JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
作者: Jiangshan Duo, Hanyu Li, Hailin Zhang, Yudong Wang, Sujian Li, Liang Zhao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-13
备注: 16 pages, 5 figures
💡 一句话要点
JudgeRLVR:先判断后生成,提升大语言模型推理效率与泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 推理 判别模型 生成模型 数学问题求解 效率优化
📋 核心要点
- 现有RLVR方法在推理时过度依赖试错,效率低且泛化性差,难以在效率和验证间取得平衡。
- JudgeRLVR通过先训练模型判断答案有效性,再进行生成,内化指导信号以减少搜索空间。
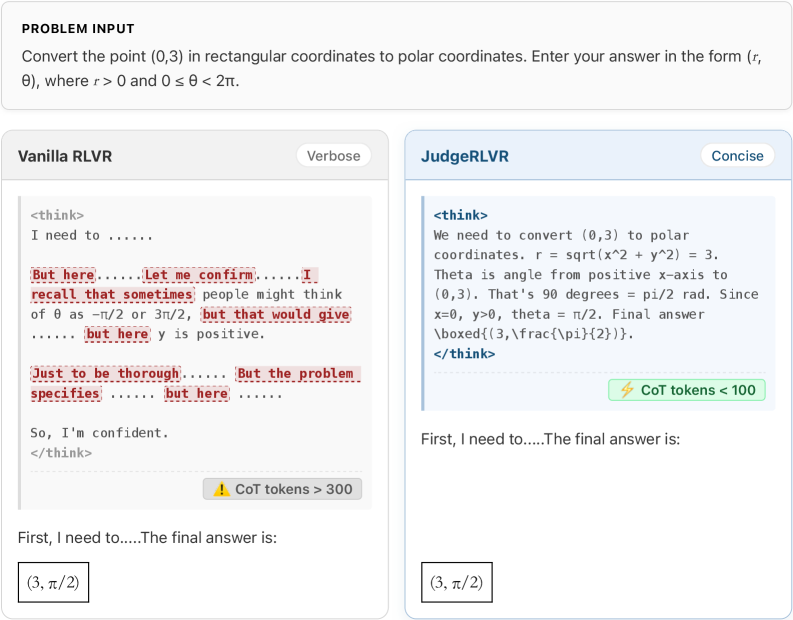
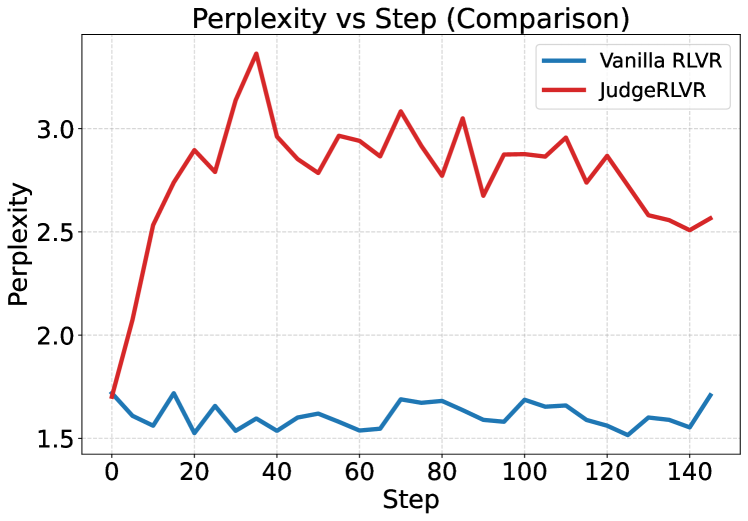
- 实验表明,JudgeRLVR在数学推理任务上,显著提升了准确率,缩短了生成长度,并增强了泛化能力。
📝 摘要(中文)
具有可验证奖励的强化学习(RLVR)已成为大语言模型推理的标准范式。然而,仅优化最终答案的正确性通常会导致模型进行漫无目的、冗长的探索,依赖于详尽的试错策略而非结构化的规划来获得解决方案。虽然长度惩罚等启发式约束可以减少冗长性,但它们通常会截断必要的推理步骤,从而在效率和验证之间造成难以权衡的矛盾。本文认为,判别能力是高效生成的前提:通过学习区分有效的解决方案,模型可以内化指导信号,从而修剪搜索空间。我们提出了JudgeRLVR,一种两阶段的判断-然后-生成范式。在第一阶段,我们训练模型来判断具有可验证答案的解决方案响应。在第二阶段,我们使用从判断阶段初始化的普通生成RLVR来微调相同的模型。与使用相同数学领域训练数据的Vanilla RLVR相比,JudgeRLVR为Qwen3-30B-A3B实现了更好的质量-效率权衡:在领域内数学问题上,它实现了约+3.7个百分点的平均准确率提升,以及-42%的平均生成长度;在领域外基准测试中,它实现了约+4.5个百分点的平均准确率提升,展示了增强的泛化能力。
🔬 方法详解
问题定义:现有基于RLVR的大语言模型推理方法,在优化最终答案正确性的过程中,容易陷入漫无目的的探索,生成冗长且低效的推理过程。同时,为了提高效率而采用的长度惩罚等策略,又可能截断必要的推理步骤,导致性能下降。因此,如何在保证推理质量的前提下,提高推理效率和泛化能力,是本文要解决的核心问题。
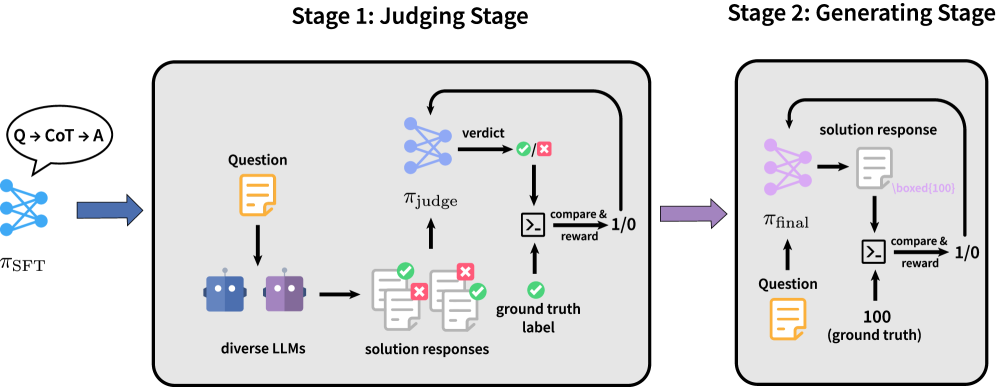
核心思路:论文的核心思路是,判别能力是高效生成的前提。通过让模型首先学习判断答案的有效性,可以使模型内化一种指导信号,从而在生成过程中更有效地修剪搜索空间,避免无效的探索。这种“先判断,后生成”的策略,旨在提高推理效率和泛化能力。
技术框架:JudgeRLVR采用两阶段的训练框架。第一阶段是“判断”阶段,使用可验证的答案训练模型判断解决方案的有效性。第二阶段是“生成”阶段,使用标准的生成式RLVR方法,但使用第一阶段训练好的模型作为初始化。整个框架利用了同一个模型,避免了引入额外的参数。
关键创新:JudgeRLVR的关键创新在于提出了“先判断,后生成”的训练范式。与传统的直接优化生成过程的RLVR方法不同,JudgeRLVR首先训练模型的判别能力,然后利用这种判别能力来指导生成过程。这种方法能够更有效地利用训练数据,提高模型的推理效率和泛化能力。
关键设计:在第一阶段的判断阶段,模型被训练来区分正确和错误的解决方案。这可以通过二元分类损失函数来实现。在第二阶段的生成阶段,使用标准的RLVR方法,例如策略梯度算法,来微调模型。关键在于使用第一阶段训练好的模型参数作为初始值,以便模型能够利用已经学习到的判别能力。具体的损失函数和超参数设置可能需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,JudgeRLVR在Qwen3-30B-A3B模型上,相较于Vanilla RLVR,在领域内数学问题上平均准确率提升了3.7个百分点,平均生成长度缩短了42%。在领域外基准测试中,平均准确率提升了4.5个百分点。这些结果表明,JudgeRLVR在提高推理效率、准确率和泛化能力方面具有显著优势。
🎯 应用场景
JudgeRLVR方法可应用于各种需要复杂推理的场景,例如数学问题求解、代码生成、知识图谱推理等。通过提高推理效率和泛化能力,该方法可以降低大语言模型在这些领域的应用成本,并提升用户体验。未来,该方法有望扩展到更广泛的认知任务中,例如智能客服、教育辅导等。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for reasoning in Large Language Models. However, optimizing solely for final-answer correctness often drives models into aimless, verbose exploration, where they rely on exhaustive trial-and-error tactics rather than structured planning to reach solutions. While heuristic constraints like length penalties can reduce verbosity, they often truncate essential reasoning steps, creating a difficult trade-off between efficiency and verification. In this paper, we argue that discriminative capability is a prerequisite for efficient generation: by learning to distinguish valid solutions, a model can internalize a guidance signal that prunes the search space. We propose JudgeRLVR, a two-stage judge-then-generate paradigm. In the first stage, we train the model to judge solution responses with verifiable answers. In the second stage, we fine-tune the same model with vanilla generating RLVR initialized from the judge. Compared to Vanilla RLVR using the same math-domain training data, JudgeRLVR achieves a better quality--efficiency trade-off for Qwen3-30B-A3B: on in-domain math, it delivers about +3.7 points average accuracy gain with -42\% average generation length; on out-of-domain benchmarks, it delivers about +4.5 points average accuracy improvement, demonstrating enhanced generalization.