Triplets Better Than Pairs: Towards Stable and Effective Self-Play Fine-Tuning for LLMs
作者: Yibo Wang, Hai-Long Sun, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, Lijun Zhang
分类: cs.CL, cs.LG
发布日期: 2026-01-13
备注: NeurIPS 2025
💡 一句话要点
提出T-SPIN,通过三元组损失和熵约束,稳定高效地进行LLM的自博弈微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自博弈微调 大型语言模型 三元组损失 熵约束 优化稳定 数据稀缺 无参考微调
📋 核心要点
- 自博弈微调(SPIN)优化标注响应相对于合成响应的优势,但这种优势可能逐渐消失,导致优化不稳定。
- T-SPIN通过引入历史优势和熵约束,稳定优化过程并消除训练-生成差异,实现更有效的自博弈微调。
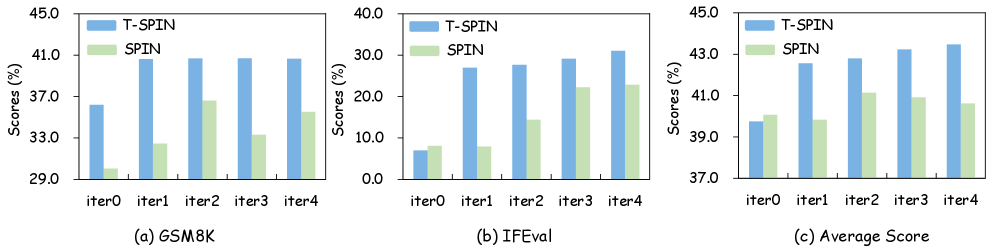
- 实验表明,T-SPIN优于SPIN,且仅用25%的监督数据即可达到与监督微调相当甚至更好的性能。
📝 摘要(中文)
本文提出了一种新颖的基于三元组的自博弈微调方法(T-SPIN),旨在解决大型语言模型(LLM)在自博弈微调(SPIN)中存在的优化不稳定和训练-生成不一致问题。T-SPIN不仅利用当前标注响应相对于合成响应的优势,还引入了迭代生成的响应与初始策略产生的原始合成响应之间的历史优势,从而稳定优化过程。此外,T-SPIN将熵约束引入自博弈框架,从理论上支持无参考策略的微调,消除了训练和生成之间的差异。在各种任务上的实验结果表明,T-SPIN优于SPIN,并在迭代过程中表现出稳定的演化。值得注意的是,与监督微调相比,T-SPIN仅使用25%的样本即可达到相当甚至更好的性能,突显了其在标注数据稀缺情况下的有效性。
🔬 方法详解
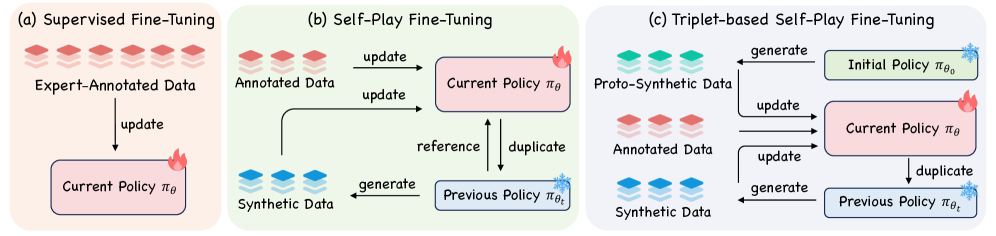
问题定义:现有的自博弈微调方法(SPIN)主要存在两个问题。一是优化过程不稳定,因为SPIN旨在优化标注响应相对于当前合成响应的优势,但这种优势可能在迭代过程中逐渐消失。二是训练和生成之间存在不一致性,因为SPIN依赖于参考策略,而训练时的奖励函数与生成时的指标不一致。
核心思路:T-SPIN的核心思路是通过引入三元组损失和熵约束来解决SPIN的优化不稳定和训练-生成不一致问题。三元组损失利用了历史优势,即使当前优势消失,历史优势仍然有效,从而稳定优化过程。熵约束则允许无参考策略的微调,消除了训练和生成之间的差异。
技术框架:T-SPIN的整体框架仍然是自博弈微调,但其损失函数和训练方式与SPIN不同。首先,T-SPIN使用三元组损失,该损失考虑了标注响应、当前合成响应和原始合成响应之间的关系。其次,T-SPIN引入了熵约束,鼓励模型生成更多样化的响应。整个训练过程仍然是迭代的,每次迭代都会生成新的合成响应,并使用三元组损失和熵约束来更新模型。
关键创新:T-SPIN的关键创新在于引入了三元组损失和熵约束。三元组损失利用了历史信息,稳定了优化过程。熵约束则允许无参考策略的微调,消除了训练和生成之间的差异。这使得T-SPIN能够更有效地利用少量标注数据进行微调。
关键设计:T-SPIN的关键设计包括三元组损失的具体形式和熵约束的强度。三元组损失通常采用hinge loss或margin ranking loss的形式,用于最大化标注响应与合成响应之间的差距,同时最小化合成响应与原始合成响应之间的差距。熵约束的强度需要根据具体任务进行调整,以平衡生成响应的多样性和质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,T-SPIN在各种任务上都优于SPIN,并且在迭代过程中表现出更稳定的性能。值得注意的是,T-SPIN仅使用25%的监督数据即可达到与监督微调相当甚至更好的性能,这表明T-SPIN在数据稀缺的情况下具有很强的竞争力。这些结果验证了T-SPIN的有效性和实用性。
🎯 应用场景
T-SPIN可应用于各种需要利用少量标注数据进行LLM微调的场景,例如特定领域的对话生成、文本摘要、代码生成等。该方法尤其适用于标注数据获取成本高昂的领域,可以显著降低微调成本,并提高LLM在特定任务上的性能。未来,T-SPIN可以进一步扩展到多模态LLM的微调,以及更复杂的自博弈训练策略。
📄 摘要(原文)
Recently, self-play fine-tuning (SPIN) has been proposed to adapt large language models to downstream applications with scarce expert-annotated data, by iteratively generating synthetic responses from the model itself. However, SPIN is designed to optimize the current reward advantages of annotated responses over synthetic responses at hand, which may gradually vanish during iterations, leading to unstable optimization. Moreover, the utilization of reference policy induces a misalignment issue between the reward formulation for training and the metric for generation. To address these limitations, we propose a novel Triplet-based Self-Play fIne-tuNing (T-SPIN) method that integrates two key designs. First, beyond current advantages, T-SPIN additionally incorporates historical advantages between iteratively generated responses and proto-synthetic responses produced by the initial policy. Even if the current advantages diminish, historical advantages remain effective, stabilizing the overall optimization. Second, T-SPIN introduces the entropy constraint into the self-play framework, which is theoretically justified to support reference-free fine-tuning, eliminating the training-generation discrepancy. Empirical results on various tasks demonstrate not only the superior performance of T-SPIN over SPIN, but also its stable evolution during iterations. Remarkably, compared to supervised fine-tuning, T-SPIN achieves comparable or even better performance with only 25% samples, highlighting its effectiveness when faced with scarce annotated data.