The Confidence Trap: Gender Bias and Predictive Certainty in LLMs
作者: Ahmed Sabir, Markus Kängsepp, Rajesh Sharma
分类: cs.CL, cs.LG
发布日期: 2026-01-12
备注: AAAI 2026 (AISI Track), Oral. Project page: https://bit.ly/4p8OKQD
💡 一句话要点
提出Gender-ECE指标,评估LLM在性别偏见下的置信度校准问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 性别偏见 置信度校准 公平性评估 Gender-ECE
📋 核心要点
- 现有LLM在性别代词解析等任务中存在偏见,且缺乏有效的置信度校准评估方法。
- 论文提出了一种新的校准指标Gender-ECE,用于衡量LLM在性别偏见下的置信度校准程度。
- 实验结果表明,不同LLM在性别偏见校准方面存在显著差异,Gemma-2表现最差。
📝 摘要(中文)
大型语言模型(LLM)在敏感领域的日益普及,引发了人们对其置信度评分与公平性和偏见之间对应关系的关注。本研究考察了LLM预测的置信度与人工标注的偏见判断之间的一致性。研究重点关注性别偏见,调查了涉及性别代词解析的语境中的概率置信度校准。目标是评估基于预测置信度评分的校准指标是否能有效捕捉LLM中与公平性相关的差异。结果表明,在六个最先进的模型中,Gemma-2在性别偏见基准测试中表现出最差的校准效果。这项工作的主要贡献是对LLM置信度校准进行公平性感知评估,为伦理部署提供指导。此外,我们还引入了一种新的校准指标Gender-ECE,旨在衡量解析任务中的性别差异。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理涉及性别代词解析等任务时存在的性别偏见问题。现有的LLM虽然能力强大,但在涉及性别相关的推理时,其预测的置信度往往与实际的准确率不符,即存在置信度校准问题。此外,现有的校准指标难以有效捕捉LLM中与性别偏见相关的差异,无法指导LLM的公平性部署。
核心思路:论文的核心思路是设计一种能够有效衡量LLM在性别偏见下的置信度校准程度的指标。通过分析LLM在不同性别语境下的预测置信度与实际准确率之间的差异,来评估其是否存在性别偏见。核心在于量化这种差异,并将其作为评估LLM公平性的一个重要标准。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建包含性别代词解析任务的数据集;2) 使用不同的LLM对数据集进行预测,并获取其预测的置信度评分;3) 使用传统的校准指标(如ECE)和新提出的Gender-ECE指标对LLM的置信度校准进行评估;4) 分析不同LLM在不同性别语境下的校准表现,并进行比较。
关键创新:论文最重要的技术创新点在于提出了Gender-ECE指标。该指标专门用于衡量LLM在性别偏见下的置信度校准程度。与传统的校准指标相比,Gender-ECE能够更敏感地捕捉LLM在不同性别语境下的表现差异,从而更准确地评估其是否存在性别偏见。本质区别在于,Gender-ECE考虑了性别这一特定因素,而传统指标则忽略了这一因素。
关键设计:Gender-ECE的具体计算方式未知,但可以推测其核心在于将数据集按照性别进行划分,然后分别计算LLM在不同性别子集上的ECE值,并对这些ECE值进行加权平均或差异分析,从而得到最终的Gender-ECE值。具体的加权方式或差异分析方法未知,但需要保证能够有效反映LLM在不同性别语境下的表现差异。
🖼️ 关键图片
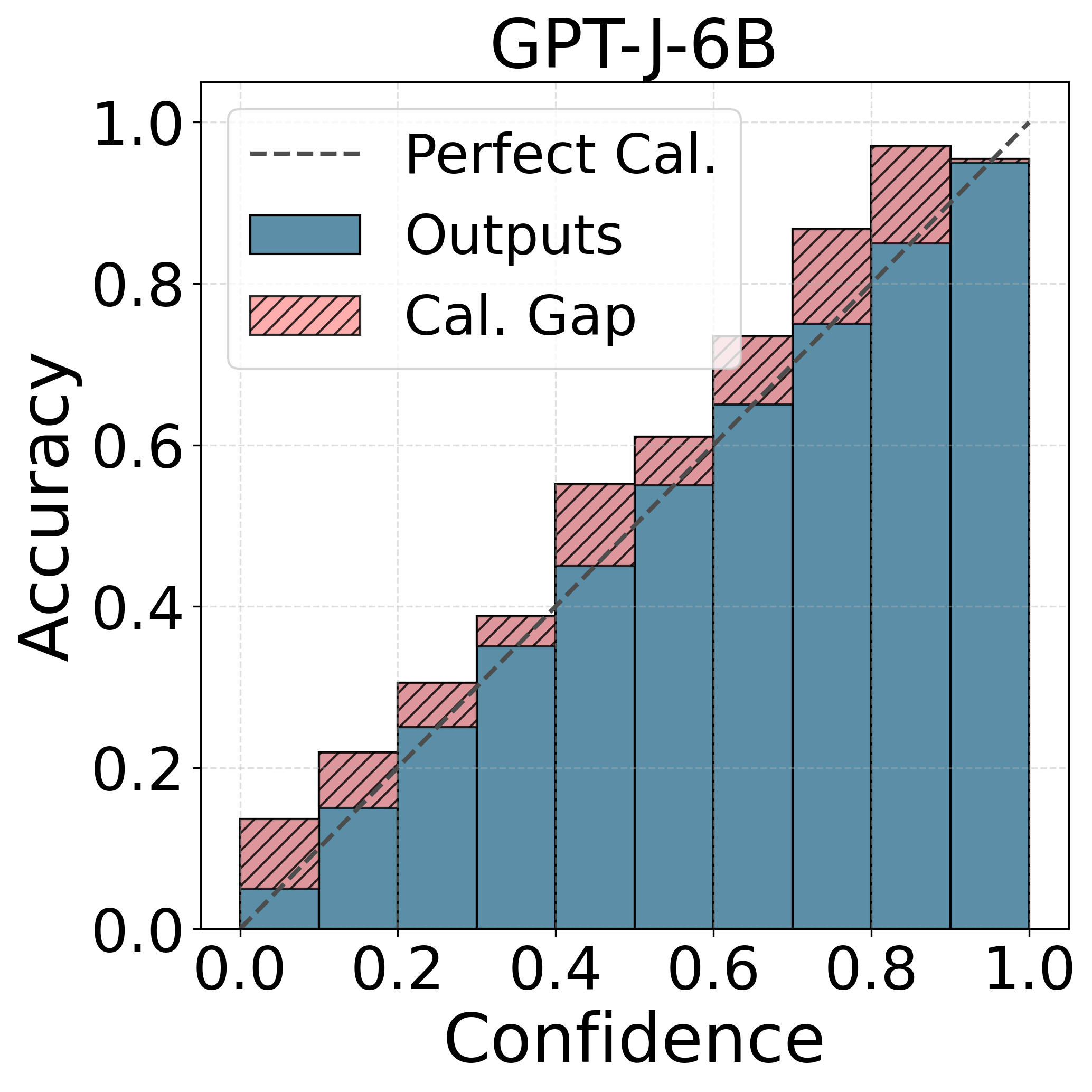
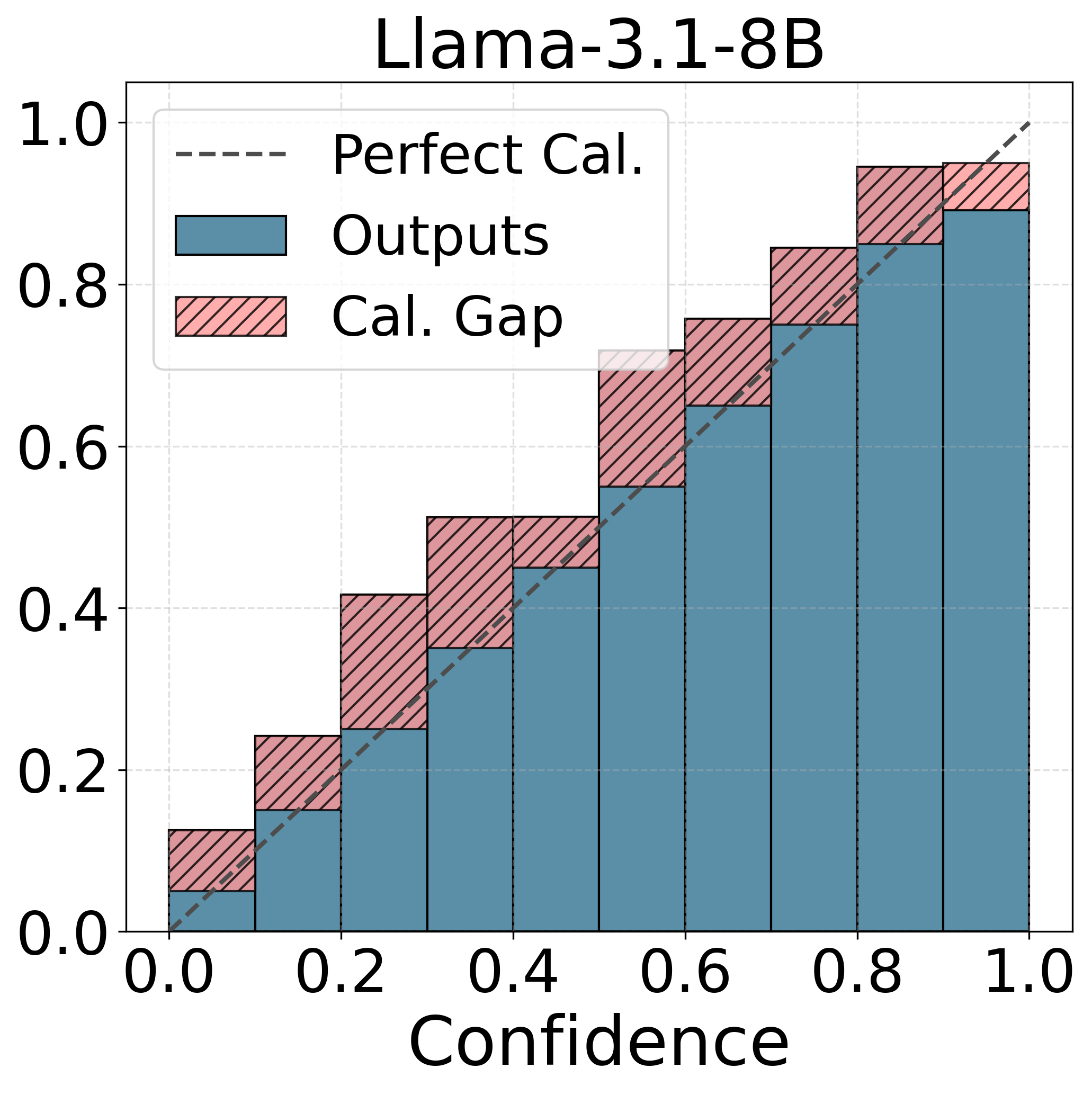
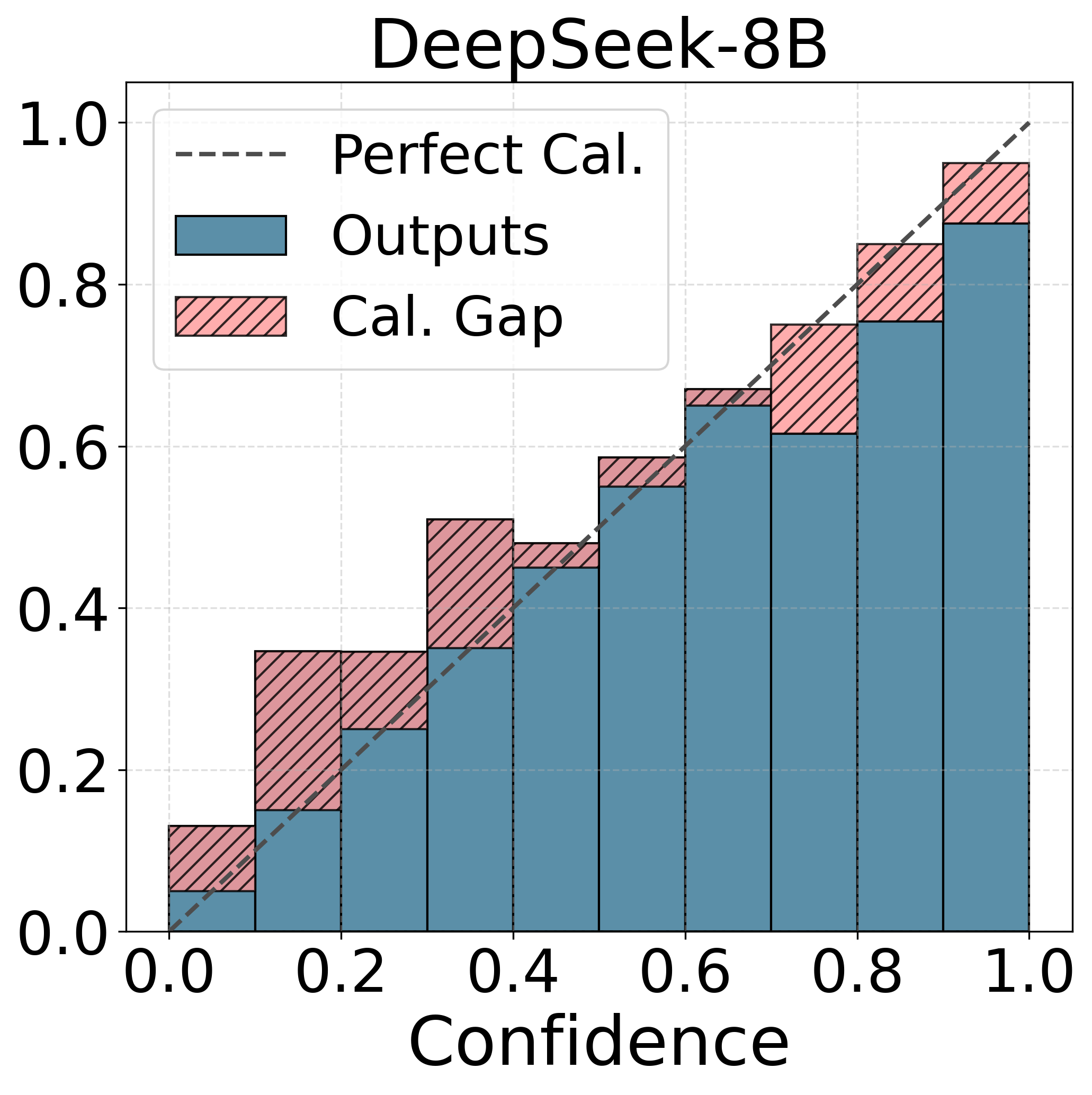
📊 实验亮点
实验结果表明,不同的LLM在性别偏见校准方面存在显著差异。具体而言,Gemma-2模型在性别偏见基准测试中表现出最差的校准效果,表明其在处理性别相关任务时,预测的置信度与实际准确率之间的偏差最大。该发现突显了LLM在公平性方面存在的潜在问题,并强调了进行公平性感知评估的重要性。
🎯 应用场景
该研究成果可应用于对LLM进行公平性评估和改进,尤其是在涉及性别相关的敏感领域,如招聘、信贷评估等。通过使用Gender-ECE指标,可以更好地识别和缓解LLM中的性别偏见,从而促进AI系统的公平性和伦理部署。未来,该方法可以扩展到其他类型的偏见评估,例如种族、年龄等。
📄 摘要(原文)
The increased use of Large Language Models (LLMs) in sensitive domains leads to growing interest in how their confidence scores correspond to fairness and bias. This study examines the alignment between LLM-predicted confidence and human-annotated bias judgments. Focusing on gender bias, the research investigates probability confidence calibration in contexts involving gendered pronoun resolution. The goal is to evaluate if calibration metrics based on predicted confidence scores effectively capture fairness-related disparities in LLMs. The results show that, among the six state-of-the-art models, Gemma-2 demonstrates the worst calibration according to the gender bias benchmark. The primary contribution of this work is a fairness-aware evaluation of LLMs' confidence calibration, offering guidance for ethical deployment. In addition, we introduce a new calibration metric, Gender-ECE, designed to measure gender disparities in resolution tasks.