Silence the Judge: Reinforcement Learning with Self-Verifier via Latent Geometric Clustering
作者: Nonghai Zhang, Weitao Ma, Zhanyu Ma, Jun Xu, Jiuchong Gao, Jinghua Hao, Renqing He, Jingwen Xu
分类: cs.CL, cs.LG
发布日期: 2026-01-13
💡 一句话要点
Latent-GRPO:基于隐空间几何聚类的自验证强化学习,提升LLM推理效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理优化 隐空间几何 自验证
📋 核心要点
- 现有GRPO方法依赖外部验证器或人工规则,导致计算成本高、训练延迟高,以及奖励稀疏。
- Latent-GRPO从隐空间几何中提取内在奖励,利用正确推理轨迹在隐空间形成密集簇的特性。
- 通过IRCE算法生成密集连续的奖励,实验表明训练速度提升2倍以上,并具有良好的泛化性和鲁棒性。
📝 摘要(中文)
本文提出Latent-GRPO框架,旨在解决大型语言模型(LLMs)中Group Relative Policy Optimization (GRPO)方法对昂贵外部验证器或人工规则的依赖问题。Latent-GRPO直接从隐空间几何中提取内在奖励,避免了计算成本高昂和训练延迟的问题,以及由此产生的稀疏奖励。该方法基于一项几何特性发现:正确推理轨迹的末端token表示在隐空间中形成高内聚的簇,而错误轨迹则分散为离群点。为此,本文引入了迭代鲁棒质心估计(IRCE)算法,通过球面投影减轻幅度波动,并通过迭代聚合估计鲁棒的“真值质心”,从而生成密集、连续的奖励。实验结果表明,该方法在保持模型性能的同时,训练速度比基线方法提高了2倍以上,并展现出强大的泛化能力和鲁棒性。
🔬 方法详解
问题定义:现有基于GRPO的LLM推理方法严重依赖外部验证器或人工规则来提供奖励信号。这些外部验证器通常计算成本高昂,引入额外的训练延迟,并且提供的奖励信号通常是稀疏的,不利于模型的优化。因此,如何摆脱对外部验证器的依赖,直接从模型内部获取有效的奖励信号,是本文要解决的核心问题。
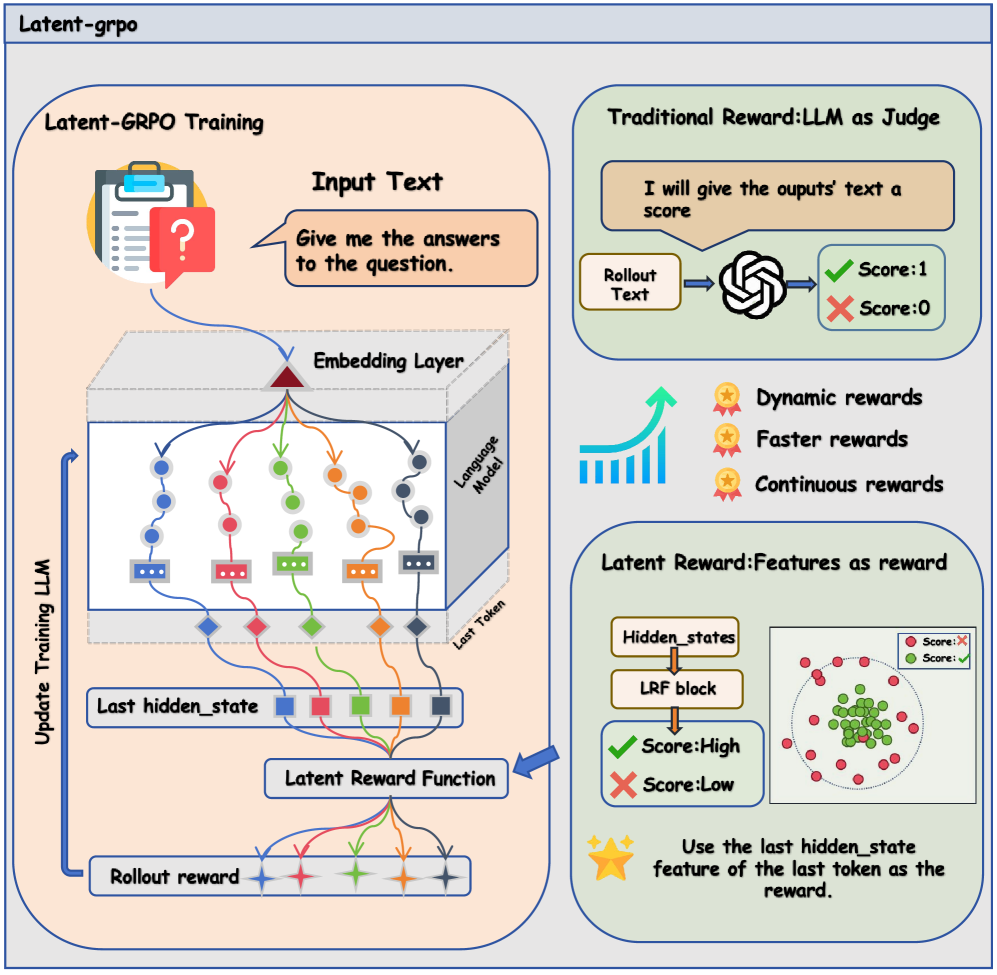
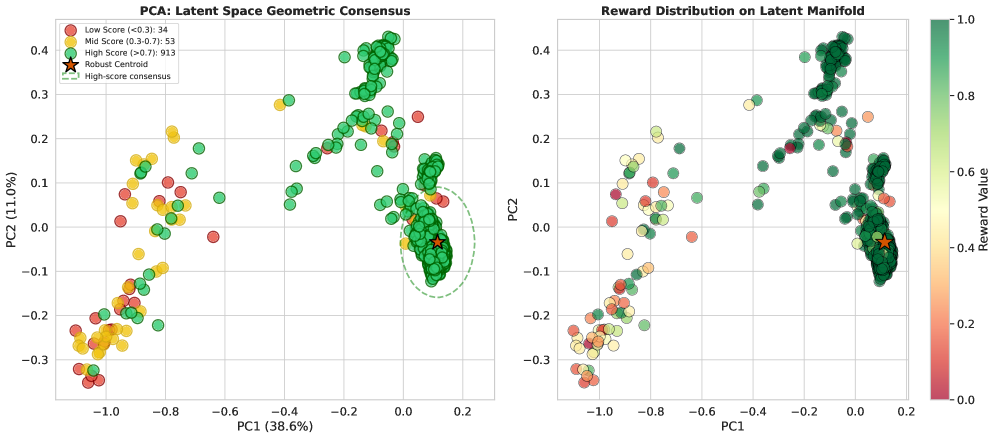
核心思路:本文的核心思路是利用LLM在隐空间中的几何特性来生成内在奖励。具体而言,作者观察到,对于推理任务,正确的轨迹在隐空间中会聚集形成一个高密度的簇,而错误的轨迹则会分散在周围。因此,可以通过度量轨迹在隐空间中的聚集程度来判断其正确性,并以此作为奖励信号。这种方法避免了对外部验证器的依赖,可以直接从模型内部获取奖励信号。
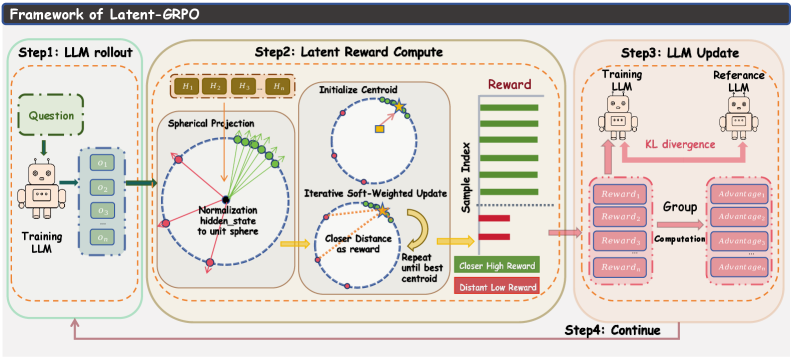
技术框架:Latent-GRPO框架主要包含以下几个阶段:1) 使用LLM生成多个推理轨迹;2) 将每个轨迹的末端token表示映射到隐空间;3) 使用IRCE算法估计隐空间中“真值质心”;4) 计算每个轨迹的末端token表示与“真值质心”之间的距离,作为奖励信号;5) 使用强化学习算法优化LLM的策略。
关键创新:本文最重要的技术创新点在于发现了LLM在隐空间中的几何特性,并利用这一特性来生成内在奖励。与现有方法相比,Latent-GRPO不需要外部验证器,可以直接从模型内部获取奖励信号,从而降低了计算成本和训练延迟。此外,IRCE算法通过迭代聚合的方式估计“真值质心”,能够有效地处理噪声数据,提高奖励信号的准确性。
关键设计:IRCE算法是Latent-GRPO的关键组成部分。该算法首先对隐空间中的token表示进行球面投影,以减轻幅度波动的影响。然后,通过迭代的方式,每次选择距离当前质心最近的若干个token表示,并将其平均作为新的质心。重复这一过程,直到质心收敛。最终的质心被认为是“真值质心”。奖励信号被设计为轨迹末端token表示与“真值质心”之间的负距离,距离越小,奖励越高。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Latent-GRPO在多个数据集上取得了显著的性能提升。例如,在某个数据集上,Latent-GRPO在保持模型性能的同时,训练速度比基线方法提高了2倍以上。此外,实验还表明,Latent-GRPO具有很强的泛化能力和鲁棒性,能够在不同的任务和数据集上取得良好的效果。这些结果表明,Latent-GRPO是一种有效的LLM推理优化方法。
🎯 应用场景
Latent-GRPO具有广泛的应用前景,可以应用于各种需要LLM进行推理的任务中,例如问答、数学问题求解、代码生成等。该方法降低了对外部验证器的依赖,可以降低计算成本,提高训练效率,并促进LLM在资源受限环境中的部署。此外,该方法还可以用于提高LLM的鲁棒性和泛化能力,使其能够更好地适应不同的任务和数据集。
📄 摘要(原文)
Group Relative Policy Optimization (GRPO) significantly enhances the reasoning performance of Large Language Models (LLMs). However, this success heavily relies on expensive external verifiers or human rules. Such dependency not only leads to significant computational costs and training latency, but also yields sparse rewards that hinder optimization efficiency. To address these challenges, we propose Latent-GRPO, a framework that derives intrinsic rewards directly from latent space geometry. Crucially, our empirical analysis reveals a compelling geometric property: terminal token representations of correct reasoning trajectories form dense clusters with high intra-class similarity, whereas incorrect trajectories remain scattered as outliers. In light of this discovery, we introduce the Iterative Robust Centroid Estimation (IRCE) algorithm, which generates dense, continuous rewards by mitigating magnitude fluctuations via spherical projection and estimating a robust ``truth centroid'' through iterative aggregation. Experimental results on multiple datasets show that our method maintains model performance while achieving a training speedup of over 2x compared to baselines. Furthermore, extensive results demonstrate strong generalization ability and robustness. The code will be released soon.