sui-1: Grounded and Verifiable Long-Form Summarization
作者: Benedikt Droste, Jan Philipp Harries, Maximilian Idahl, Björn Plüster
分类: cs.CL, cs.AI
发布日期: 2026-01-13
备注: 13 pages, 4 figures, model weights at https://huggingface.co/ellamind/sui-1-24b
💡 一句话要点
提出sui-1模型,通过可溯源引用的长文本摘要解决现有大语言模型摘要不忠实问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本摘要 可溯源引用 合成数据 思维链提示 多阶段验证 语言模型 信息抽取
📋 核心要点
- 现有大语言模型在长文本摘要中存在生成内容不忠实于原文的问题,难以验证。
- sui-1模型通过生成带有内联引用的摘要,使用户能够追溯每个声明的来源,提高可信度。
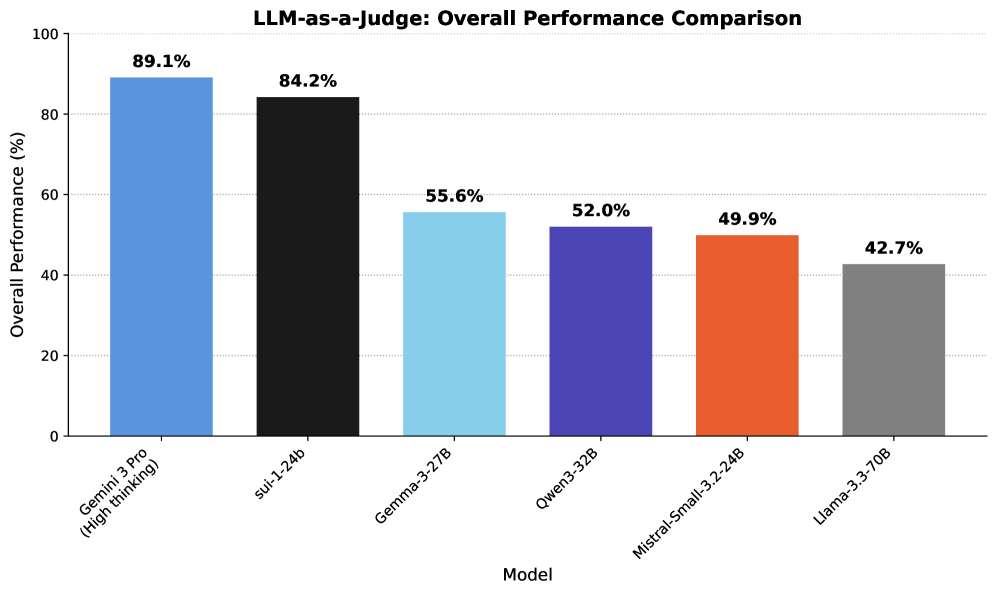
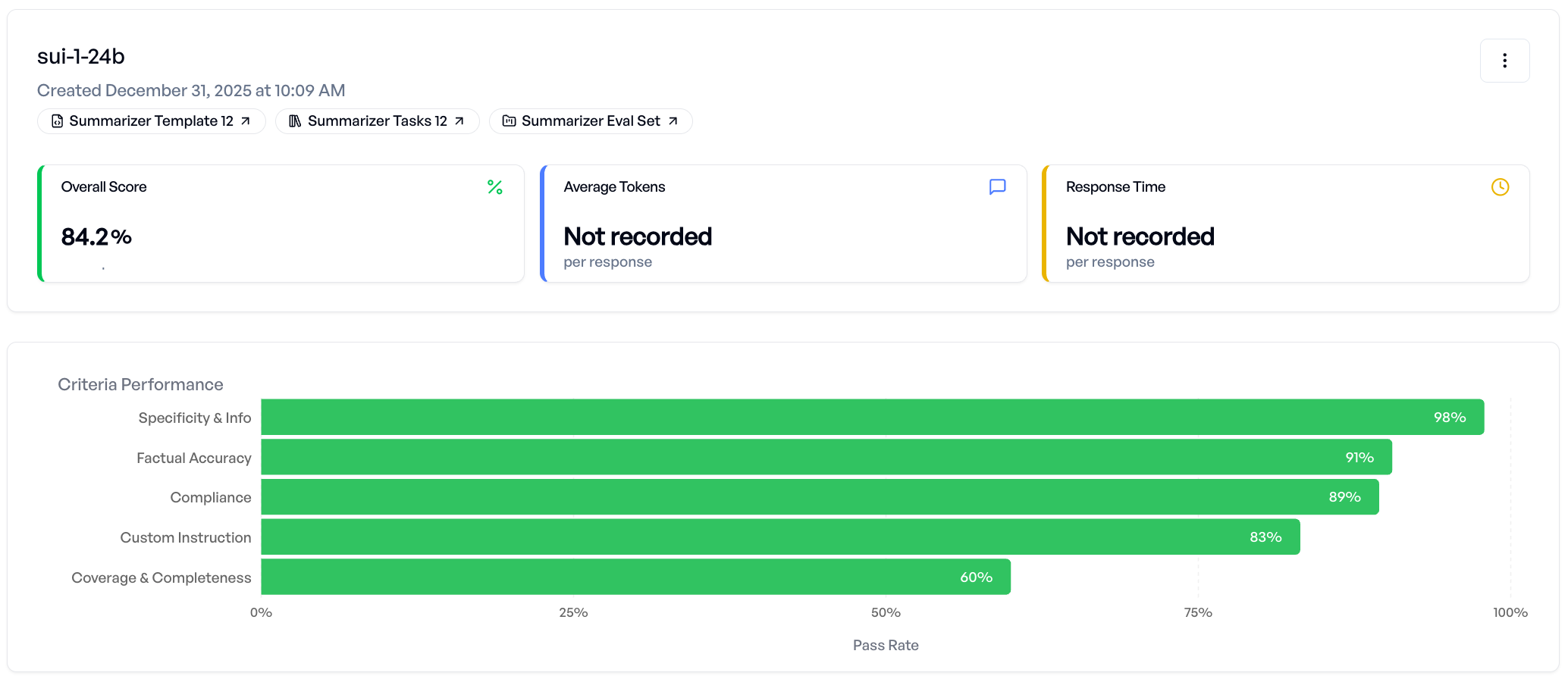
- 实验结果表明,sui-1显著优于其他开源模型,证明了特定任务训练优于单纯扩大模型规模。
📝 摘要(中文)
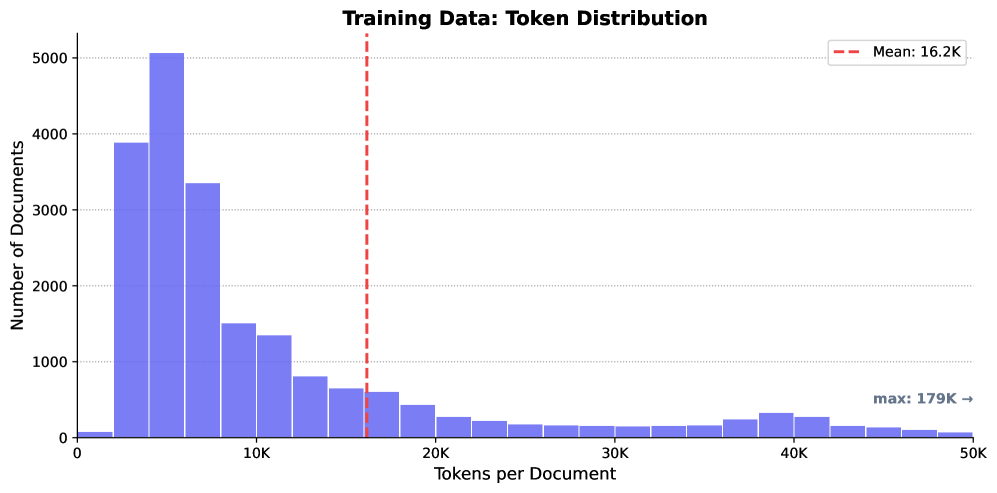
大型语言模型经常生成看似合理但不忠实的摘要,用户无法对照源文本进行验证,这在政府和法律分析等合规敏感领域是一个关键限制。我们提出了sui-1,一个240亿参数的模型,它可以生成带有内联引用的抽象摘要,使用户能够将每个声明追溯到其源语句。我们的合成数据管道结合了思维链提示和多阶段验证,从议会文件、网络文本和维基百科等不同来源生成了超过22,000个跨五种语言的高质量训练示例。评估表明,sui-1显著优于所有经过测试的开源基线模型,包括参数量是其三倍的模型。这些结果表明,对于基于引用的摘要,特定任务的训练大大优于单纯的模型规模。模型权重和交互式演示已公开。
🔬 方法详解
问题定义:现有的大型语言模型在生成长文本摘要时,经常出现“幻觉”问题,即生成的内容与原始文本不符,甚至捏造信息。用户难以验证摘要的真实性,这在需要高度准确性的领域(如法律、政府文件分析)是不可接受的。现有方法要么依赖于简单的抽取式摘要,要么生成的摘要缺乏可追溯性,无法满足实际需求。
核心思路:sui-1的核心思路是通过生成带有内联引用的摘要,将摘要中的每个claim都链接到原始文本中的对应句子。这样,用户可以通过引用快速验证摘要的准确性。为了实现这一目标,论文采用了合成数据训练的方法,并结合了思维链提示和多阶段验证机制。
技术框架:sui-1的训练流程主要包括以下几个阶段:1) 使用思维链提示生成候选摘要和引用;2) 对生成的摘要和引用进行多阶段验证,确保其准确性和一致性;3) 使用验证后的数据训练sui-1模型。模型本身是一个24B参数的Transformer模型。
关键创新:sui-1的关键创新在于其合成数据生成流程和内联引用的摘要方式。传统的摘要模型通常只生成摘要,而不提供任何引用信息。sui-1通过生成内联引用,实现了摘要的可追溯性,提高了摘要的可靠性。此外,论文提出的合成数据生成流程能够有效地生成高质量的训练数据,避免了人工标注的成本和偏差。
关键设计:论文使用了思维链提示来生成候选摘要和引用,这有助于模型更好地理解原始文本的语义,并生成更准确的摘要。多阶段验证机制包括多个验证步骤,例如检查引用是否指向原始文本中的相关句子,以及摘要是否与原始文本的内容一致。这些验证步骤可以有效地过滤掉不准确的摘要和引用。具体的参数设置和损失函数等技术细节在论文中没有详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
sui-1模型在实验中显著优于所有测试的开源基线模型,包括参数量是其三倍的模型。这表明,对于基于引用的摘要任务,特定任务的训练比单纯扩大模型规模更有效。具体的性能数据和提升幅度在论文中没有明确给出,属于未知信息。
🎯 应用场景
sui-1模型在合规性要求高的领域具有广泛的应用前景,例如政府文件分析、法律文本摘要、金融报告解读等。它可以帮助用户快速准确地理解长文本内容,并验证信息的真实性。未来,该技术可以应用于自动化报告生成、智能文档检索等领域,提高工作效率和信息质量。
📄 摘要(原文)
Large language models frequently generate plausible but unfaithful summaries that users cannot verify against source text, a critical limitation in compliance-sensitive domains such as government and legal analysis. We present sui-1, a 24B parameter model that produces abstractive summaries with inline citations, enabling users to trace each claim to its source sentence. Our synthetic data pipeline combines chain-of-thought prompting with multi-stage verification, generating over 22,000 high-quality training examples across five languages from diverse sources including parliamentary documents, web text, and Wikipedia. Evaluation shows sui-1 significantly outperforms all tested open-weight baselines, including models with 3x more parameters. These results demonstrate that task-specific training substantially outperforms scale alone for citation-grounded summarization. Model weights and an interactive demo are publicly available.