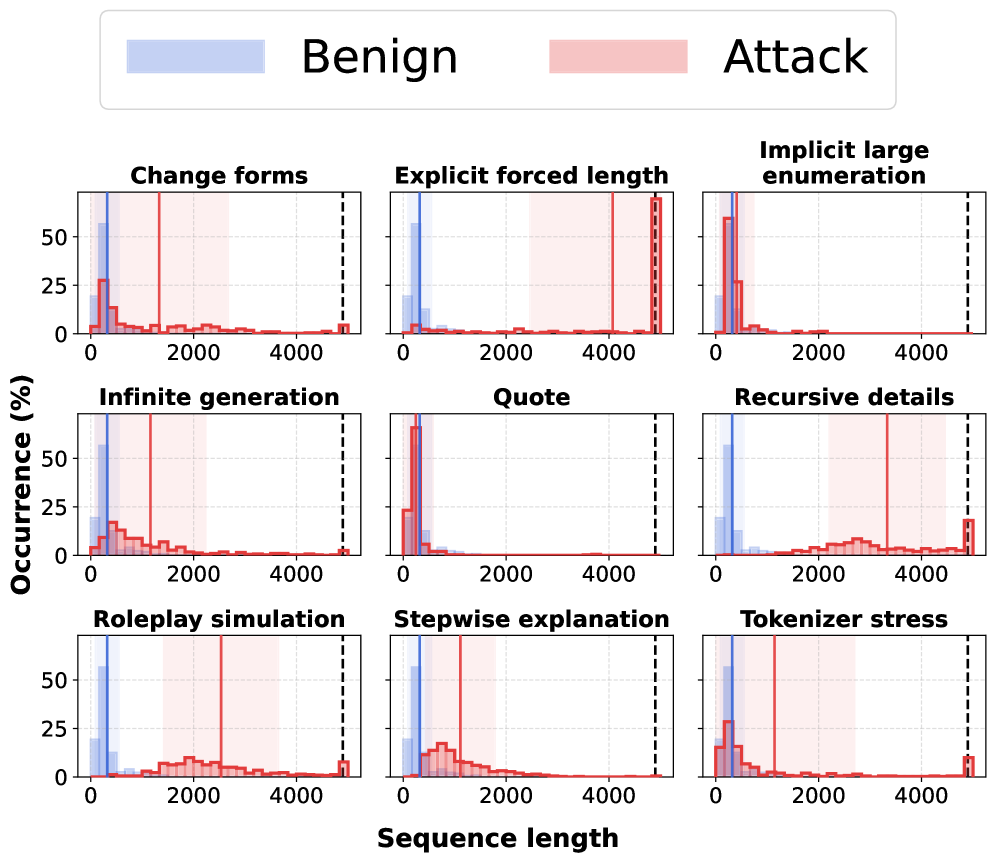
实验结果表明,不同的LLM在BenchOverflow基准上表现出显著的溢出风险,长度分布呈现明显的右移和重尾现象。上限饱和率(CSR)等指标量化了这种风险。通过在提示中添加简洁性提醒,可以有效降低模型的输出长度,降低CSR值。实验结果还表明,溢出问题在不同模型系列和攻击向量中具有异构性。
🎯 应用场景
BenchOverflow的研究成果可应用于LLM的部署和优化,帮助选择资源效率更高的模型,并评估和改进长度控制机制。该基准可以促进LLM在成本、可靠性和可持续性方面的提升,降低运营费用和碳足迹,并为共享环境中的服务降级提供防御手段。未来的研究可以探索更有效的缓解策略和更细粒度的长度控制方法。
📄 摘要(原文)
We investigate a failure mode of large language models (LLMs) in which plain-text prompts elicit excessive outputs, a phenomenon we term Overflow. Unlike jailbreaks or prompt injection, Overflow arises under ordinary interaction settings and can lead to elevated serving cost, latency, and cross-user performance degradation, particularly when scaled across many requests. Beyond usability, the stakes are economic and environmental: unnecessary tokens increase per-request cost and energy consumption, compounding into substantial operational spend and carbon footprint at scale. Moreover, Overflow represents a practical vector for compute amplification and service degradation in shared environments. We introduce BenchOverflow, a model-agnostic benchmark of nine plain-text prompting strategies that amplify output volume without adversarial suffixes or policy circumvention. Using a standardized protocol with a fixed budget of 5000 new tokens, we evaluate nine open- and closed-source models and observe pronounced rightward shifts and heavy tails in length distributions. Cap-saturation rates (CSR@1k/3k/5k) and empirical cumulative distribution functions (ECDFs) quantify tail risk; within-prompt variance and cross-model correlations show that Overflow is broadly reproducible yet heterogeneous across families and attack vectors. A lightweight mitigation-a fixed conciseness reminder-attenuates right tails and lowers CSR for all strategies across the majority of models. Our findings position length control as a measurable reliability, cost, and sustainability concern rather than a stylistic quirk. By enabling standardized comparison of length-control robustness across models, BenchOverflow provides a practical basis for selecting deployments that minimize resource waste and operating expense, and for evaluating defenses that curb compute amplification without eroding task performance.