Qalb: Largest State-of-the-Art Urdu Large Language Model for 230M Speakers with Systematic Continued Pre-training
作者: Muhammad Taimoor Hassan, Jawad Ahmed, Muhammad Awais
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-13
💡 一句话要点
Qalb:面向2.3亿使用者的先进乌尔都语大语言模型,通过系统性持续预训练实现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 乌尔都语 大语言模型 持续预训练 指令微调 低资源语言 自然语言处理 LLaMA
📋 核心要点
- 现有模型在乌尔都语处理上表现不佳,无法有效处理其复杂形态和文化特性,限制了乌尔都语自然语言处理的发展。
- Qalb通过持续预训练和指令微调,将LLaMA 3.1 8B模型适配到乌尔都语,提升了模型在乌尔都语任务上的性能。
- Qalb在乌尔都语基准测试中取得了显著提升,加权平均分达到90.34,超越了现有最佳模型Alif-1.0-Instruct。
📝 摘要(中文)
尽管大型语言模型取得了显著进展,但拥有超过2.3亿使用者的乌尔都语在现代自然语言处理系统中仍然严重缺乏代表性。现有的多语言模型在乌尔都语特定任务上表现不佳,难以处理该语言复杂的形态、从右到左的纳斯塔利克文字以及丰富的文学传统。即使是基础的LLaMA-3.1 8B-Instruct模型在生成流畅、符合语境的乌尔都语文本方面也显示出有限的能力。我们推出了Qalb,一个通过两阶段方法开发的乌尔都语语言模型:持续预训练和监督微调。从LLaMA 3.1 8B开始,我们对一个包含19.7亿tokens的数据集进行了持续预训练。该语料库包含18.4亿tokens的多样化乌尔都语文本(涵盖新闻档案、古典和当代文学、政府文件和社交媒体),以及1.4亿tokens的英语维基百科数据,以防止灾难性遗忘。然后,我们在Alif Urdu-instruct数据集上对生成的模型进行微调。通过对乌尔都语特定基准的广泛评估,Qalb表现出显著的改进,实现了90.34的加权平均分,超过了之前的最先进模型Alif-1.0-Instruct(87.1)3.24分,同时也超过了基础LLaMA-3.1 8B-Instruct模型44.64分。Qalb在包括分类、情感分析和推理在内的七个不同任务的综合评估中实现了最先进的性能。我们的结果表明,对多样化、高质量的语言数据进行持续预训练,结合有针对性的指令微调,可以有效地将基础模型适应于低资源语言。
🔬 方法详解
问题定义:论文旨在解决乌尔都语在大型语言模型中代表性不足的问题。现有模型,包括多语言模型和基础LLaMA模型,在处理乌尔都语的复杂性(如形态、文字和文化背景)时表现不佳,导致在乌尔都语特定任务上的性能低下。
核心思路:论文的核心思路是通过持续预训练和指令微调,将一个现有的、性能良好的大型语言模型(LLaMA 3.1 8B)适配到乌尔都语。持续预训练旨在使模型更好地理解和生成乌尔都语,而指令微调则旨在提高模型在特定任务上的性能。
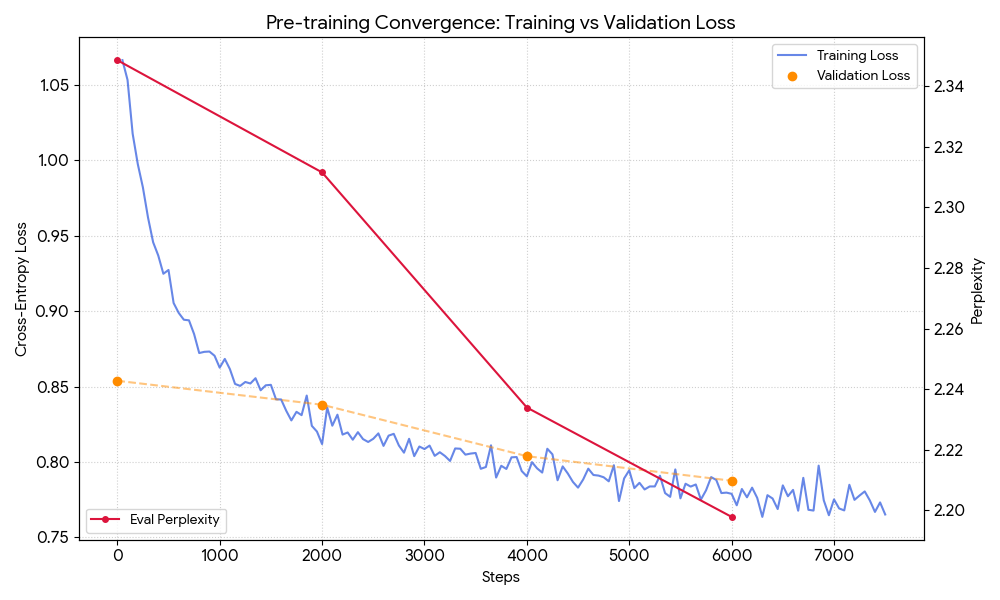
技术框架:Qalb的训练过程包含两个主要阶段:1) 持续预训练:使用包含乌尔都语和少量英语文本的大规模语料库,在LLaMA 3.1 8B模型的基础上进行进一步的预训练。加入少量英文数据是为了防止模型遗忘已有的英文知识。2) 指令微调:使用Alif Urdu-instruct数据集对预训练后的模型进行微调,以提高模型在特定任务上的性能。
关键创新:该论文的关键创新在于针对乌尔都语的系统性持续预训练和指令微调方法。通过构建包含多样化乌尔都语文本的大规模语料库,并结合少量英文数据,有效地提升了模型在乌尔都语任务上的性能。与从头开始训练一个乌尔都语模型相比,这种方法更加高效且资源友好。
关键设计:在持续预训练阶段,使用了包含18.4亿tokens的乌尔都语文本和1.4亿tokens的英文维基百科数据。在指令微调阶段,使用了Alif Urdu-instruct数据集。模型基于LLaMA 3.1 8B架构,并使用了标准的Transformer架构和训练方法。具体的损失函数和优化器等细节可能与LLaMA 3.1 8B保持一致,论文中未明确指出。
🖼️ 关键图片
📊 实验亮点
Qalb在乌尔都语特定基准测试中取得了显著的性能提升,加权平均分达到90.34,超过了之前的最先进模型Alif-1.0-Instruct(87.1)3.24分,同时也超过了基础LLaMA-3.1 8B-Instruct模型44.64分。这一结果表明,持续预训练和指令微调是提升低资源语言模型性能的有效方法。
🎯 应用场景
Qalb的潜在应用领域包括乌尔都语自然语言处理的各个方面,例如机器翻译、文本摘要、情感分析、问答系统和内容生成。该模型可以促进乌尔都语数字内容的发展,并为2.3亿乌尔都语使用者提供更好的语言技术服务。未来,Qalb可以作为乌尔都语自然语言处理研究的基础模型,并促进更多创新应用。
📄 摘要(原文)
Despite remarkable progress in large language models, Urdu-a language spoken by over 230 million people-remains critically underrepresented in modern NLP systems. Existing multilingual models demonstrate poor performance on Urdu-specific tasks, struggling with the language's complex morphology, right-to-left Nastaliq script, and rich literary traditions. Even the base LLaMA-3.1 8B-Instruct model shows limited capability in generating fluent, contextually appropriate Urdu text. We introduce Qalb, an Urdu language model developed through a two-stage approach: continued pre-training followed by supervised fine-tuning. Starting from LLaMA 3.1 8B, we perform continued pre-training on a dataset of 1.97 billion tokens. This corpus comprises 1.84 billion tokens of diverse Urdu text-spanning news archives, classical and contemporary literature, government documents, and social media-combined with 140 million tokens of English Wikipedia data to prevent catastrophic forgetting. We then fine-tune the resulting model on the Alif Urdu-instruct dataset. Through extensive evaluation on Urdu-specific benchmarks, Qalb demonstrates substantial improvements, achieving a weighted average score of 90.34 and outperforming the previous state-of-the-art Alif-1.0-Instruct model (87.1) by 3.24 points, while also surpassing the base LLaMA-3.1 8B-Instruct model by 44.64 points. Qalb achieves state-of-the-art performance with comprehensive evaluation across seven diverse tasks including Classification, Sentiment Analysis, and Reasoning. Our results demonstrate that continued pre-training on diverse, high-quality language data, combined with targeted instruction fine-tuning, effectively adapts foundation models to low-resource languages.