Relational Knowledge Distillation Using Fine-tuned Function Vectors
作者: Andrea Kang, Yingnian Wu, Hongjing Lu
分类: cs.CL, cs.LG
发布日期: 2026-01-13
💡 一句话要点
通过微调函数向量进行关系知识蒸馏,提升LLM推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关系知识蒸馏 函数向量 激活修补 类比推理 语言模型 知识表示
📋 核心要点
- 现有LLM在关系推理方面存在不足,难以有效提取和利用概念间的关系知识。
- 通过微调少量样本的函数向量,并结合复合函数向量,增强LLM对关系知识的编码和操纵能力。
- 实验表明,该方法在词语补全和类比推理任务上均有显著提升,并与人类判断更一致。
📝 摘要(中文)
表示概念之间的关系是智能系统理解世界的关键前提。最近使用因果中介分析的研究表明,一小组注意力头在上下文学习中编码任务表示,并被捕获在一个称为函数向量的紧凑表示中。我们证明,仅使用少量示例(约20个词对)微调函数向量,在基于关系的词语补全任务上,比使用从因果中介分析导出的原始向量产生更好的性能。这些改进适用于小型和大型语言模型。此外,微调的函数向量提高了关系词的解码性能,并显示出与人类对语义关系的相似性判断更强的一致性。接下来,我们引入复合函数向量——微调函数向量的加权组合——以提取关系知识并支持类比推理。在推理时,将此复合向量插入LLM激活中,显着提高了认知科学和SAT基准中具有挑战性的类比问题的性能。我们的结果突出了激活修补作为一种可控机制的潜力,用于编码和操纵关系知识,从而提高大型语言模型的可解释性和推理能力。
🔬 方法详解
问题定义:大型语言模型(LLM)在理解和推理概念之间的关系方面面临挑战。现有的方法,例如直接使用LLM进行推理,或者使用因果中介分析提取的函数向量,在关系推理任务上的表现仍然有限,尤其是在需要复杂类比推理的场景下。这些方法难以有效地捕捉和利用概念间的细微关系。
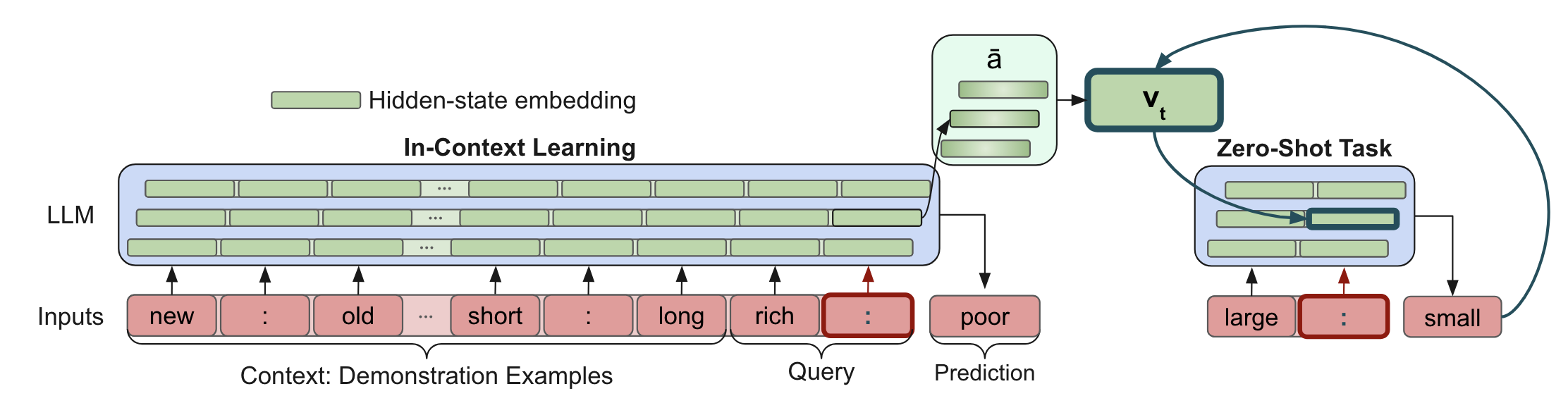
核心思路:本论文的核心思路是通过微调从因果中介分析中获得的函数向量,使其更好地编码关系知识。然后,通过组合多个微调后的函数向量,形成复合函数向量,从而更全面地表示关系知识。在推理时,将这些向量注入到LLM的激活中,以引导LLM进行更准确的关系推理。
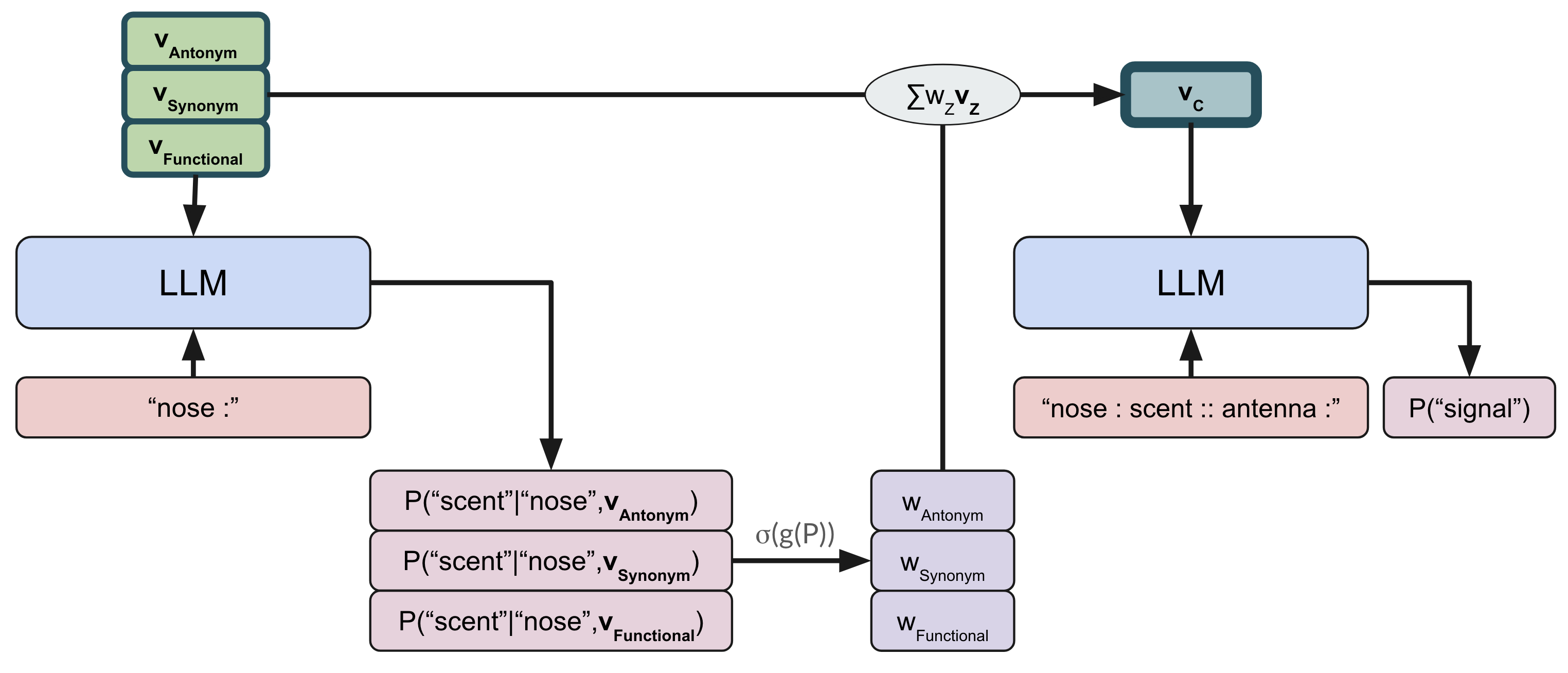
技术框架:该方法主要包含以下几个阶段:1) 使用因果中介分析提取LLM的函数向量;2) 使用少量关系示例(例如,20个词对)微调函数向量,使其更好地适应特定的关系类型;3) 构建复合函数向量,即对多个微调后的函数向量进行加权组合,以表示更复杂的关系知识;4) 在推理时,使用激活修补技术,将复合函数向量插入到LLM的激活中,从而影响LLM的输出。
关键创新:该方法的关键创新在于:1) 使用微调后的函数向量来编码关系知识,相比于原始的函数向量,微调后的向量更能捕捉特定关系类型的特征;2) 引入复合函数向量,通过组合多个微调后的向量,可以表示更复杂的关系知识,例如类比关系;3) 利用激活修补技术,将关系知识注入到LLM的激活中,从而实现对LLM推理过程的精确控制。
关键设计:在微调阶段,使用少量关系示例(约20个词对)进行微调,以避免过拟合。复合函数向量的权重可以通过学习得到,也可以手动设置。激活修补的位置和方式需要根据具体的LLM架构和任务进行调整。损失函数的设计需要考虑关系推理的准确性和与人类判断的一致性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,微调后的函数向量在关系词解码和与人类相似性判断的一致性方面均优于原始向量。在类比推理任务中,使用复合函数向量进行激活修补,显著提高了LLM在认知科学和SAT基准上的性能。例如,在某些类比问题上,性能提升幅度超过10%。这些结果表明,该方法能够有效地增强LLM的关系推理能力。
🎯 应用场景
该研究成果可应用于提升LLM在知识图谱推理、常识推理、问答系统等领域的性能。通过将关系知识显式地编码到LLM中,可以提高LLM的可解释性和可控性,使其能够更好地理解和利用世界知识,从而在教育、医疗、金融等领域发挥更大的作用。此外,该方法还可以用于构建更强大的类比推理系统,辅助科学发现和创新。
📄 摘要(原文)
Representing relations between concepts is a core prerequisite for intelligent systems to make sense of the world. Recent work using causal mediation analysis has shown that a small set of attention heads encodes task representation in in-context learning, captured in a compact representation known as the function vector. We show that fine-tuning function vectors with only a small set of examples (about 20 word pairs) yields better performance on relation-based word-completion tasks than using the original vectors derived from causal mediation analysis. These improvements hold for both small and large language models. Moreover, the fine-tuned function vectors yield improved decoding performance for relation words and show stronger alignment with human similarity judgments of semantic relations. Next, we introduce the composite function vector - a weighted combination of fine-tuned function vectors - to extract relational knowledge and support analogical reasoning. At inference time, inserting this composite vector into LLM activations markedly enhances performance on challenging analogy problems drawn from cognitive science and SAT benchmarks. Our results highlight the potential of activation patching as a controllable mechanism for encoding and manipulating relational knowledge, advancing both the interpretability and reasoning capabilities of large language models.