CLaS-Bench: A Cross-Lingual Alignment and Steering Benchmark
作者: Daniil Gurgurov, Yusser Al Ghussin, Tanja Baeumel, Cheng-Ting Chou, Patrick Schramowski, Marius Mosbach, Josef van Genabith, Simon Ostermann
分类: cs.CL
发布日期: 2026-01-13
备注: pre-print
💡 一句话要点
CLaS-Bench:提出跨语言对齐与操控基准,评估LLM多语言操控能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 steering技术 跨语言对齐 基准测试 语言表示 残差流 DiffMean
📋 核心要点
- 现有方法缺乏量化LLM多语言操控效果的基准,阻碍了steering技术的发展和评估。
- CLaS-Bench通过并行问题基准,系统评估LLM在32种语言中的语言强制行为,支持多语言steering方法研究。
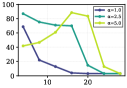
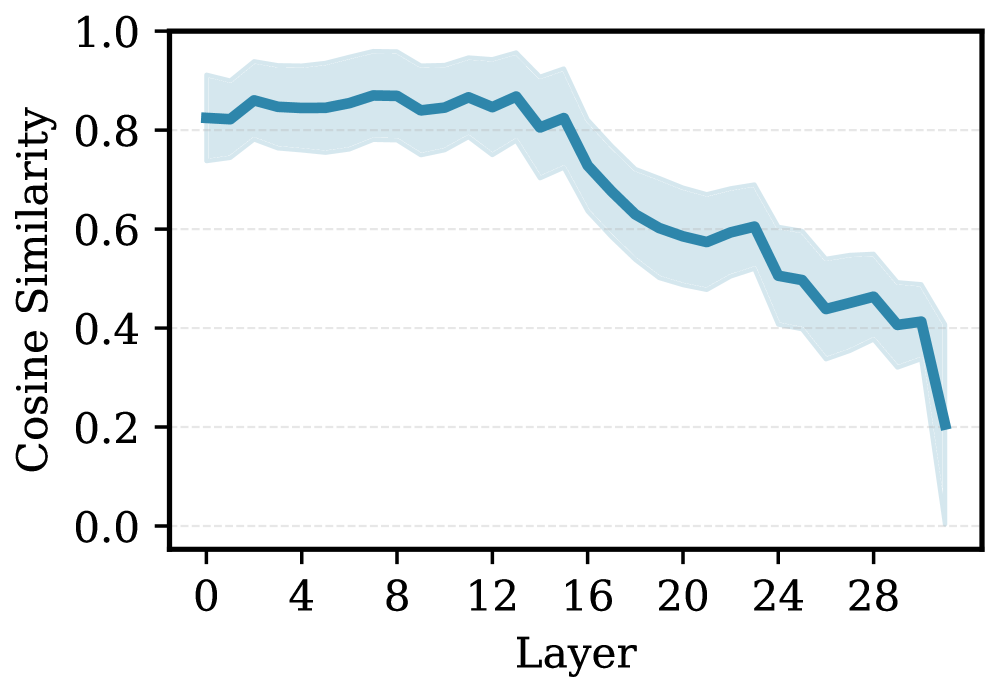
- 实验表明,简单的残差流DiffMean方法在跨语言steering中表现最佳,且语言结构主要出现在LLM的后期层。
📝 摘要(中文)
理解和控制大型语言模型(LLMs)的行为在多语言NLP中变得越来越重要。除了提示或微调之外,在推理过程中操纵内部表示(即steering)已成为一种更有效和可解释的技术,用于将模型适应目标语言。然而,目前还没有专门的基准或评估协议来量化steering技术的有效性。我们推出了CLaS-Bench,这是一个轻量级的并行问题基准,用于评估LLMs在32种语言中的语言强制行为,从而能够系统地评估多语言steering方法。我们评估了一系列steering技术,包括残差流DiffMean干预、探针派生的方向、特定于语言的神经元、PCA/LDA向量、稀疏自动编码器和提示基线。steering性能从两个方面衡量:语言控制和语义相关性,并组合成一个单一的调和平均steering分数。我们发现,在所有语言中,简单的基于残差的DiffMean方法始终优于所有其他方法。此外,逐层分析表明,特定于语言的结构主要出现在后面的层中,并且steering方向基于语系进行聚类。CLaS-Bench是第一个用于多语言steering的标准化基准,能够对语言表示进行严格的科学分析,并对steering作为一种低成本的适应替代方案进行实际评估。
🔬 方法详解
问题定义:论文旨在解决缺乏有效基准来评估和比较大型语言模型(LLMs)在多语言环境下的steering技术的问题。现有的方法,如prompting和fine-tuning,虽然可以调整LLM的行为,但在效率和可解释性方面存在局限性。此外,缺乏标准化的评估协议使得难以系统地比较不同的steering方法,并深入理解LLM内部的语言表示。
核心思路:论文的核心思路是构建一个专门的基准测试集CLaS-Bench,该基准包含32种语言的并行问题,用于评估LLM的语言强制行为。通过系统地评估各种steering技术,并结合语言控制和语义相关性两个指标,可以量化steering方法的有效性。此外,通过分析不同层级的steering效果和steering方向的聚类情况,可以深入了解LLM内部的语言表示。
技术框架:CLaS-Bench基准测试集包含32种语言的并行问题。论文评估了多种steering技术,包括:1) 残差流DiffMean干预;2) 探针派生的方向;3) 语言特定的神经元;4) PCA/LDA向量;5) 稀疏自动编码器;6) prompting基线。评估过程主要包含两个方面:语言控制(模型输出目标语言的程度)和语义相关性(模型输出答案的质量)。最终,将这两个指标结合成一个调和平均steering分数,用于综合评估steering性能。
关键创新:CLaS-Bench是第一个专门用于多语言steering的标准化基准。它提供了一个统一的平台,用于评估和比较不同的steering方法,并深入了解LLM内部的语言表示。此外,论文还发现,简单的基于残差的DiffMean方法在跨语言steering中表现最佳,并且语言结构主要出现在LLM的后期层,这些发现为未来的研究提供了重要的指导。
关键设计:CLaS-Bench的关键设计在于其并行问题的构建,保证了在不同语言环境下问题的一致性。评估指标的设计也至关重要,语言控制和语义相关性的结合能够全面地评估steering的性能。此外,论文还进行了逐层分析,以了解不同层级对steering效果的影响。DiffMean方法的具体实现细节(例如,如何计算残差流的均值)以及其他steering方法的参数设置,在论文中应该有详细的描述(具体细节需要参考原文)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,简单的基于残差的DiffMean方法在跨语言steering中始终优于其他方法。逐层分析显示,语言特定结构主要出现在LLM的后期层。此外,steering方向基于语系进行聚类,表明LLM在内部学习到了语言之间的关系。
🎯 应用场景
该研究成果可应用于多语言机器翻译、跨语言信息检索、多语言对话系统等领域。通过steering技术,可以低成本地将LLM适配到不同的目标语言,提高模型在特定语言环境下的性能。此外,该基准测试集可以促进对LLM内部语言表示的深入理解,为未来的模型设计和优化提供指导。
📄 摘要(原文)
Understanding and controlling the behavior of large language models (LLMs) is an increasingly important topic in multilingual NLP. Beyond prompting or fine-tuning, , i.e.,~manipulating internal representations during inference, has emerged as a more efficient and interpretable technique for adapting models to a target language. Yet, no dedicated benchmarks or evaluation protocols exist to quantify the effectiveness of steering techniques. We introduce CLaS-Bench, a lightweight parallel-question benchmark for evaluating language-forcing behavior in LLMs across 32 languages, enabling systematic evaluation of multilingual steering methods. We evaluate a broad array of steering techniques, including residual-stream DiffMean interventions, probe-derived directions, language-specific neurons, PCA/LDA vectors, Sparse Autoencoders, and prompting baselines. Steering performance is measured along two axes: language control and semantic relevance, combined into a single harmonic-mean steering score. We find that across languages simple residual-based DiffMean method consistently outperforms all other methods. Moreover, a layer-wise analysis reveals that language-specific structure emerges predominantly in later layers and steering directions cluster based on language family. CLaS-Bench is the first standardized benchmark for multilingual steering, enabling both rigorous scientific analysis of language representations and practical evaluation of steering as a low-cost adaptation alternative.